
本文综合利用基于图像的渲染和神经辐射场两种方法的思想,提出了一种基于学习的根据多个源视角图像进行连续场景辐射以合成新视角图像的方法。
自由视角合成任务需要根据已有的多视角场景图像合成出新视角下的场景图像。早期的工作多为基于图像的渲染方法。此类方法通过对源图像进行映射、重采样以及混合等操作合成出目标视角下的图像,同时对输入视角的稠密程度有着较高要求,否则会产生较为严重的伪影。近年来,基于神经场景表征的自由视角合成方法在神经辐射场这一概念的提出之后迅速地发展了起来。但这一方法本身并不具有泛化能力,在接触到新场景时,该方法需要较长时间进行场景表征的学习过程,进而在实际应用方面具有较大限制。
本文的工作综合利用基于图像的渲染和神经辐射场两种方法的思想,提出了一种基于学习的根据多个源视角图像进行连续场景辐射以合成新视角图像的方法。具体来说,本文所提出的框架可以看作为一个具有泛化能力的视图插值函数,其对场景中不同位置的密度、遮挡关系、颜色等属性进行推理,并进行光线的渲染。这一算法框架可以高质量地合成出学习过程中未出现的新场景自由视图像。
总的来说,本文的主要贡献有:
- 提出了一种新颖的基于学习的多视角图像渲染方法,超越了现有的在新场景上具有视角合成泛化能力的方法
- 提出了一种名为 IBRNet 的新颖模型结构,可以通过多个视角下的图像预测出空间中的密度和颜色信息
- 在逐场景优化方面与仅针对单场景推理的方法具有可比的性能效果
算法介绍
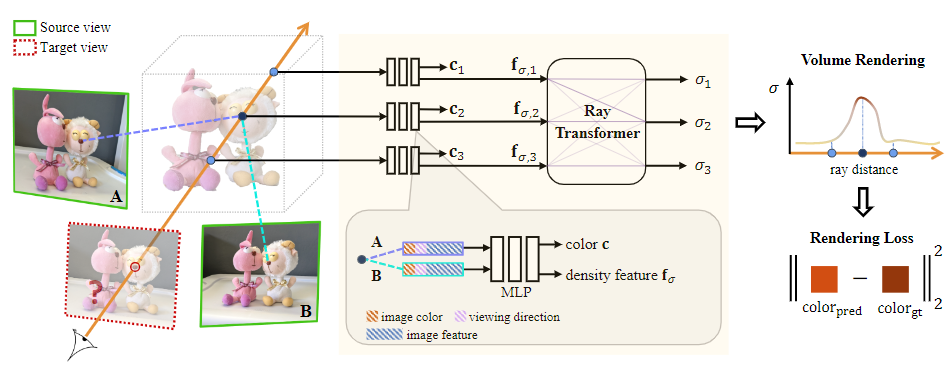
本文所提出的算法可以在给定场景源视角图像及相机参数的基础上通过体渲染合成出新视角下的场景目标图像。具体来说,本文中所提出的算法所解决的核心问题就是通过集成整合源视角图像中的信息从而获得连续空间中的颜色和密度值。算法的整体流程如图 1 所示,分为三个部分:
- 选择最邻近的源视角图像作为输入,并对每个源视角图像进行特征提取
- 预测空间中连续五维坐标对应的密度值和颜色
- 沿相机光线通过体渲染合成对应像素的颜色和密度值,合成得到新视角下的图像
视角选择与特征提取
为了使得模型对新场景具有泛化能力,本文中所提出的模型并不像 NeRF 一样对场景进行编码,而是对学习从源视角图像推理出空间中某一位置对应的颜色和密度值。为了适应不同的环境和应用需要,本文中所提出的算法可以适应任意数目的不同视角下的图像输入,输入图像数目的增多意味着所提供的场景信息越多,最终的合成效果越好,但所需要的计算资源和空间也就越多。为了在满足 GPU 存储的限制下提升新视角图像的合成速率,本文中的算法首先选择与目标视角方向最近的 个视角下的图像作为参考图像,并使用 U-net 网络作为特征提取网络得到每个图像对应的相同大小的特征图,其中每个像素对应一条代表局部纹理信息的特征向量。
颜色和密度值的预测
根据已有的 个视角的参考图像和对应的特征矩阵,本文设计了 IBRNet 网络结构以根据参考图像中的信息推理出场景中某一位置的颜色和密度值信息。具体来说,在颜色和密度值推理预测时, IBRNet 的模型结构如图 2 所示。
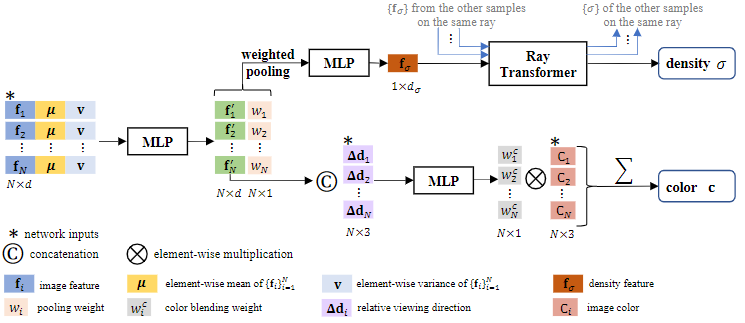
在日常生活中可以发现,当空间中某一点在物体表面时,该点在不同视角下观察时对应纹理和几何特征都较为相似,而其余点在不同视角下观察时则可能有较大差别。利用这一特性,本文首先计算不同参考视角下三维空间位置所对应的像素特征的逐元素平均向量和不同视角与平均向量间的标准差向量,以表征某一三维点在不同视角下观察到的整体情况以及每个视角与整体特征间的差别。将不同视角下的特征、全局平均特征和方差向量级联后,本文中的方法通过多层感知机整合这一向量进行感知降维,并判断每个视角对该三维点的贡献,通过输出的权重将不同视角下的整合特征池化为每个三维点对应的唯一特征。
在体密度推理阶段,为了增强空间内不同位置处三维点间的联系,使得模型能够对场景中的几何关系进行整体感知,本文使用经典的 Transformer 结构对同一相机像素光线上的三维点进行综合感知,通过位置编码区分三维点在光线上的前后位置,通过自注意机制对不同的三维点的体密度特征进行融合,最终通过前馈网络输出三维点对应的体密度值。
在计算不同参考视角下对应三维空间点像素特征的全局特征时,由于在不同的相机视角下可能选择的参考视角图像不同,因此如果对不同的视角图像赋予相同权重则在生成视角移动的视频时,可能会出现跳变的伪影。因此,本文对与目标视角方向更为接近的参考视角给予更大的权重,并根据视角分布情况对视角的权重进行具体计算。
在颜色推理阶段,将前述经过多层感知机感知压缩获得的特征与该参考视角及目标视角间的方向差进行级联,输入后续的多层感知机中得到每个视角对应的颜色权重。使用该颜色权重与参考视角对应的像素颜色进行混合即得到了该三维空间点的颜色。
体渲染与训练策略
在已知空间中三维点的颜色和体密度值后,使用体渲染公式根据光线上三维点的体密度值计算目标视角下该光线对应像素的颜色,并以此渲染输出全部图像。在训练过程中,为了提升模型的训练和推理速度,本文使用了分层采样策略,先对三维空间进行粗均匀采样以获得场景的大致几何分布,再针对体密度值较大的区域进行细采样从而在尽可能保证模型输出质量的同时提高模型的输出效率。
实验结果
本文中的方法使用了虚拟合成数据集和真实的拍摄数据集进行训练,包括 Google Scanned Objects、RealEstate10K、the Spaces dataset、LLFF 以及本文作者自行拍摄的数据。在实验结果的对比方面,本文选择 LLFF 算法进行对比以比较模型的泛化能力,与 SRN、NV、NeRF 三种算法进行对比以评价模型在单个场景重建时的效果。实验得到对比数据如图 3 中的表格所示,主观性能对比图如图 4 中所示。
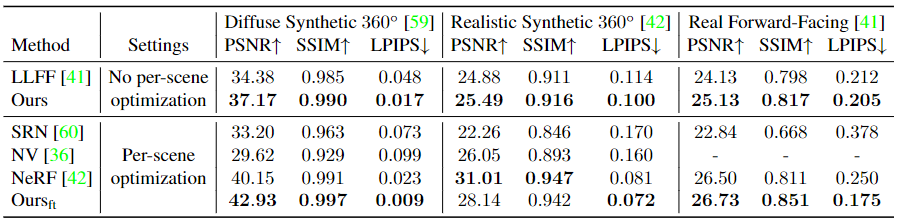

从实验中可以看出,本文中所提出的算法相比较于其他方法具有较好的泛化能力,可以对新场景进行快速自由视角合成任务,并具有较高合成质量。同时,在单场景的重建质量方面,该算法经过短时间微调模型得到的结果即可与经过长时间训练的其他模型具有相当程度的可比性。在主观感受方面,该方法考虑了图像局部范围的整体纹理特点,相比于其他方法产生的噪声更少,图像边缘更为尖锐平滑,主观感受更好。
作者:Qianqian Wang, Zhicheng Wang 等
来源:CVPR 2021
论文题目:IBRNet: Learning Multi-View Image-Based Rendering
内容整理:王秋文
论文链接:https://arxiv.org/abs/2102.13090
项目链接:https://ibrnet.github.io/
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
