
人类评估对于验证文本到图像生成模型的性能至关重要,因为这种高度认知的过程需要对文本和图像有深刻的理解。然而,作者对最近37篇论文的调查显示,许多工作完全依赖于自动测量(例如,FID)或执行描述不佳的人工评估,这些评估不可靠或可重复。本文提出了一 种标准化和定义良好的人类评估方案,以促进未来工作中可验证和可重复的人类评估。在本文的试点数据收集中, 通过实验表明,在评估文本到图像生成结果的性能时,当前的自动度量与人类感知不兼容。
来源:CVPR 2023
论文题目:Toward Verifiable and Reproducible Human Evaluation for Text-to-Image Generation
论文链接:https://arxiv.org/abs/2304.01816
论文作者:Mayu Otani,Riku Togashi,Yu Sawai,Ryosuke Ishigami,Yuta Nakashima,Esa Rahtu,Janne Heikkila,Shin’ichi Satoh
内容整理:黄海涛
介绍
近年来,文本到图像的合成有了实质性的发展。已经引入了几个新模型,并取得了显著的成果。尽管许多论文指出了这些测量方法的问题,但大多数研究都使用自动测量方法来验证他们的模型,例如FID分数和CLIPScore。最流行的测量方法FID被批评为与人类感知不一致,比如,图像调整大小和压缩几乎不会降低感知质量,但会导致FID分数的高变化,而CLIPScore可以为经过训练以优化CLIP空间中文本到图像对齐的模型而膨胀。
本文解决了文本到图像生成中缺乏标准化评估的问题。为此,作者仔细设计了一个评估协议,并对协议进行了实证验证。作者用自己的协议评估最先进的生成模型,并提供对收集的人类评级的深入分析。同时还研究了自动测量,即FID和CLIPScore,通过检查测量和人类评估之间的一致性。结果揭示了这两种自动测量的关键局限性。
综上所述,本文的贡献如下:
- 先前人类评估的可靠性值得质疑。文章提供了关于提示和人类评分所需数量的见解,以得出结论。
- FID与人类感知不一致。这至少在经验上是已知的,文章实验也支持这一点。
- CLIP Score已经饱和。就CLIP Scores而言,最先进的生成模型已经与真实图像不相上下。
回顾:在文本生成图像领域的人工评价
文章调查了37篇最近的文本到图像生成论文,并回顾了它们如何使用和报告人工评估。37篇论文中只有20篇提供了人工评估,这意味着17篇论文完全依赖于自动测量。
样本数量和评级
在20篇论文中,有18篇报告了样本数量。然而,只有4篇论文披露了每个样本的数量,尽管对生成图像的评估是高度主观的,而且预计评分会有很大的差异。此外,应当需要对每个样本进行多次标注才能得出结论。
评估标准
生成图像的整体质量和与文本提示的相关性是人类评估的主要关注点,18篇论文评估了整体质量,14篇论文评估文本相关性。其他包括目标位置的正确性和多图像生成的一致性。这意味着一些论文只评估生成图像的单一方面。
评分方法
本文确定了三种不同的方法来收集评级。10篇论文采用比较法,在两个或两个以上的样本中选择最优。9篇论文采用比较法,但需要对多个样本进行排序。3篇论文使用5分或3分的李克特量表进行评级。在不同的论文中,进行人体评估的方式存在很大差异。然而,它们的有效性很少被讨论。
标注质量评估
作者发现一个有问题的做法是不报告标注的质量。一个典型的度量是inter-annotator agreement(IAA),如Cohen’s kappa和Krippendorff’s alpha。没有论文报告IAA,这引起了对结果可靠性的担忧。
薪酬和资格
尽管目前的道德标准建议报告时间投入和报酬的基本统计数据,但大多数论文都没有透露标注者的资质和给予标注者的报酬。
界面设计
标注的用户界面设计提供了高度的自由度,各种选择可能会影响评级。例如,某些界面会使用恒定的图像分辨率,而有些界面会采用不同模型的混合分辨率供用户选择。用户界面的细节通常是不公开的,虽然研究人员经常共享他们的模型代码,但对于人类评估界面来说却不太常见。设计指令、任务和评级选项是至关重要的,需要大量的考虑。缺乏可重复使用的资源阻碍了人类评价协议和实践的不断改进。
文本生成图像的评估设计
评分方式
评分方式主要有比较和绝对两种选择。比较评价,比如对生成的图像进行排名,通常对标注者来说更容易,他们的评分往往是一致的。然而,比较评价需要在所有评价种尝试共享基线模型。至少目前,生成模型的发展速度很快,这可能会使基线在短时间内过时。另一个问题是其有限的可解释性。比较评价只告诉给定一组图像之间的相对优劣,而不关心所有图像之间的优劣。一张图像可以胜出,因为它要么质量高,要么基线较弱。最后,比较评价的结果是模型的相对排名,因此不同评价结果之间的历时比较(或随时间的比较)几乎是不可行的。考虑到这些局限性,本文决定采用绝对评价作为基本评级方法。然而,绝对评价也存在一些挑战,它比比较评估更难,为了质量控制,必须仔细设计说明、问题和选项(标签)。
评价标准
许多先前的工作采用忠诚度(Fidelity)和统一性(Alignment)作为评价标准。忠诚度是指生成的图像与真实照片的相似程度,而统一性是指生成的图像与文本的匹配程度。作者认为这两个标准充分代表了文本到图像生成质量的基本方面,并决定遵循惯例。问题和选项标签的措辞会在很大程度上影响标注者的标注行为。一个常见的轻率之举是只提供端点标签,例如,李克特量表1:最差,5:最好,而其他选项未标记。在数据收集实验中,作者尝试了两个候选设计(图1)来研究具体问题和选项标签的影响。(A)是一个基线任务,其措辞遵循典型的李克特量表标签。(B)更具体地描述问题和选项。为了统一性,(B)使用比(A)更详细的量词来减少主观性。对于忠诚度,(A)要求一般质量并使用一般标签,而(B)要求判断图像看起来是AI生成的还是真实的。

结果,在(A)的情况下,Krippendorff对忠诚度和统一性问题的α分别为0.07和0.18,表明标注者之间的差异很大。另一方面,(B)的忠诚度和统一性分别达到了0.39和0.26。虽然并不令人惊讶,但这些结果成功地证实了更具体的问题和标签会导致明显更好的IAA。
调研候选人
筛选方法基于以下5种标准:
- 成熟度:必须年满18岁,并同意处理攻击性内容
- 经验:完成了5000多个HIT。批准率超过99%
- 地点:位于英语国家
- 技能:通过包含三个简单问题的资格测试,确认具备评估图像质量和基本文字和图像统一性技能
- 学历:表现良好,获得应用数学硕士学位
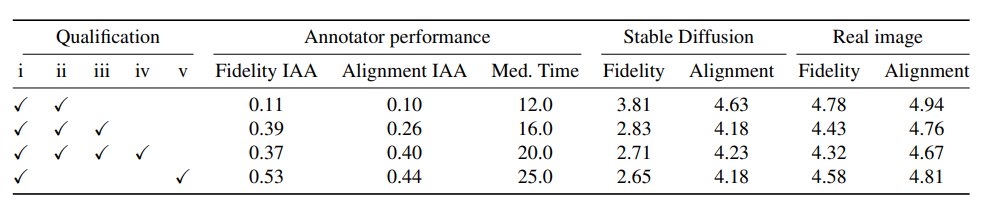
Qualification 4种人选模式。
Annotator performance 是衡量对某个数据集进行标注或评估的一致性的指标。(越接近1表示越一致),而Med.Time是答案时间的中位数。
Stable Diffusion和Real image的值是使用3名回答者对1~5进行评估时计算出的平均值的结果。
通过表1的结果可以观察到,具有成熟度和经验资格的标注者组每个实例花费的时间最短,反映在比其他组低得多的 IAA和更高的生成图像忠诚度得分上,这可能表明这组人注意力不集中。添加位置和技能资格的过滤条件在IAA方面显示出积极的影响,并且标注者需要更多的时间来完成任务。然而,要求更多的资格,特别是技能资格会过度缩小符合条件的标注者数量,延长收集所有标注的时间。AMT Master组靠自己实现了相对较高的IAA,并且不会降低总标注时间,所以在接下来的实验中以此作为标注者主要的过滤条件。
现有模型的人工评价
本文评估了四种文本到图像的生成模型,包括:Lafite,GLIDE,CogView2,Stable Diffusion。
使用的数据集包括:
- COCO数据集(提供图像和每个图像的五个带注释标题的数据集)
- DrawBench(收集了长文本、罕见单词、拼写错误等复杂的文本提示)
- PartiPrompts(用于Prompt学习的大规模自然语言处理数据集)使用该工具,选择五个标题中的一个来生成图像并进行评估。
评价结果
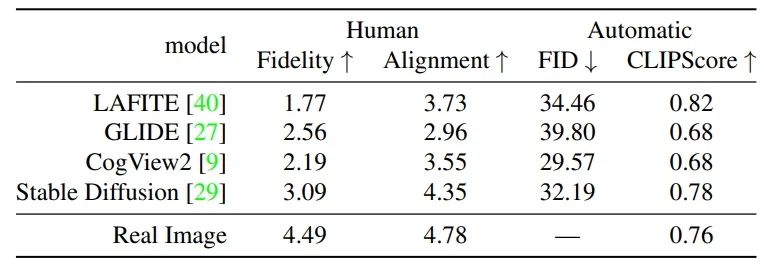
表2总结了在COCO数据集上人类评价的结果。人类标注者在忠诚度和统一性方面优先选择该数据集中的真实图像,Stable Diffusion模型生成的图像排名第二。
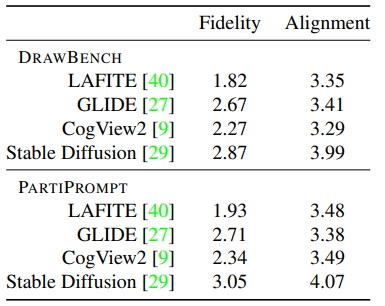
在DrawBench数据集和PartiPrompt数据集上的结果见表3。四个模型在忠诚度度方面的排名与COCO Captions相同。Stable Diffusion模型在这两个数据集上的表现都明显优于其他模型。另一方面,其他模型没有表现出统计学上的显著差异。
自动测量和人类评价的差异
FID
表2显示了FID分数。许多先前的研究报道,FID分数不符合预期质量,本文的人类评估支持这些说法。FID分数将CogView2评为最佳,而人类标记者认为Stable Diffusion在忠诚度方面是四个模型中最好的,CogView2排名第三。图2显示了模型生成的样本。我们观察到CogView2比Stable Diffusion产生更多的伪影。FID分数无法捕获这种不规则纹理。LAFITE和GLIDE的排名在FID分数上和人类评价也不一致。这些结果表明,仅依靠FID分数的忠诚度验证可能导致与人类感知不一致。

CLIPScore
一个最近提出的文本到图像统一性的自动测量。LAFITE和Stable Diffusion的得分高于COCO数据集上的图像和标题对,而人类注释者在统一性方面对真实图像的评分最高,如表2所示。然而,如图3所示,更好的CLIPScore并不一定意味着更好的统一性,分数的大小并不代表图像和文本的一致程度。
Lafite的得分明显高于其他模型。这可能是因为Lafite涉及到基于CLIP的GAN损耗的优化。另一方面,在CLIP空间中,Stable Diffusion在没有优化的情况下给出了更高的分数。然而,CLIPScore并不区分真实图像和Stable Diffusion生成的图像之间的统一性,而人类标注者对真实图像的评价更高。
通过与人类的评价和定性结果的比较,阐明了CLIPScore的局限性。评价指标往往是优化的目标。然而,这种优化会受到对抗效应的影响。另一个问题是,CLIPScore不能区分真实图像和Stable Diffusion生成的图像,而人类标注者能够区分它们。这表明,即使使用真实的文字图像对,CLIP空间中也可能存在空白,这并不奇怪,Stable Diffusion生成的图像已经在这个空白范围内。也就是说,CLIP Score已经饱和,可能不再适用于评估最先进的生成模型。

根据以上的结果,可以得出以下的结论。
- 评价指标经常成为优化的目标(如Lafite)。
- CLIP Score 可以区分人类注释者使用Stable Diffusion生成的图像和实际图像,但无法区分真实图像。
- CLIP在识别立体图像中存在差距。
- CLIP Score 已经饱和,对于最先进的生成模型的评估已经不再有用。
总结
通过实验,本文发现当前的评估指标不足以表达人类的知觉。特别是在FID分数和 Clip Score方面,已经无法对最先进的生成模型进行评估。因此,在今后的研究中,应该不仅仅依赖于机械评估指标,还应该进行人工评估,以提高结论的可信度。
同时在由人类进行评估的时候,也应当需要注意以下事项:
• 报告实验内容以确保透明度。
• 文献提供了注释的详细说明。
• 作为补充资料,报告人类评价设置。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
