
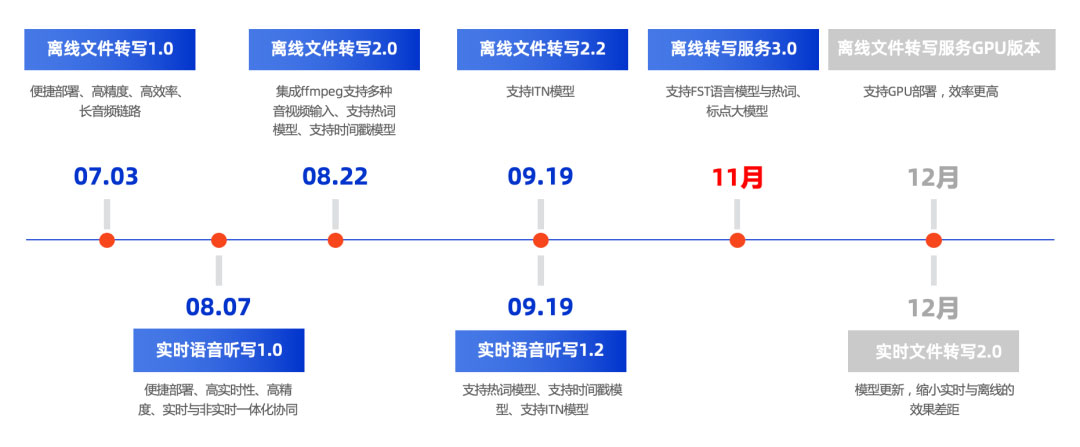
FunASR是由通义实验室语音团队开源的语音识别框架,集成了语音端点检测、语音识别、标点预测等领域的工业级模型的训练和部署,吸引了众多开发者参与体验和开发。
为了支持用户便捷高效的集成语音AI能力,FunASR社区推出了服务部署社区软件包,支持Docker化部署,多路请求。既可以进行高精度、高效率与高并发的文件转写,也可以进行低延时的实时语音听写。
本次推出离线文件转写软件包3.0,主要有三个方面的更新:支持标点大模型、支持语言模型解码、支持wfst热词增强。
FunASR社区软件包地址:
https://github.com/alibaba-damo-academy/FunASR/blob/main/runtime/readme_cn.md
离线文件转写软件包3.0
标点大模型
离线文件转写软件包3.0里的标点大模型支持中英文双语,特别加强了对于英文的支持。同时,在模块前会做分词预处理,保障分词的统一性,提升模型效果。
语言模型解码
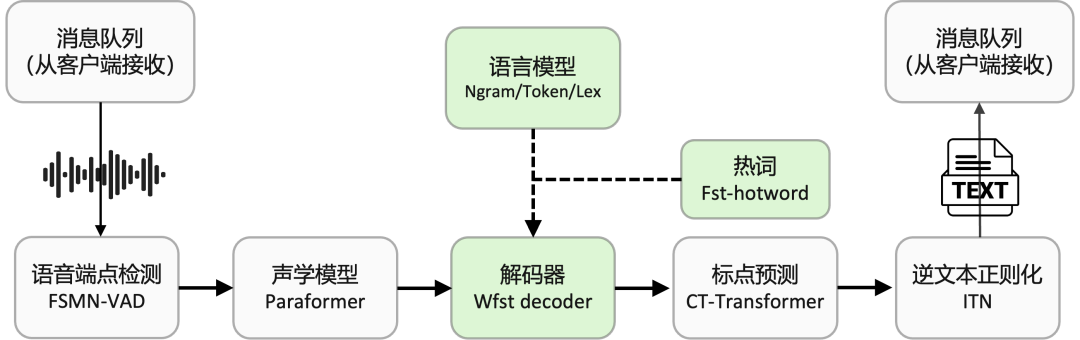
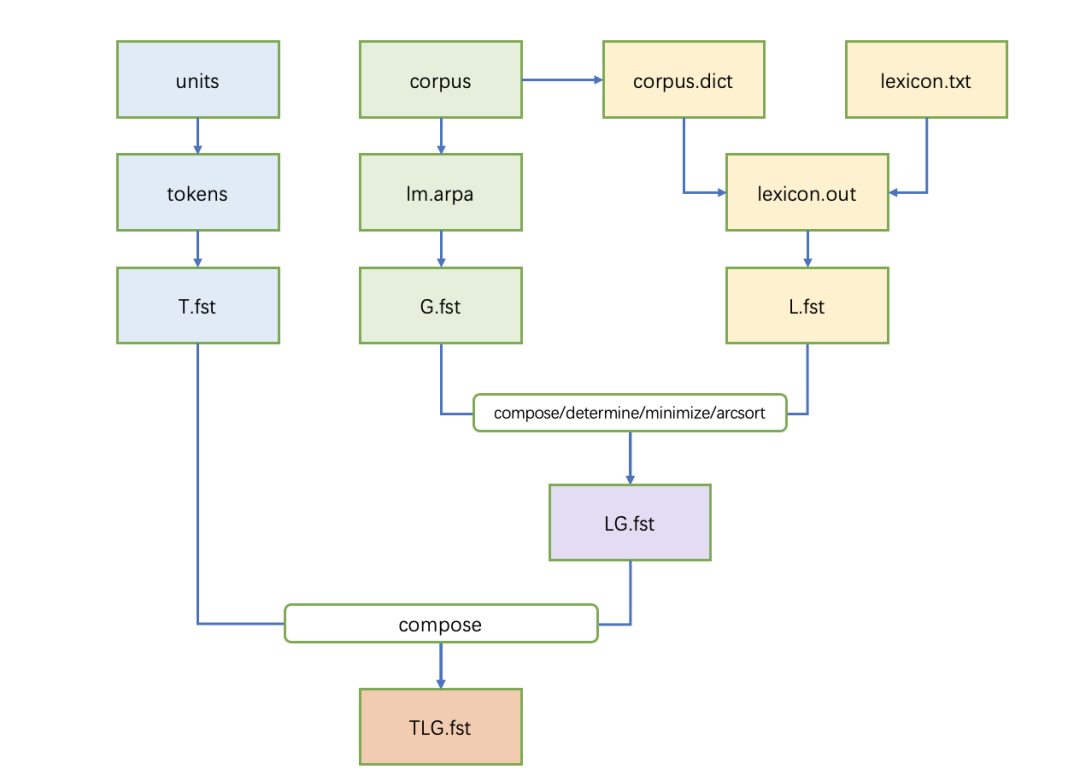
传统基于CD-phone声学建模ASR系统解码器普遍采用HCLG构建解码网络,当前方案中paraformer声学模型直接对音素或字符建模,为此我们采用TLG(Token、Lexicon、Grammar)结构构建统一解码网络,直接将音素/字符序列、发音词典、语言模型编译形成T、L、G三个wfst子网络,再通过composition、determinization、minimization等一系列操作生成统一解码网络。
我们借鉴EESEN方案[1],基于openfst/kaldi构建TLG解码网络编译pipeline,支持从原始语料和发音词典到最终解码资源的全流程编译,便于用户自行定制适合自身的解码资源。如下是TLG网络编译流程图。
wfst热词增强
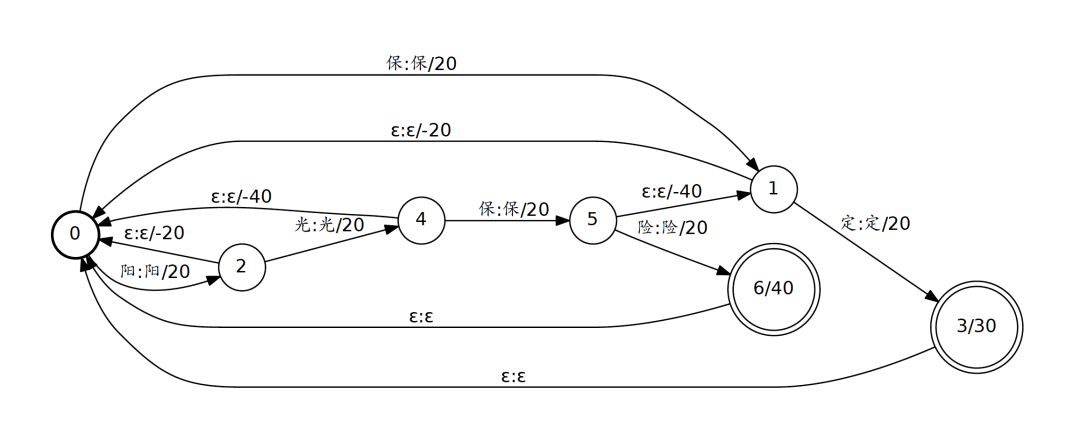
热词构图,我们采用AC自动机结构进行热词网络构图,解决热词前缀重叠场景下难以有效激励的问题。例如热词列表包含“阳光保险”与“保定”两个热词,实际语音内容为“阳光保定”,在匹配到“定”时匹配失败则会根据AC自动机回退机制回退至“保定”热词路径,确保仍可继续匹配的最大子串路径可正常激励。
如下是热词网络实例图。
热词发现与匹配,我们采用对主解码网络弧上ilabel音素/字符序列信息进行热词发现及匹配,而非在网络搜索出词时再对整词匹配,该方式优势是能够更早实现对尚未出词热词路径激励,避免热词路径被过早误裁减,其次也可避免由于热词分词结构不一致而导致匹配失败。
热词激励方式,我们采用过程渐进激励和整词激励相结合的方式,而非热词首字或尾字激励。采用仅首字激励方式可能存在部分case在热词后续字的解码过程中路径仍被裁剪掉的情况,而仅在尾字出词时施加激励则可能激励过晚。
过程渐进激励(incremental bias)对过程中每匹配成功一步即进行等量激励,如在后续扩展过程匹配失败则通过回退弧跳转进行激励减除。
整词激励(word bias)支持用户针对不同的热词做差异化的激励分配置,在热词整词出词时进一步施加对应的补偿或惩罚,进而提高热词综合效果。
测试结果
识别效果测试
我们分别选用aishell1与wenetspeech作为测试集,其中热词子集为[2,3],详细结果见下表:
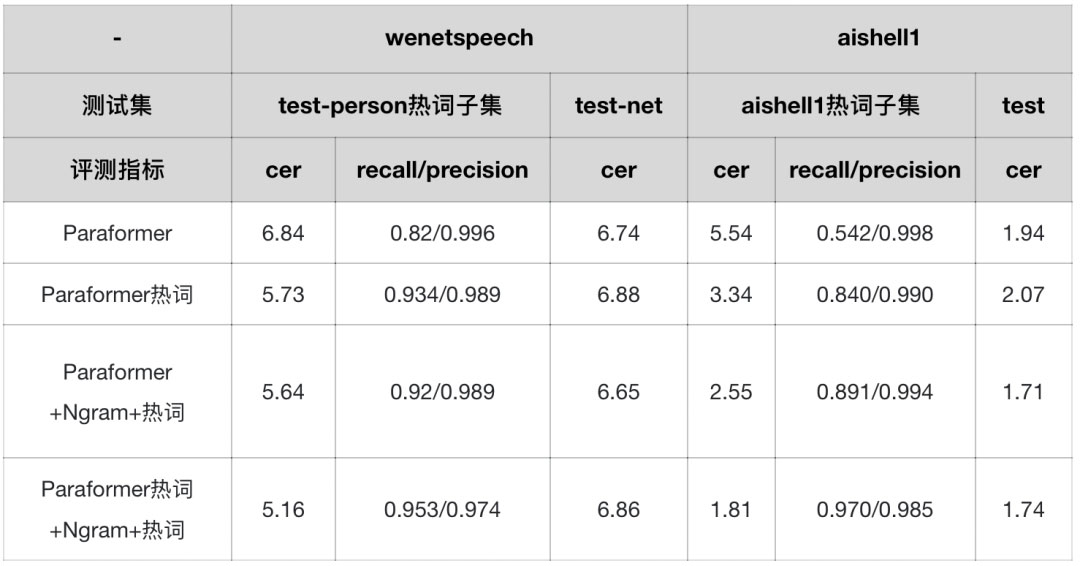
结论:对比Paraformer模型,Paraformer热词模型(NN方案),在热词测试集中,字错误率(cer)下降显著(aishell热词下降40%),召回率提升巨大(aishell热词上提升60%),通用效果(无关热词)几乎无损;Paraformer结合wfst热词增强,在热词测试集中,字错误率下降显著(aishell热词下降55%),召回率提升巨大(aishell热词上提升65%),通用效果提升10%以上;Paraformer热词叠加wfst热词,在热词测试集中,字错误率下降显著(aishell热词下降67%),召回率提升巨大(aishell热词上提升80%)。
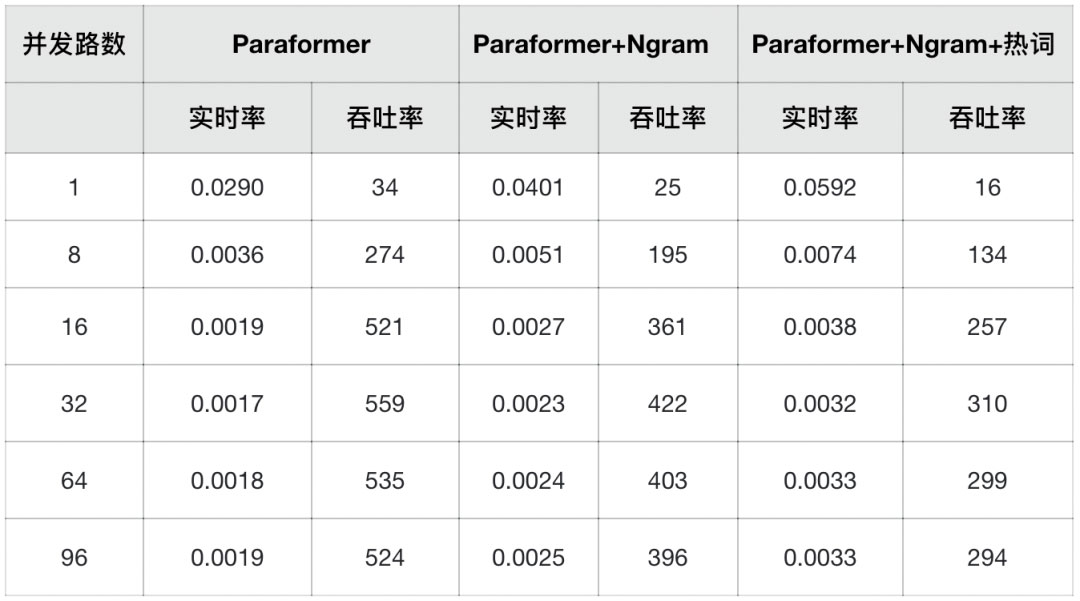
推理效率测试
我们采用aishell1测试集测试了软件包在CPU8369B@ 2.90GHz 16核上的吞吐率(即每小时可以推理多少小时音频)。不同配置下的详细吞吐率指标如下表:
软件包安装使用指南
精简操作,即刻安装,FunASR软件包当前已开源。开源软件包包地址👇:https://github.com/alibaba-damo-academy/FunASR/blob/main/runtime/readme_cn.md
步骤:
准备工作:docker安装(可选)
# 如果您已安装docker,忽略本步骤
curl -O https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/shell/install_docker.sh;
sudo bash install_docker.sh第一步:镜像启动
sudo docker pull \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.3.0
mkdir -p ./funasr-runtime-resources/models
sudo docker run -p 10095:10095 -it --privileged=true \
-v $PWD/funasr-runtime-resources/models:/workspace/models \
registry.cn-hangzhou.aliyuncs.com/funasr_repo/funasr:funasr-runtime-sdk-cpu-0.3.0第二步:服务端启动
cd FunASR/runtime; nohup bash run_server.sh > log.out 2>&1 &第三步:测试与使用
等待服务端启动后,可以用客户端进行测试,支持python/c++/java/html网页等语言。支持多种音频格式输入(.wav, .pcm, .mp3等),也支持视频输入(.mp4等)。
客户端下载:
https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz
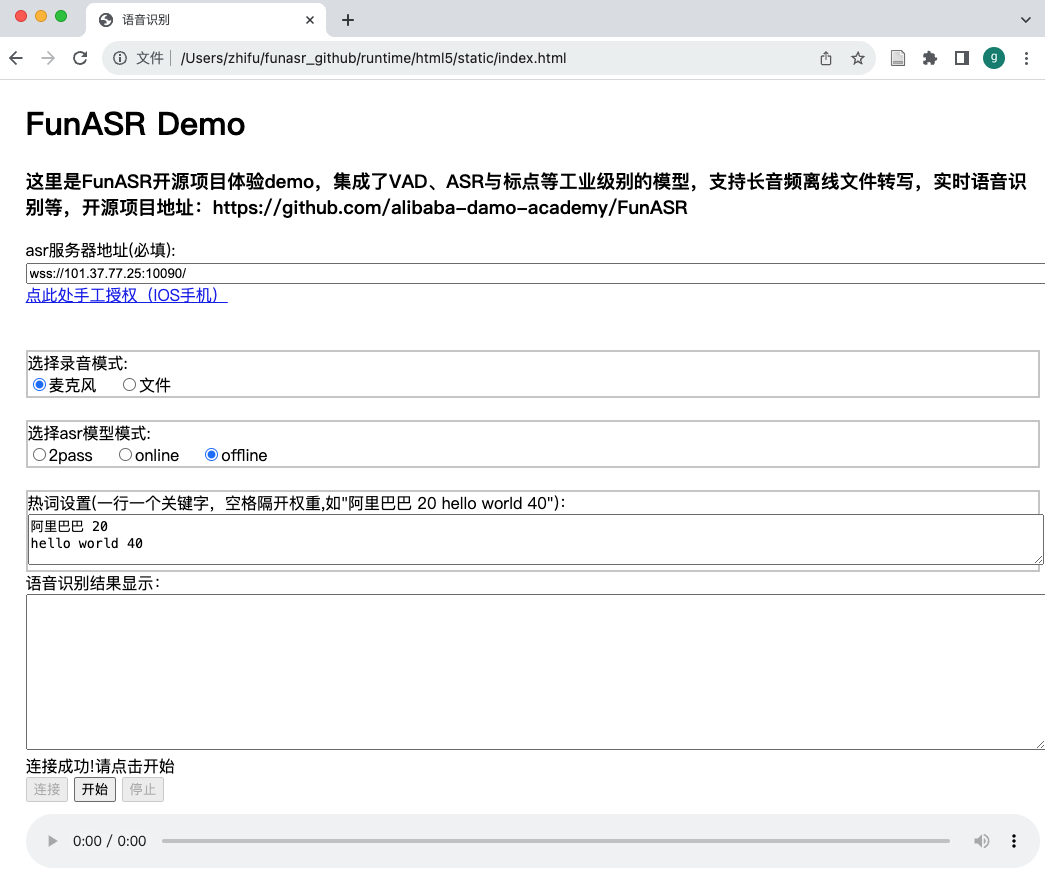
我们以html网页版本client为例,进行说明:在浏览器中打开samples/html/static/index.html,出现如下页面,输入部署服务器ip与端口号后,可以直接进行体验。
FunASR离线文件转写软件包归属于FunASR开源项目。在项目开源过程中,众多志同道合的社区开发者们参与进来,与我们共同努力,共享知识、互相支持,形成一种紧密的合作关系,推动着开源项目的发展。
在此特别感谢:赵明(爱医声)、刘柏基(元象唯思)、马勇(北京理工大学)、朱云峰(上海电信)、张旭(云南日报)、杜靖(魔珐科技)、邱威(广州荔支网路)、郭欢(卡斯柯)、徐怀移(顶顶通)等。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
