
扩声系统用于放大声音,其典型应用包括:多媒体电教室、本地会议系统、助听器和人工耳蜗等,该电声系统至少包括一个传声器、一个放大器以及声重放单元扬声器。当传声器与扬声器处于同一个声学环境时,扬声器信号经过反馈路径之后被传声器采集,被放大器放大,并再次被扬声器播放,该过程不断循环形成声反馈。当某些频点满足奈奎斯特不稳定性条件:(1)系统开环增益函数模值大于1,(2)开环增益函数相位角为2𝜋整数倍。信号的幅度不断增大并引发啸叫,影响主观听觉感受,甚至会对电声设备造成严重的破坏,产生不可逆的系统损伤。
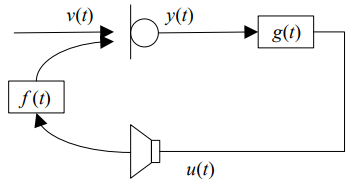
根据奈奎斯特不稳定性条件可知,啸叫的产生需要同时满足相位和幅度条件,因此,至少破坏啸叫产生的一个条件便可以在一定程度上控制声反馈,进而抑制啸叫的产生。从原理上,声反馈控制算法通常可以分为三种类型:相位控制方法、幅度控制方法以及自适应反馈消除方法。然而,这些传统信号处理的声反馈控制方法由于提供的最大稳定增益十分有限,并且受环境变换的影响较大,鲁棒性差,如当反馈路径改变时,自适应反馈消除方法收敛性能急剧下降。近年来,随着深度神经网络的发展,其强大的拟合能力和鲁棒性在语音增强领域得到了广泛的应用,最近,郑等人[1]提出了基于深度学习的临界稳定系统控制算法,利用深度学习的方式在提高系统最大稳定增益的同时又使系统变得更加鲁棒。
深度神经网络的训练需要大量的数据,否则训练完成的模型会产生过拟合的问题。当使用场景为助听器设备时,目前公开可用的助听器声学反馈路径较少.受Polack等人[2]对房间声学冲激响应建模的启发,器声学反馈路径,郑等人又提出一种仿真的方式以生成大量助听器声学反馈路径:
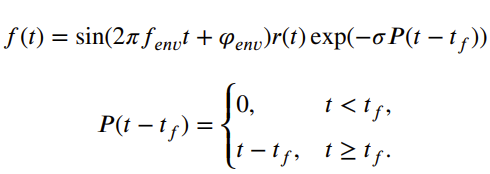
考虑到在啸叫将要发生的临界点进行抑制是最合适的,因此通过奈奎斯特不稳定准则计算出闭环系统最大稳定增益,并将增益调整至最大稳定增益以下3dB以内,进而通过仿真闭环系统声反馈生产的方式产生大量的带有声反馈特征的数据用以深度神经网络的训练。
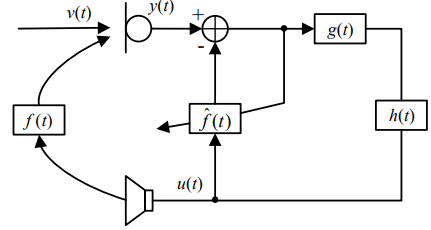
[1]中采用了端到端复数谱映射的训练方式,即训练深度神经网络学习带声反馈信号到纯净的映射。采用的深度神经网络结构为GCRN网络[3],如图3所示。训练完成的深度神经网络可直接加入到实时的闭环系统中控制声反馈,如图4所示。此外,深度神经网络模型也能和传统的算法匹配,作为传统算法的后处理模块,这也说明了深度学习算法强大的泛化性能。
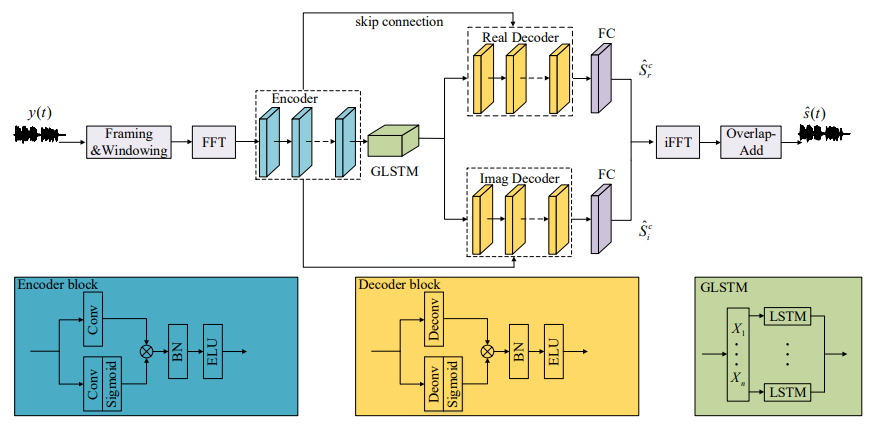
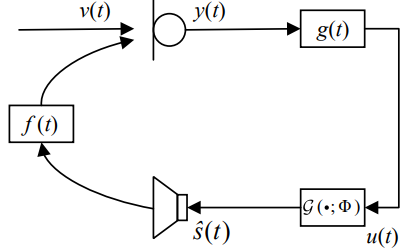
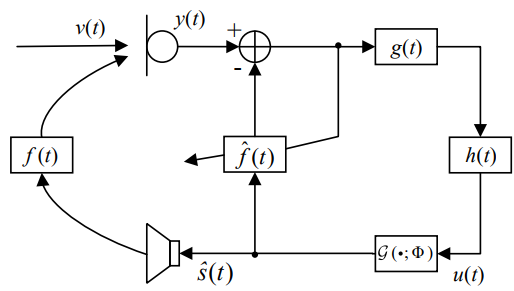
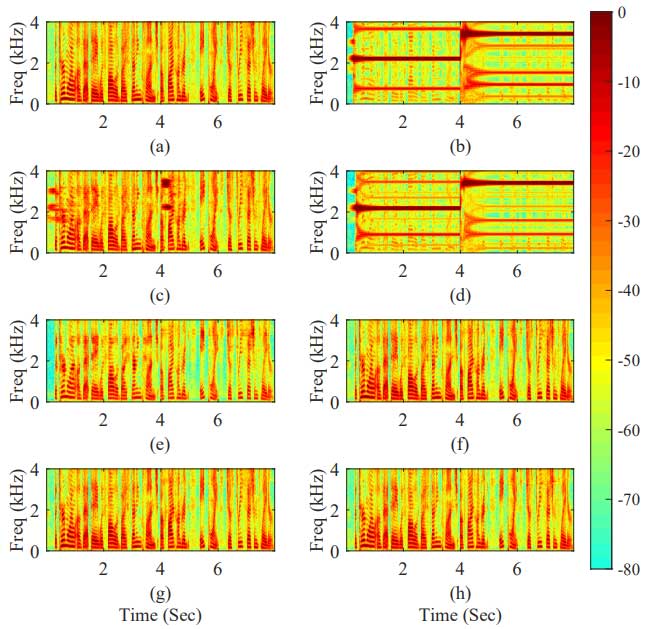
图6是增益较大,且反馈路径变化(第4秒时反馈路径发生变化)情况下各种算法处理后的语谱图,可以看出,传统的相位控制方法、幅度控制方法无法抑制啸叫,自适应滤波器算法在路径变化之后需要重新收敛。而基于深度学习的啸叫抑制算法不受这些因素的影响,取得了最优的结果。
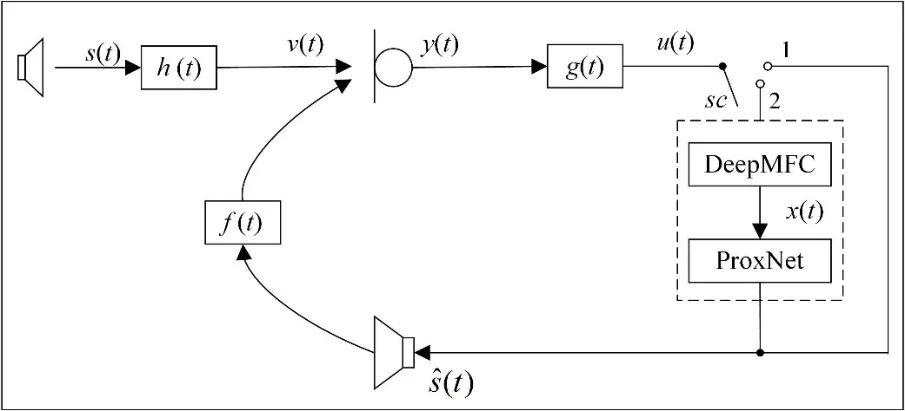
此外,听力受损人群因为听觉系统频率选择性和时间分辨率的下降,相比于正常听力人群受噪声和混响影响更大,在助听器系统中,噪声和混响会严重影响助听器佩戴者的语音质量和可懂度。大量研究结果表明,抑制助听器系统中的混响和噪声可有效提高听力受损人群的语音质量和可懂度[4]。现有的深度学习方法已经可实现噪声和混响的联合抑制,并取得了比传统联合去噪去混更优的性能[5],而声反馈问题和噪声混响问题一直被认为是独立的问题,因而传统的助听器信号处理也是针对各个问题设计各自的算法,然后再将各个算法级联以实现不同问题的分步骤解决。实验表明[6],将声反馈抑制与去噪去混分别训练,或者仅用[1]中单阶段实现声反馈抑制与去噪去混均难以取得满意的性能。针对此问题,[6]中提出一种端到端联合声反馈抑制和去噪去混方法:在第一阶段进行声反馈抑制和噪声去除,在第二阶段进行混响抑制,两阶段网络进行端到端联合优化。实验结果表明,该方法显著提升了语音质量和语音可懂度等客观指标。
参考文献:
[1] Zheng C, Wang M, Li X, et al. A deep learning solution to the marginal stability problems of acoustic feedback systems for hearing aids[J]. The Journal of the Acoustical Society of America, 2022, 152(6): 3616-3634.
[2] Polack J D. La transmission de l’énergie sonore dans les salles [D]. Le Mans, 1988.
[3] Tan K, Wang D L. Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 28: 380-390.
[4] Loizou P C. Speech enhancement: theory and practice[M]. CRC press, 2013.
[5] Li A, Liu W, Luo X, et al. A simultaneous denoising and dereverberation framework with target decoupling[C]. in Proc. Interspeech 2021, pp. 2801–2805, 2021.
[6] 王梅煌,章辉勇,徐晨阳,李晓东,郑成诗. 助听器端到端联合声反馈抑制和去噪去混响研究. 声学学报.
作者:王梅煌
来源: 21dB声学人
原文:https://mp.weixin.qq.com/s/-Wk6Cx7sMlmyjIHJytTDrw
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
