
使用基于云的 AI 和 5G 连接能够为各种消费设备提供现场沉浸式体验。体验的关键是观众能够改变他们的内容观点,在云中进行实时渲染。演示侧重于基于对象和人工智能驱动的音频,并带有个性化场景渲染所需的元数据。背景的捕捉对于音频场景的再现也至关重要,为此,团队选择了带有序列化音频定义模型描述性元数据的二阶 Ambisonics。演讲探讨了音频处理和制作的详细方面。总而言之,这是为自由视角 XR 传输 360 度音频所需的技术的迷人一瞥!
目录
- 5G Edge-XR 项目
- 系统流程图
- 音频系统需要什么
- 云上 AI 混音
- Ambisonics
- 5G Edge-XR 声音系统
- AI 混音软件—— MIXaiR
- 应用——拳击赛场
5G Edge-XR 项目
5G Edge-XR 项目的目标是探索 5G 和 edge-GPU 计算如何提高扩展现实(XR)体验的。
5G 具有很多适用于 XR 体验的优点。
- 高速性,因此可以发送超高分辨率到用户终端;
- 低延迟特性,能够更好的提升体验质量;
- 大容量特性,使得我们可以同时连接很多设备
在 Edge-GPU 上进行处理计算有很多优点:
- 往返延迟更低;
- 更快的光子运动带来更好的质量体验,所以我们可以利用光线追踪大气效果和一些非常酷的效果;
- 更高的保真度,需要的压缩优化更少;
- 在设备上启动更快,流传输,不必等待下载;
- 延长电池寿命,在边缘而不是在设备上进行处理,无需设备本身进行所有处理,基本上只是视频和音频流的查看器;
- 更好、更一致的质量体验,无关内容,当我们获得稳定的比特率时,它将获得更好的体验。
系统流程图
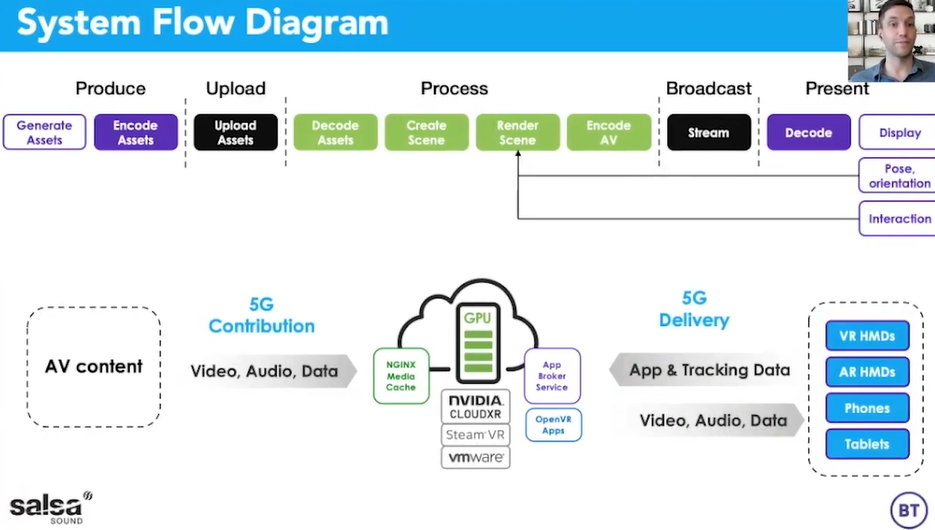
主要包括 2 路通信,一路用于生产、贡献 AV 内容,通过 5G 进行传输发送到云服务器,然后在该场景上创建用户特定的视点,然后将相应的 AV 资产流回最终用户设备以获得他们的个人体验来进行交互。有一些非常酷的用例,其一是田径运动,在这种情况下,我们有一个3D 地图,上面有各种媒体资产,还可以调出不同的统计数据。如果你有 AR 眼镜或者用平板电脑或手机作为一个窗口来观察那个场景,可以选择观看选项和体育场用例之类的东西。比如用手机作为场景的窗口,或者使用 AR 眼镜,可以看到叠加 3D 资产类型的标签和播放线额外的统计数据,这些会增强体育场的体验。

在 5G 以上可以方便地进行观看,获得 360° 全景,也可以选择自己地观看视角,哪几个不同的相机。
 你可以将想买的车粘在你的车道上,还可以添加或者删除不同的功能,获得现实感的体验。
你可以将想买的车粘在你的车道上,还可以添加或者删除不同的功能,获得现实感的体验。
 这同样适用于医疗,你可以观看一些医学扫描数据。
这同样适用于医疗,你可以观看一些医学扫描数据。

另外可以提供全息舞蹈课体验,以体积度量的方式捕获,因此可以观看舞蹈老师的动作,看看他们是如何表演这些动作的,有助于帮助人更好的学习欣赏,这种远程课程可以获得良好的课程体验。

可以实现浓缩现实、制作体积视频的过程,用户可以自定义自己的观看位置,甚至可以把它放在咖啡桌上。通过AR眼镜查看它,真正了解拳击比赛的进展情况。另外每个人都可以获得个性化的体验,调出不同的统计数据和额外的屏幕内容,甚至可以调整音频。我们正在进行沉浸式音频捕获,音频系统是必不可少的。
音频系统需要什么
我们希望看到的是 AI 聪明地讲故事,所以你需要一个好的剧本,需要一个好的故事情节,但是同时你也需要一部好电影的精彩配乐,比如球场上如果没有声音,观众就会错过故事的一部分。因此 XR 体验必须具备音频系统,音频系统需要具备以下特性:
- 音频需要身临其境的;
- 需要自适应的;
- 需要个性化的,用户可以根据个人需求进行调整;
- 需要自动化的,生产者不可能为每个人制作不同的混音,因此实际过程中,音频系统必须是自动化的;
我们已经通过使用人工智能来创建球场上的声音来解决这个问题,为了能够获得更好的体验,我们还需要身临其境的人群元素,将多种不同的声音进行混合,这样你可以坐在人群的不同部分,来体验不同角度的声音。我们还需要注意在广播中非常重要的响度规定,我们不要让事情变得太大声或太安静。
当然,理想情况下,这些规则是我们需要注意的,但是也要求我们做一些有点不同的事情,不能完全使用基于标准渠道的范式,我们期望一种基于对象的方法,能够为不同的产品生产不同的组合。基于通道的方法难以实现真正的个性化、不能完全实现自适应,沉浸感是有限的。而基于对象的方法可以获得更好的体验。
云上 AI 混音
我们用 AI 解决了上述提出的音频问题,提出了一个通用标准型,音频流程图如图所示。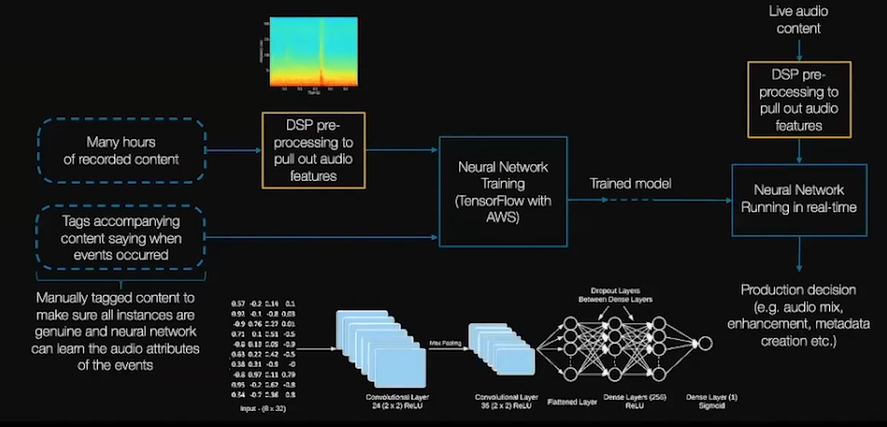
以许多小时的录制内容作为输入,用 DSP 预处理器来进行处理,生成音频特征,并附带内容的标签说明事件发生的时间来输入神经网络进行训练,以生成一个模型,以便当我们放置实时内容时,该模型可以实现自动对其进行分类。
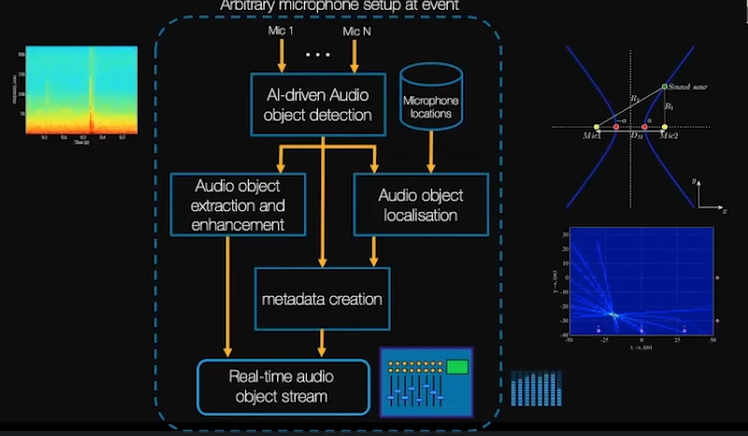 使用现场周围所有不同的传感器、麦克风进行测量来找出这些事件实际发生的地方,并将其与对象提取相结合创建元数据。对于人群声音,个性化很重要,同时它对适配器可定制的搜索令人印象深刻,当你旋转时,人群应该以现实的方式旋转。就好像你真的在那里。所以我们通过空间音频麦克风来促进这一点,创建多个不同区域的的对象流。
使用现场周围所有不同的传感器、麦克风进行测量来找出这些事件实际发生的地方,并将其与对象提取相结合创建元数据。对于人群声音,个性化很重要,同时它对适配器可定制的搜索令人印象深刻,当你旋转时,人群应该以现实的方式旋转。就好像你真的在那里。所以我们通过空间音频麦克风来促进这一点,创建多个不同区域的的对象流。
Ambisonics
我们选择了 Ambisonics 方法来进行处理,这是一种在空间环境中描述声场的方式。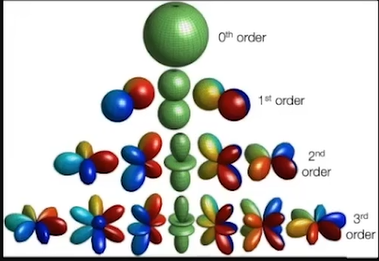 他能够旋转来匹配方向,能够在不同形式之间进行转换,很容易进行记录,能够给予精确的空间描述并有效处理。
他能够旋转来匹配方向,能够在不同形式之间进行转换,很容易进行记录,能够给予精确的空间描述并有效处理。
5G Edge-XR 声音系统
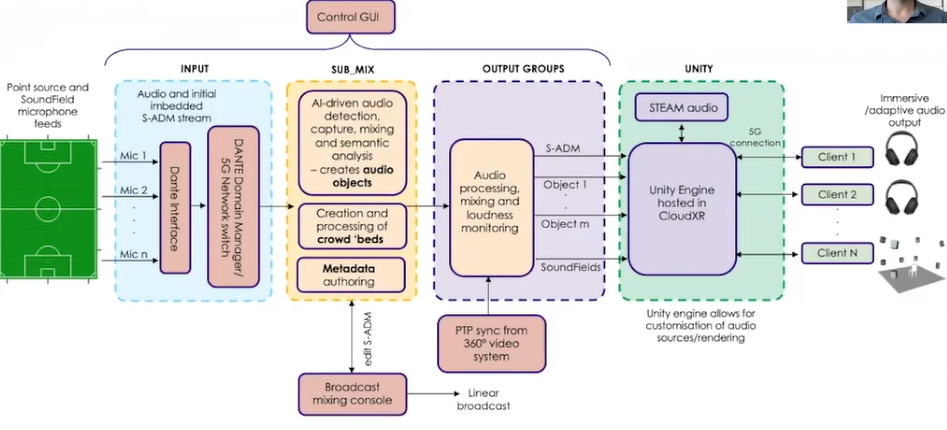
上述是项目示意图。我们在活动中使用了标准的传感器麦克风。这些将通过 5G 网络与混音接口。分成3个不同的部分:输入、子混合、输出模块。在输入部分提取音频对象,在子混合部分利用人工智能来生成元数据,在输出部分进行更多的音频处理,动态控制混合响度。
现在输出是最困难的部分是将其流式传输到 Unity 引擎中,这是一个非常重要的问题。但是我们已经开发了一些简单的音频渲染方案。因此,我们可以将多通道流输入到 Unity 中,并管理这些音频资产。因此当客户端将他与 VM 连接时,他们能够得到定制的音频演示。这一切都是通过 PTP 与 360 度视频系统进行的,我们还与广播控制台连接,如果需要,可以更改不同的属性。
AI 混音软件—— MIXaiR
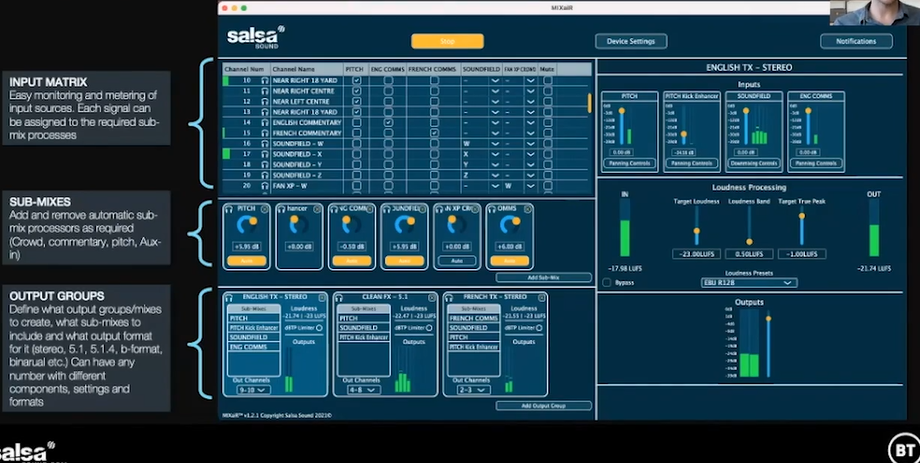
上图展示了混音软件的视图,左上角是输入矩阵,它定义了音频通道,每个信号都可以分配到所需的子混音过程。
应用——拳击赛场
我们将其应用到了拳击赛场,在不同位置放置了几个不同的麦克风。这样就可以捕捉到非常酷的东西、身临其境的人群声音,或者我们可以旋转它来匹配体积视频演示,以获得真正身临其境的体验。同时我们要有能力添加、删除或改变不同国家的不同语言,人们可以实现个性化并真正改变音频。
来源:IBC Digtital 2021
主讲人:Rob Oldfield
内容整理:张雨虹
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
