
本文研究如何使用预训练的图像扩散模型进行文本引导的视频编辑。提出了一种免训练的方法,并且可以推广到广泛的编辑中。并且通过大量实验证明了该方法的有效性,并将其与四种不同的先前和并行工作(在ArXiv上)进行了比较。本文证明了现实的文本引导的视频编辑是可能的,不需要任何计算密集型的预处理或视频个性化的微调。
来源:ICCV 2023
题目:Pix2Video: Video Editing using Image Diffusion
项目地址:https://github.com/duyguceylan/pix2video
论文地址:https://arxiv.org/abs/2303.12688
作者:Duygu Ceylan, Chun-Hao P. Huang等
内容整理:王寒
简介
在大量图像集合上训练的图像扩散模型,在质量和多样性方面已经成为最通用的图像生成器模型。它们支持反演真实图像和条件(例如,文本)生成,使其在高质量图像编辑应用中非常受欢迎。本文研究如何使用这些预训练的图像模型进行文本引导的视频编辑。关键的挑战是在实现目标编辑的同时仍然保留源视频的内容。本文的方法通过两个简单的步骤来工作:首先,使用预训练的结构引导的(例如,深度)图像扩散模型在锚框上进行文本引导的编辑;然后,在关键步骤中,通过自注意力特征注入将变化逐步传播到未来帧,以适应扩散模型的核心去噪步骤。然后,通过调整框架的潜在编码来巩固这些变化,然后再继续这个过程。
算法细节
给定一个视频片段的帧序列 I = I1,…,In,希望生成一组新的图像:I’ = I’1,…,I’n他们之间的关系是一个由目标文本提示P’表示的编辑。例如,给定一辆汽车的视频,用户可能希望生成一个编辑的视频,其中汽车的属性(如颜色)被编辑。本文的目标是利用预训练和固定的大规模图像扩散模型的力量来尽可能连贯地执行这些操作,而不需要任何针对特定示例的微调或广泛的训练。本文通过操纵扩散模型的内部特征以及额外的引导约束来实现这一目标。给定固定的图像生成模型进行训练,由于只有单幅图像,无法对输入视频中发生的动力学和几何变化进行推理。结合近年来各种结构线索条件化图像生成模型的进展,观察到这种额外的结构通道在捕捉运动动态方面是有效的。因此,本文在深度条件稳定扩散模型上建立了我们的方法。给定I,执行每帧深度预测,并将其作为模型的额外输入。
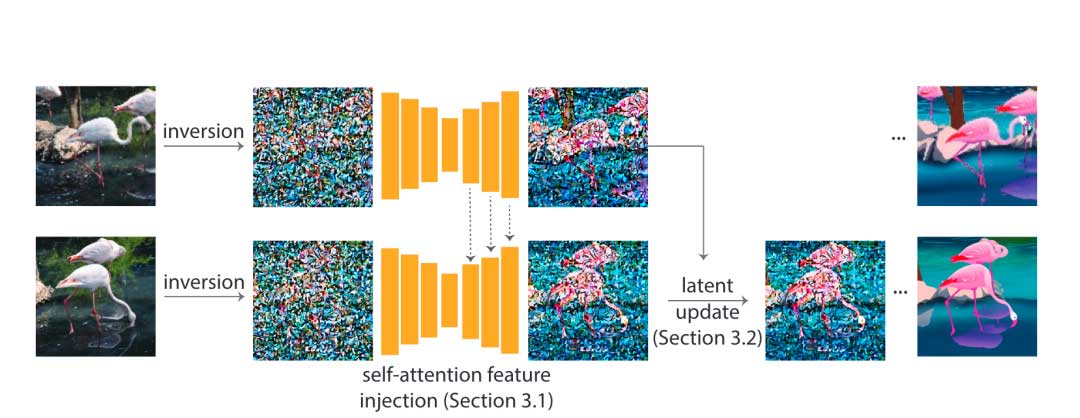
自注意力特征注入
在静态图像的背景下,大规模图像生成扩散模型通常由残差、自注意力和交叉注意力块组成的U-Net架构组成。交叉注意力块有助于实现对文本提示的忠实性,自注意力层有助于确定图像的整体结构和外观。在每个扩散步骤t,输入特征flt到第l层的自注意力模块,分别通过矩阵WQ,WK和WV投影,得到Ql,Kl和Vl,然后计算注意力块的输出为:

通过这样的特征注入,当前帧能够利用前一帧的上下文,从而保留外观变化。一个自然的问题是,是否可以使用一个显式的、潜在的循环模块来融合和表示前一帧特征的状态,而不需要显式地关注某个特定的帧。然而,这样一个模块的设计和训练并不是微不足道的。相反,我们依赖于预训练的图像生成模型隐式地执行这种融合。对于每一帧i,我们注入从帧i-1中获得的特征。由于编辑是以逐帧的方式进行的,i-1帧的特征需要通过i-2来计算。因此,本文提出一种隐式的方式来聚合特征状态。我妈证明了虽然关注前一帧有助于保持外观,但在更长的序列中,它显示了减少编辑的局限性。加入一个额外的锚框,通过提供对外观的全局约束来避免这种遗忘行为。因此,在每个自注意力块中,本文将a帧和i – 1帧的特征进行串联,以计算键值对。在本文的实验中,我们设定a = 1,即第一帧。
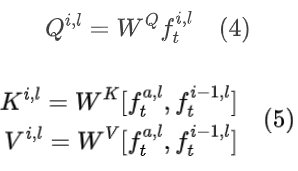
在UNet的解码器层中执行上述特征注入,发现其在保持外观一致性方面是有效的。解码器的更深层捕获了高分辨率和外观相关的信息,并且已经产生了具有相似外观但结构变化很小的帧。在解码器的早期层进行特征注入可以使我们避免这种高频结构变化。当在UNet的编码器中注入特征时,没有观察到进一步显著的好处,并且在一些例子中观察到了轻微的伪影。
引导潜在更新
虽然自注意力特征注入有效地生成了具有连贯外观的帧,但它仍然会遭受时间闪烁的影响。为了提高算法的时间稳定性,本文在每个扩散步骤中沿分类器指导线使用额外的指导来更新隐变量。为了执行这样的更新,首先建立了一个能量函数来增强一致性。稳定扩散和许多其他的大规模图像扩散模型一样,是一个去噪扩散隐式模型( DDIM ),其中在每个扩散步骤中,给定一个有噪声的样本xt,沿着xt指向的方向计算无噪声样本(x0)的预测。形式上,xt-1的最终预测是由图2中的公式决定的



最后,用于编辑每一帧的初始噪声也会显著影响生成结果的时间一致性。我们使用一种反演机制,DDIM反演,而其他旨在保持图像可编辑性的反演方法也可以使用。为了得到用于反演的源提示符,我们使用字幕模型为视频的第一帧生成一个字幕。上图算法中给出了本文方法的整体步骤。
实验细节
- 数据集: 在DAVIS数据集中获得的视频上对Pix2Video进行了评估。对于在前期工作或同期工作中使用过的视频,我们使用此类工作提供的编辑提示。对于其他视频,我们通过咨询少数用户生成编辑提示。这些视频的长度从50帧到82帧不等。
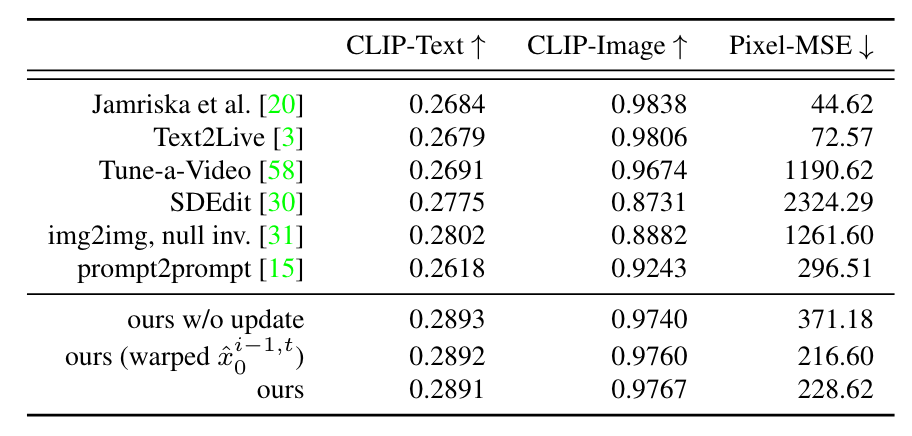
- 基线: 将Pix2Video与当前最先进的图像和视频编辑方法进行了比较。( i )Jamriska等的方法将一组给定帧的风格传播到输入视频片段。我们使用编辑后的锚框作为关键帧。( ii )我们比较了最近的一种基于文本引导的视频编辑方法Text2Live 。我们注意到,该方法首先需要计算一个视频的前景层和背景层的神经图谱,每个视频大约需要7 ~ 8个小时。给定神经图谱,该方法进一步微调文字-图像生成模型,再花费30 min。( iii )我们还与SDEdit进行了比较,其中我们对每个输入帧添加噪声,并在编辑提示的条件下去噪。对加入不同强度的噪声进行了实验,并使用深度条件稳定扩散作为我们的主干扩散模型。( iv )最后,我们还考虑了并行的Tune-a-Video方法,该方法对预训练的图像模型进行视频特定的微调。由于该方法只生成有限数量的帧,我们根据作者提供的设置,在输入视频中每隔一帧采样生成24帧。值得注意的是,该方法不受深度等任何结构线索的限制。表1中总结了实验结果。

- 度量指标: 我们期望一个成功的视频编辑能够忠实地反映被编辑的提示,并且在时间上是连贯的。为了捕获忠实性,选择CLIP分数,即编辑提示的CLIP嵌入与被编辑视频中每一帧的嵌入之间的余弦相似度。我们将这一度量称为” CLIP-Text “。为了衡量时间一致性,我们测量了编辑视频(‘ CLIPImage’)中连续帧的图像嵌入之间的平均CLIP相似性。我们观察到CLIP图像嵌入比局部细节编码了更多的全局外观。因此,我们还计算了连续帧之间的光流,并利用该光流将编辑视频中的每一帧进行下一帧的变形。我们计算每个扭曲帧与其对应的目标帧之间的平均像素均方误差为”Pixel-MSE”。我们注意到该度量对Text2Live和Jamriska等的方法是有利的,他们明确地利用了光流信息。由于我们的方法也使用了粗略的深度结构引导,因此我们将其纳入了我们的评估中。
实验结果

定量实验
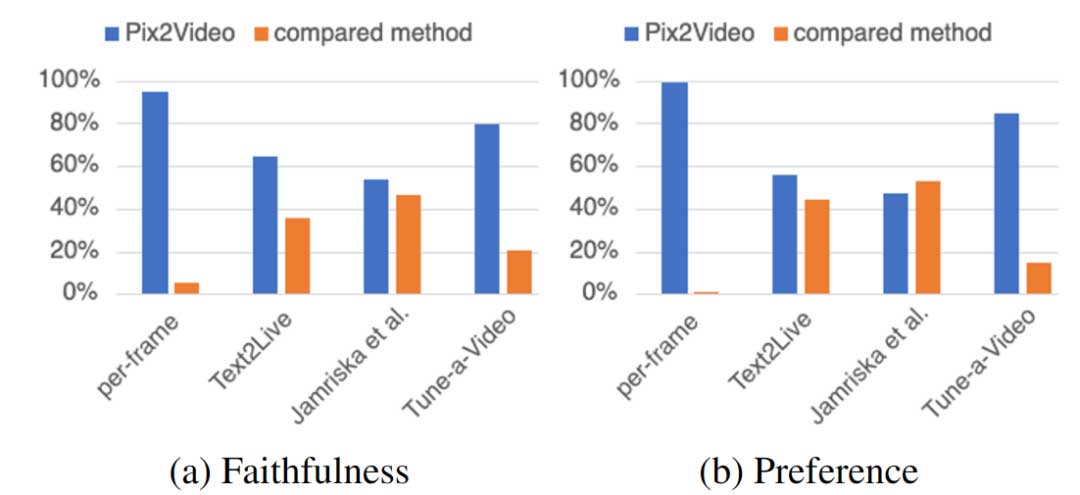
用户实验
消融实验
首先,我们评估了前一帧用于自我注意力特征注入的不同选择。在图下中,我们比较了我们总是关注( i )一个固定的锚框(在我们的实验中的第一个框架),( ii )只有前一帧,( iii )锚框和随机选择的前一帧,以及( iv )锚框和前一帧的场景。

在没有使用前一帧信息或选择随机的前一帧的情况下,我们观察到了伪影,特别是包含更多旋转运动的序列,例如,汽车的结构随着汽车的旋转而不被保留。这证实了我们的直觉,即对前一框架的关注以循环的方式隐式地代表了编辑的状态。在没有锚框的情况下,我们观察到更多的时间闪烁,编辑随着视频的进展而减少。通过将前一框架与锚框架相结合,我们达到了一个很好的平衡。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
