
视频超分辨率(VSR)旨在利用低分辨率帧内的互补时间信息来恢复高分辨率帧序列。然而,目前大多数的 VSR 方法通常针对特定的压缩方式,实验设置与实际应用之间的性能差距很大,不能自适应地处理各种不同的压缩级别。此外,比特流中编码的丰富元数据可以使超分辨率过程受益,但还尚未得到充分利用。基于此,本文提出了一种压缩感知的视频超分辨率模型,具体贡献如下:
- 提出了一种用于感知帧压缩级别的压缩编码器。该方法使用基于排序的损失进行监督,并使用计算得到的压缩表示来调制基本 VSR 模型。
- 在时空信息融合过程中充分挖掘压缩视频自带的元数据,增强基于 RNN 的双向 VSR 模型的功能。
- 大量的实验证明了所提出的方法在压缩 VSR 基准上的有效性和效率。
作者设计了压缩编码器模块,利用压缩视频的元数据隐式建模压缩级别,它还将在计算压缩表示时同时考虑帧及其帧类型。然后,通过插入压缩感知模块,一个基于双向循环的基本 VSR 模型可以基于压缩级别自适应地处理不同压缩级别的视频。为了进一步增强基础 VSR 模型的功能,作者进一步利用了元数据。在双向循环网络中,利用运动矢量和残差映射实现不同时间步长之间快速准确的对齐,并再次利用帧类型更新隐藏状态。
模型结构
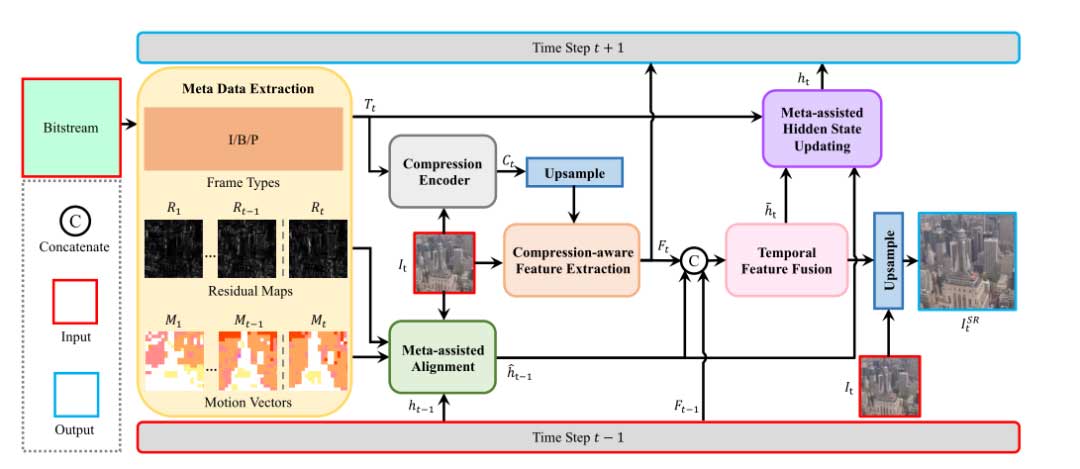
CAVSR 模型的整体框架如上图:从比特流元数据中提取帧类型、运动向量和残差映射。这些额外的信息将被压缩编码器处理以对当前帧的特征进行上采样。元辅助对齐模块利用运动矢量和残差映射,将前一帧的信息聚合,并通过时间特征融合模块将其与当前帧的 SR 特征融合。最后,通过上采样解码器得到 SR 结果。利用当前帧的元数据和聚合 SR 特征更新隐藏状态,辅助下一帧的 SR 处理。下面将具体介绍各个关键模块。
压缩编码器
为了使 VSR 模型适应各种压缩,设计了一个压缩编码器来隐式地模拟视频帧中的压缩级别,同时考虑帧类的型和压缩感知质量(CRF)。在本工作中,压缩表示学习被视为学习排序任务。
具体来说,视频帧对在压缩方面有两种准备方式。一个子集由具有相同 CRF 但帧类型不同的帧对组成,另一个子集由具有相同帧类型但 CRF 不同的帧对组成。压缩编码器从前一个子集中学习不同帧类型的压缩水平,从后一个子集中学习区分不同 CRF 的压缩级别。
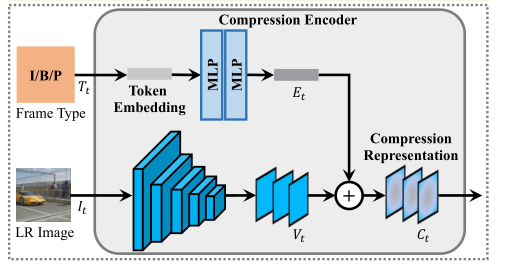
网络包括两个输入支路,即帧类型支路和帧内容支路。对于帧类型分支,为每个帧类型分配一个向量,并使用令牌嵌入来表示该信息。对于帧内容分支,从视频编解码器解码的帧被馈送到几个卷积层。将来自帧内容分支的特征映射和来自帧类型分支的令牌嵌入组合为该帧的压缩表示,记为Ct。
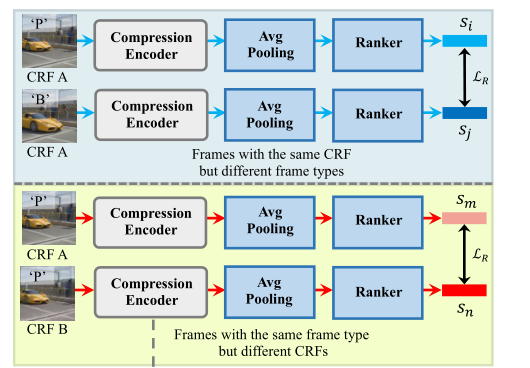
学习过程为:将一对帧和它们的帧类型输入到一个类似暹罗的架构,通过共享的压缩编码器获得一对压缩表示,并在几个共享的排序层之后进一步计算两个低分辨率帧的排序分数 s。为方便起见,根据压缩量对每种帧类型{I, P, B}定义分数 Qf ={0,1,2},对不同压缩系数定义另一个分数 Qc = CRF 值。排序损失定义如下:
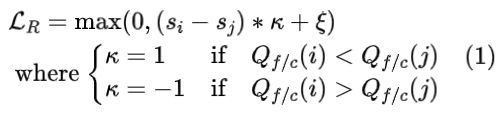
其中 κ 表示帧对之间的顺序真值,ξ 取 0.5,根据帧对所在的子集选择 Qf 或 Qc。
压缩感知特征提取
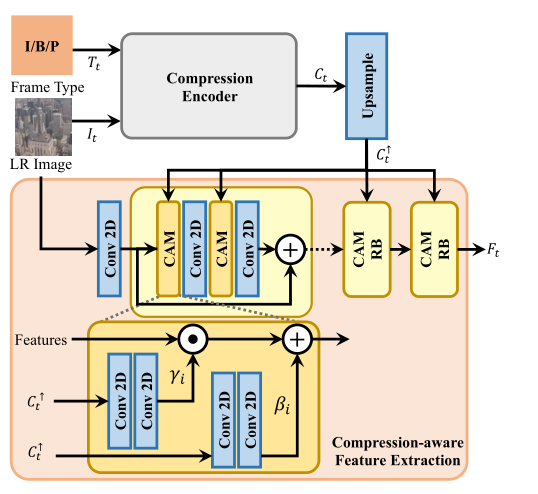
利用计算得到的压缩表示调制基本 VSR 模型。基本 VSR 模型的特征提取部分由多个卷积层和残差块组成。本文在特征提取过程的每个卷积层之前插入一个简单的压缩感知调制(CAM)模块,该调制被实例化为仿射变换,其参数 γi 和 βi 根据压缩表示在空间上自适应计算:
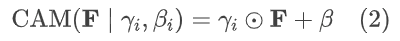
元数据辅助对齐
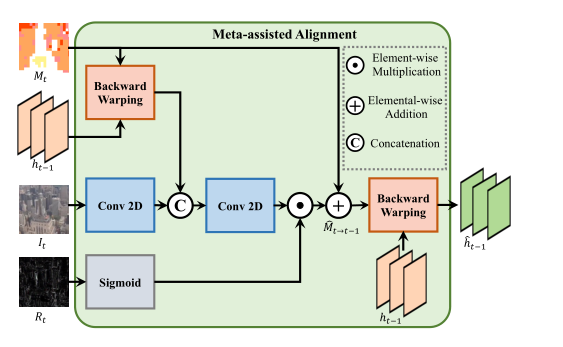
运动补偿在 VSR 过程中起着关键作用。光流估计的运算量较大,直接将运动向量(MV)作为光流的替代方案又无法达到最优效果,因为它们在视频编解码器中是按块计算的。因此,本文在对齐过程中充分利用了压缩视频自然产生的两种额外元数据,即运动向量和残差映射。
将 MV 作为初始偏移量,并借助输入帧和残差映射对其进行进一步细化。在时间特征融合阶段,利用估计的运动信息将隐藏状态对齐到当前时间步长,然后将扭曲的隐藏状态表示与帧特征结合计算残差偏移。最后的运动信息为初始 M 与估计的残差偏移之和。
元数据辅助传播
由于 B 帧中的内容被严重压缩,为该帧计算的隐藏状态可能比其他帧包含更少的信息,因此随着时间的推移,在传播过程中导致性能下降。为了改善这个问题,将 B 帧的隐藏状态更新为与前一帧(通过 MV 与当前时间步长 t 对齐后)的加权平均,这里 α 取 0.5 :
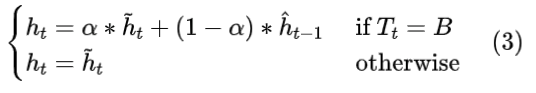
实验
实施细节
数据集
- 训练集:Vimeo-90k。首先用标准差为 1.5 的高斯核平滑 HR 帧,并按 4 的比例下采样,然后使用 H.264 编码器与 FFmpeg 4.3 生成压缩视频。将 CRF 设置为 0、15、25 和 35。
- 测试集:Vid4,使用与 Vimeo-90K 相同的下采样和压缩方法。用 YCbCr 空间 Y 信道的 PSNR 和 SSIM 对 SR 结果进行评价。
训练设置
使用 5 个压缩感知调制残差块(CAMRB)用于压缩感知特征提取,25 个残差块用于时间特征融合。训练时的 batch size 和 patch size 分别设置为 16 和 64 × 64。在训练过程中,还使用随机旋转、翻转和时间反向操作作为数据增强技术,以避免过拟合。实验中,设置 ξ = 0.5和 α = 0.5。
整个网络分为两个阶段进行训练,分别使用 β1 = 0.9 的余弦退火方案和 β1 = 0.999 的 Adam 优化器。在第一阶段,进行 100K 次迭代来训练压缩编码器和排序器,初始学习率设置为 1e−4。在第二阶段,冻结压缩编码器并训练由 Charbonnier 惩罚损失函数监督的复位部分,初始学习率设置为1e−4。总迭代次数为 400K。在训练过程中,CRF0 视频和 CRF15/25/35 的压缩视频以 0.5 的概率随机馈送到 VSR 模型。所有实验都是在带有 V100 gpu 的服务器上使用 PyTorch 实现的。
SOTA工作对比
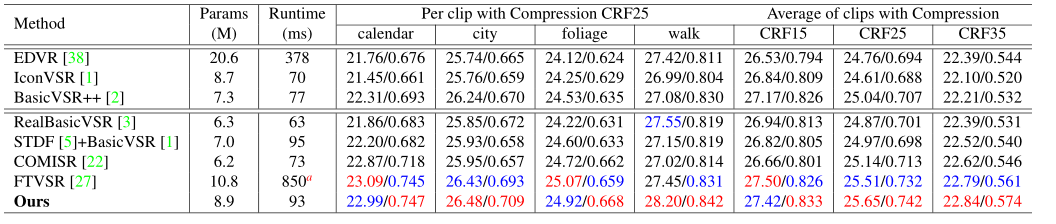
与几种最先进的 VSR 方法进行比较,包括:EDVR, IconVSR, BasicVSR++, RealBasicVSR, STDF + BasicVSR, COMISR, FTVSR。前三种方法是最初提出的用于处理理想退化的 VSR 方法,例如双三次或高斯双三次。后四种是处理压缩视频的方法。本文的方法在 PSNR 和 SSIM 上都优于以前的大多数 VSR 方法。该方法的性能与最新的 FTVSR 模型相当,但 FTVSR 模型的尺寸更大,速度也要慢得多。
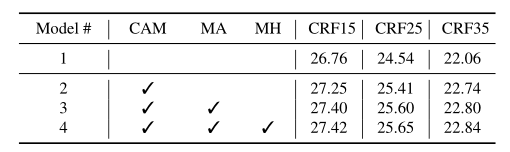
消融实验
采用 BasicVSR 框架作为基准(模型 1),随着压缩感知模块(模型 2),元辅助对齐模块(模型 3),元辅助传播模块(模型 4)的加入,性能不断提高,证明了压缩感知设计和元数据利用的有效性。
来源:CVPR 2023
论文题目:Compression-Aware Video Super-Resolution
作者:Yingwei Wang,Takashi Isobe,Xu Jia,Xin Tao,Huchuan Lu, Yu-Wing Tai
链接:https://github.com/aprBlue/CAVSR
内容整理:王妍
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
