
视觉推理需要多模态感知能力和对世界常识的认知能力。最近,人们提出了多种视觉语言模型(VLMs),在各个领域都具有出色的常识推理能力。然而,如何综合利用这些互补的视觉语言模型却很少被探讨。现有方法仍然难以将这些模型与所需的高阶通信聚合起来。在本文中,作者提出了Cola,一种协调多个VLM进行视觉推理的新范式。作者认为,大语言模型可以通过利用其独特且互补的特性来促进自然语言通信,从而有效协调多个视觉语言模型。实验表明,作者提出的模型指令调整变体Cola-FT在视觉问答(VQA)、外部知识VQA、视觉蕴涵和视觉空间推理任务上实现了SOTA的性能;作者提出的模型上下文学习变体Cola-Zero在零样本或少样本设置下表现出有竞争力的性能,过程中无需进行微调。
题目:Large Language Models are Visual Reasoning Coordinators
作者:Liangyu Chen, Bo Li, Sheng Shen, Jingkang Yang, Chunyuan Li, Kurt Keutzer, Trevor Darrell, Ziwei Liu
来源:NeurIPS 2023
文章地址:https://github.com/cliangyu/Cola
内容整理:张俸玺
引言
视觉推理是一项至关重要的任务,它要求模型不仅要理解和解释视觉信息,还要应用高级认知来得出逻辑解决方案。该领域因其实现广泛智能应用的潜力而收到机器学习社区的极大关注,例如智能辅导系统、自动图像字幕和虚拟助手。为了有效地进行视觉推理,模型必须同时具备视觉感知能力和强大的逻辑推理能力。
虽然经典的视觉推理器通常依赖于复杂的架构或者无法泛化到训练数据集之外,但大型预训练模型的最新进展表明视觉语言模型(VLM)即使在零样本设置下也可以实现令人印象深刻的视觉推理任务性能。同时,大语言模型也在自然语言处理应用中展示了强大的零样本常识推理能力。最近的几项研究尝试将这种互补的VLM和大语言模型结合起来进行视觉推理。
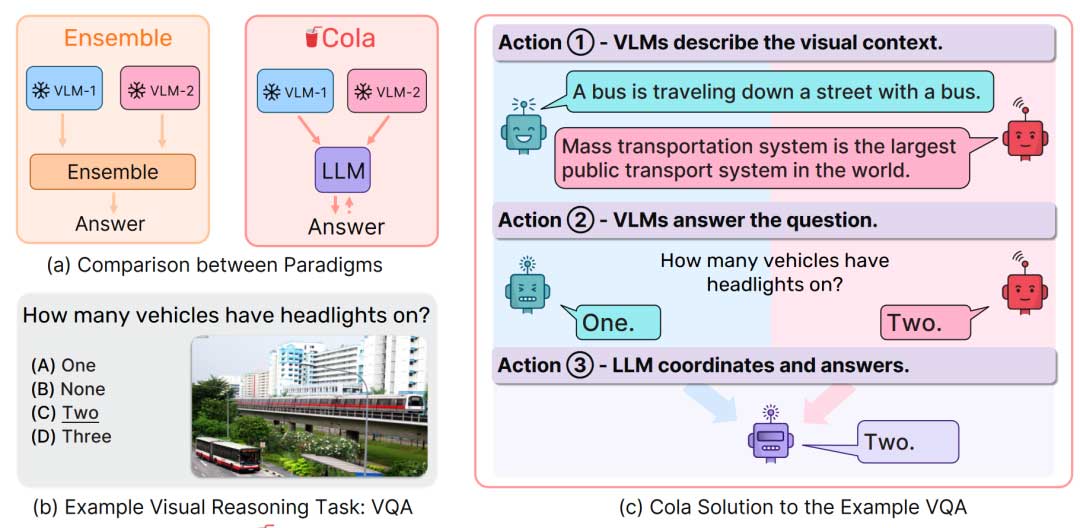
本文中,作者收到CICERO研究结果的启发(大语言模型在协调多个Agent方面具有强大的策略规划和协调能力)提出了一种新的模型集成方法:Cola,利用大语言模型作为多个VLM之间的协调器,研究如何利用大语言模型协调多个同质专家模型(例如多个VLM)。研究发现,鉴于多个VLM在描述视觉上下文和预测自然语言中的合理答案时具有不同的首选模式,大语言模型可以有效地协调和整合VLM各自地优势。作者还提出了Cola的两种变体,Cola-FT和Cola-Zero。其中FT对应于指令微调方法,而Zero基于上下文学习方法,以使作为协调器的大语言模型适应视觉推理。
总而言之,本文的贡献主要分为三点:
(1)提出了一种利用语言模型作为多个视觉语言模型之间协调器的新范式Cola,以整合它们各自的优势进行视觉推理。
(2)Cola在一系列具有挑战性的多样化视觉推理任务和数据集上达到了SOTA性能。
(3)本文的实验揭示了Cola是如何理解指令提示,随后协调它们以捕获视觉推理能力的。
方法

集成建模: 聚合多个模型的预测以提升整体性能。例如,一种常见的做法是对个模型进行平均:
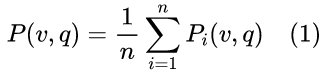
其中,pi(v,q)表示对第i个模型在输入(v,q)的预测。
Cola与模板
Cola的结构概述如图1(c)所示。作者使用OFA和BLIP作为VLM。大语言模型包括编码器-解码器和仅解码器的Transformers。作者首先提示每个VLM独立输出标题和合理的答案。随后,作者将指令提示、带有选择的问题、标题和合理的答案连接起来,以融合大语言模型的所有上下文,从而进行推理、协调和回答。
图像字幕: 提供了重要的视觉背景以供推理。作者首先使用第i个VLM分别描述每个图像以获得视觉描述ci(v)。作者将“ofa-large”用于OFA并且将“blip-image-captioning-large”用于BLIP,两者均由Hugging Face Transformers库来实现。
VLM对问题的合理答案为VLM提供线索和模式,以供语言模型考虑和协调。与字幕类似,作者使用图像-问题对提示每个VLM(第i个),以获得合理答案âi(v,q)。作者使用”ofa-large“表示OFA,使用“blip-vqa-base”表示BLIP。遵循OFA,Cola的提示模板因任务类别而异。对于VQA任务,作者保留原始问题不变。对于视觉蕴涵和视觉空间推理任务,Cola的提示模板是“图像是否描述了<文本前提>?”。
提示模板: 如表1所示。首先,我们为语言模型设计了一个指令提示,以了解协调VLM以回答视觉推理问题的要求。随后,作者将每个VLM模型的标题与自然语言的VLM识别标签连接起来。接下来,问题及其由VLM提供的合理答案被连接起来。作者通过包含问题各个选项和“”来提示答案。总的来说,大语言模型输入的提示是:

Cola-FT
Cola的指令调优是通过预训练的检查点来初始化的。给定基于图像v的q问题,语言模型以序列的形式预测答案。
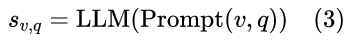
为了优化大语言模型,Cola-FT使用语言建模损失进行下一个标记预测,并采用教师强制策略。作者仅对大语言模型进行微调,以遵循继承建模的常见范式并简化方法,详见图1。
推理: 部署与表1相同的提示以保证与指令调整保持一致。作者在指令调整和推理方面都采用贪婪编码策略来生成条件序列。
Cola-Zero
情景学习是在关于远程连贯性文件上进行预训练后的大语言模型所具备的一项新兴能力。通过从演示中学习输入和输出格式,上下文学习器只需根据由输入输出示例组成的提示即可学习和执行下游任务。根据带有示例的指令提示进行了微调的协调者大语言模型能够进行基于上下文的少样本学习和零样本学习。
Cola-Zero是无需指令调整下Cloa的上下文少样本/零样本学习变体。对于基于上下文的k-shot学习,作者修改提示(如表1所示)以包括从训练集中采样的k个输入输出示例。对于零样本学习,所使用的提示与表1相同。
实验
整体表现
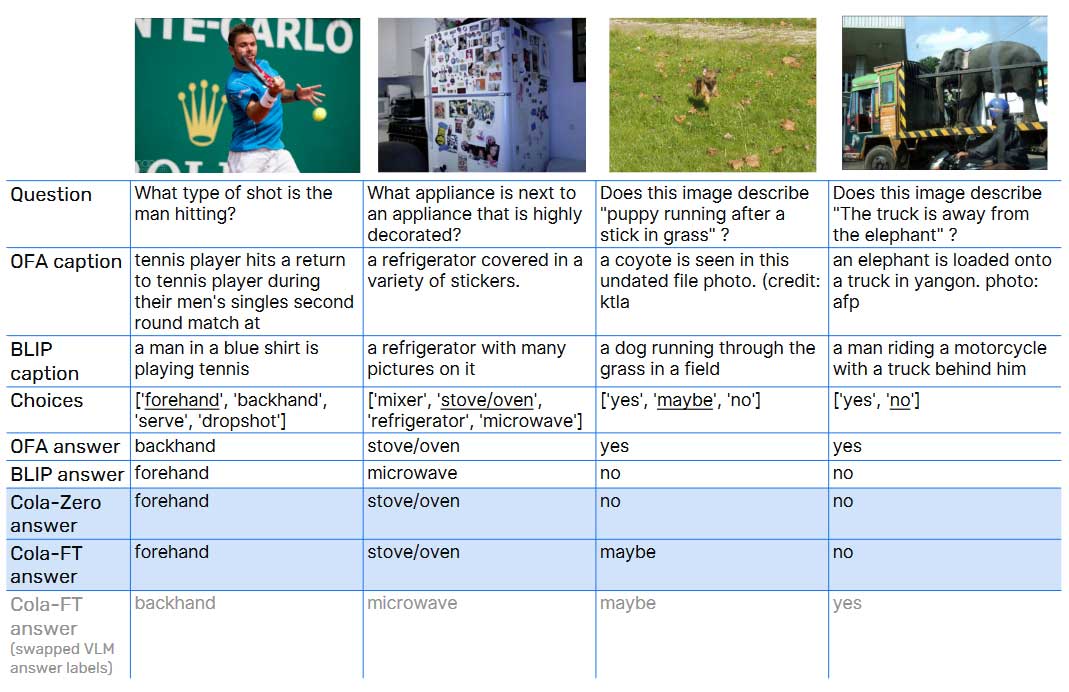
如表2所示,Cola-FT在四个数据集上(A-OKVQA, OK-VQA, e-SNLI-VE, VSR)上仅用一个epoch的指令调整和中等规模的语言模型就实现了SOTA性能。相比之下,许多先前的SOTA方法比Cola-FT需要微调更多的epoch,有些还需要使用更大规模的语言模型。Cola-FT在e-SNLI-VE上的表现优于OFA-X,尽管后者在更多相关任务和数据上进行了微调。此外,更轻巧的版本Cola-Zero还通过基于上下文的少样本和零样本学习实现了在无需训练任何模型参数的情况下达到与大多数基线方法相当的性能。
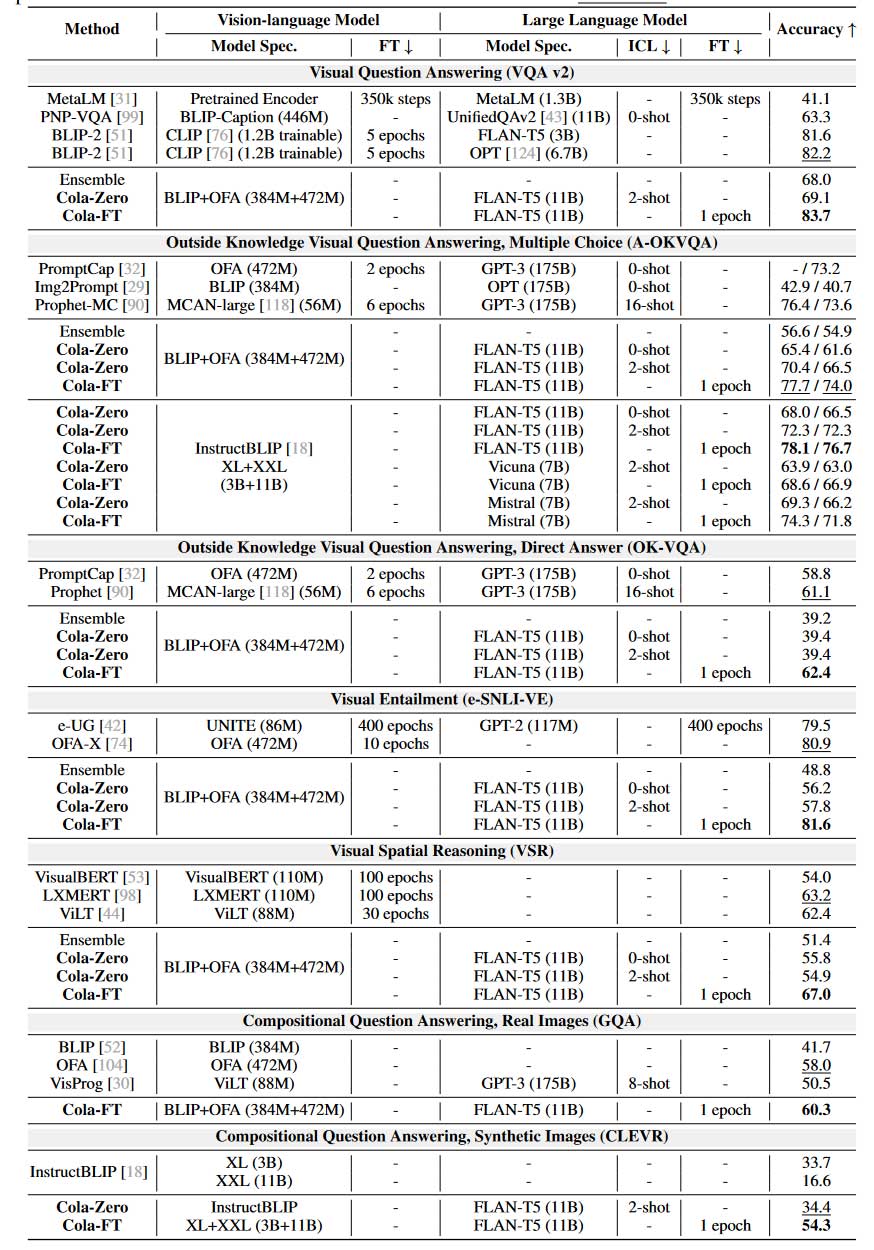
定性结果示例
如图2所示,这里展示了几个定性示例。语言协调器根据给出的标题以及标题和答案的标签,隐式确定VLM给出的合理答案的正确性。图2中最左边的示例(网球运动员正在打球)演示了字幕无法提供足够明确的信息来引导大语言模型进行预测的情况。在OFA和BLIP给出的合理答案之间,大语言模型遵循了BLIP的答案。相比之下,在左边的另一个例子中(冰箱旁边的烤箱),同样带有琐碎的标题,大语言模型此时却遵循了OFA给出的更合理的答案。
所有合理的答案、标题、VLM答案/标题标签以及大语言模型本身的世界知识都有助于语言协调器做出最终的绝对。最右边的示例呈现了标题和答案不一致的情况。OFA将这种照片描述为“一头大象被装上开往仰光的卡车”。不过,它同意“卡车正远离大象”。通过Cola-FT,大语言模型可以协调OFA的正确标题和BLIP的正确答案,从而做出合理的推测。
作者注意到,在引导大语言模型时,标题(captions)比看似合理的答案(plausible answers)更能提供信息。正确的示例(一只奔跑的小狗)呈现出一幅无信息的图像。尽管OFA和BLIP都没有成功回答这个问题,但大语言模型给定的上下文视觉选择回答”也许”。
显著性可视化
如图3所示,作者通过输入梯度显著性特征归因可视化输入提示标记的重要性,并使用Ecco实现。与预测输出标记“草(Grass)”更相关的输入标记以较暗的颜色突出显示。在给定的示例中,Cola-FT和Cola-Zero都正确预测了答案,并从视觉上下文信息和合理答案中找到了相关线索。图3(b)显示Cola-Zero将输出更多地归因于提示模板中的指令。这一结果解释了Cola-Zero的竞争性能。这是FLAN指令调整的结果。经过这一指令调整后,Cola-FT更加关注输入中信息最丰富的部分:问题、选择项以及VLM的合理答案。

相关工作
视觉推理
除了问答(QA)等单模态推理任务之外,视觉推理将高级认知拓展到视觉领域,需要智能Agent得出合理的解决方案。目前已经引入了几个任务来解决视觉推理,例如VQA,模型预计提供与图像相关的问题答案,以及视觉蕴涵(Visual Entailment),在这里模型需要确定文本描述是否与提供的视觉内容一致。
经典的视觉推理方式采用图像编码器以及推理块,该推理块利用注意力机制、神经符号方法(Neuro-symbolic Methods)或外部知识(External Knowledge)。大型预训练模型的最新进展促进了大语言模型的发展,这些大语言模型能够捕获特殊的常识推理能力。这些大语言模型有可能取代视觉推理任务中的推理模块,并且大语言模型感知能力的缺乏可以通过合并不同领域训练的多个VLM来进行弥补。
Model Ensemble
Model Ensemble是一种强大的机器学习技术,它结合了多个模型的预测来提高给定任务的整体性能。最终预测的方差和偏差减小,从而产生更稳健和准确的模型。
集成方法对于视觉推理等生成任务一直具有挑战性,其中简单的组合由于其巨大且变化的输入输出标记空间而不适用于异构模型。为了解决这个问题,苏格拉底模型使用即时工程,通过自然语言讨论来指导异构预训练多模态模型。然而,以往的方法并不能完全适应不同模型的内在模式,特别是在视觉推理场景中。最近的研究如CICERO,表明大语言模型在协调多个智能体方面拥有强大的社交智能。近期,Toolformer和HuggingGPT进一步证明了大语言模型利用、协调和整合外部来源(例如其他模型,甚至API)的结果来解决复杂任务的能力。
结论
在本文中,作者提出了一种视觉推理的新范式:通过利用协调机制综合利用多个VLM的能力,其中大语言模型充当协调器的作用,与VLM进行通信以整合各自的优势。实验表明,大语言模型微调或上下文学习可以显著提高模型推理性能。本文的结果为构建具有多模态推理能力的多组件智能系统提供新思路。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
