
视频理解任务在计算机视觉领域备受关注,但是很少研究各种计算机视觉方法在压缩视频上的表现,而在实际场景下,视频理解通常是视频压缩的下游任务。因此,需要研究传输比特率和视频理解性能的权衡。本文提出面向理解的视频编码框架(UVC),引入了轻量可学习分析流来编码下游分析所需信息,兼顾工业编解码器的高效性和深度学习的编码能力。并且,本文利用任务无相关的边缘图保真度作为优化目标,以自监督方式完成对框架的优化,提升了实际部署效果。
来源:arXiv 2022
题目:A Coding Framework and Benchmark towards Compressed Video Understanding
作者:Yuan Tian, Guo Lu, Yichao Yan, Guangtao Zhai, Li Chen, Zhiyong Gao
原文链接:https://arxiv.org/abs/2202.02813
内容整理:刘潮磊
引言
背景
- 从(压缩后的)低分辨率视频重建高分辨率视频很难
- (压缩后的)低分辨率视频对下游任务不友好
- video understanding tasks算法大多针对原视频,但实际中常用于压缩后的视频
目的
- 减少传输码流大小
- 优化下游任务效果,并减少下游任务计算量
- 提升重建视频的质量(但不是主要关注点)
特点
- 构建了双流结构,补偿压缩视频中缺失的信息
- 优化是和任务无关的,无监督的
贡献
- 解决由编码引起的视频理解任务效果不佳
- 无监督的,单个优化过程能很好地对接多种后续任务
- 网络结构是动态的、自适应的,可以减少比特损耗
相关工作
视频压缩
视频编码算法有很多,如广泛应用的H.264、H.265,但是它们都是为了更好地保证重建视频有着更高的质量,并且编码的质量指标(PSNR、SSIM)都是为了保证人的视觉体验设计的,没有专门为下游AI相关任务设计编码算法。
自监督语义学习
主要方法有:对比学习(Contrative Learning)、掩码图像建模(Contrative Learning)
- 对比学习:将某一图像增强的图像作为正样本,其余图像作为负样本。学到的语义信息依赖于所采用的增强方法,并且偏重于全局语义。
- 掩码图像建模:从未被掩盖的块中预测出被掩盖的块。
框架
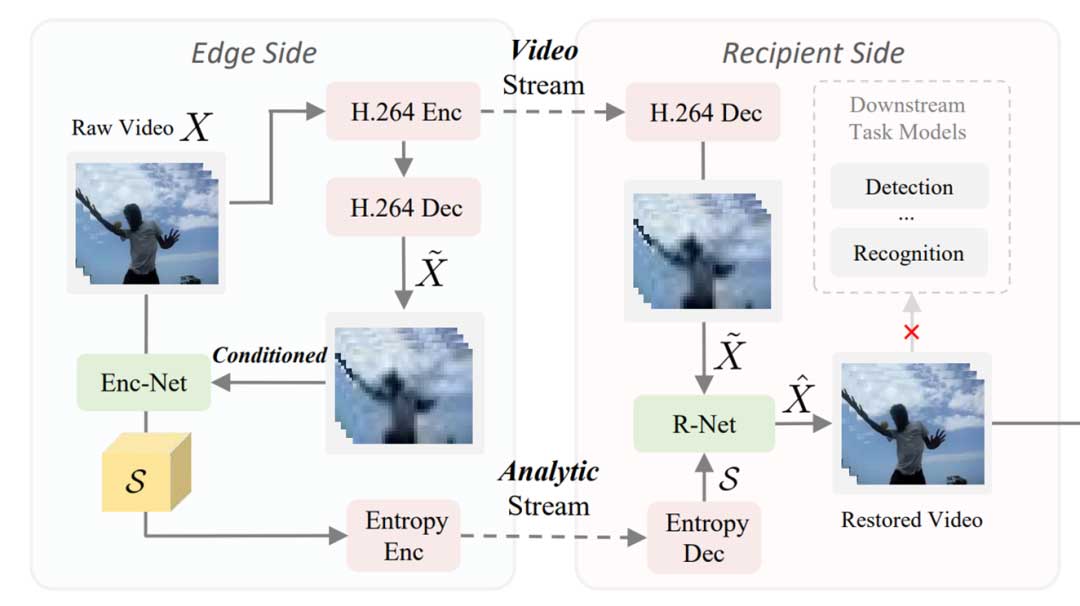
分析流编码器(Enc-Net)
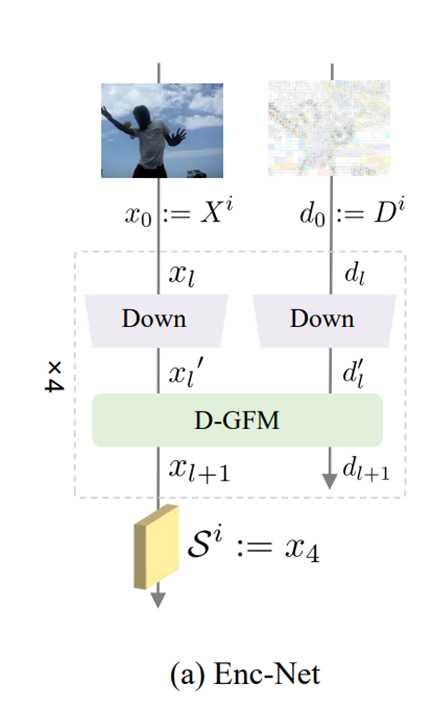
1. 将每一帧作为输入进行降采样;
2. 使用D-GFM进行混合;


3. 输出使用一个3D CNN处理;
4. 最终由一个熵编码器编码成分析流。
D-GFM
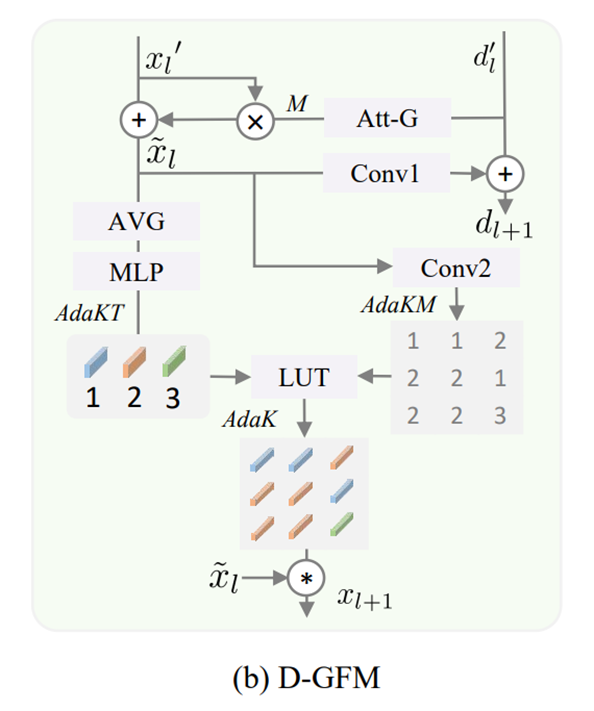
1. 帧特征增强:使用Att-G(两组卷积)产生attention map,增强x’l;
2. 生成自适应核表:x经过平均池化、MLP得到AdaKT;
3. 区域自适应特征提取:dl+1经过一个卷积得到AdaKM,再用查找表得到AdaK;
4. 最后与x相乘得到xl+1。
视频重建网络(R-Net)
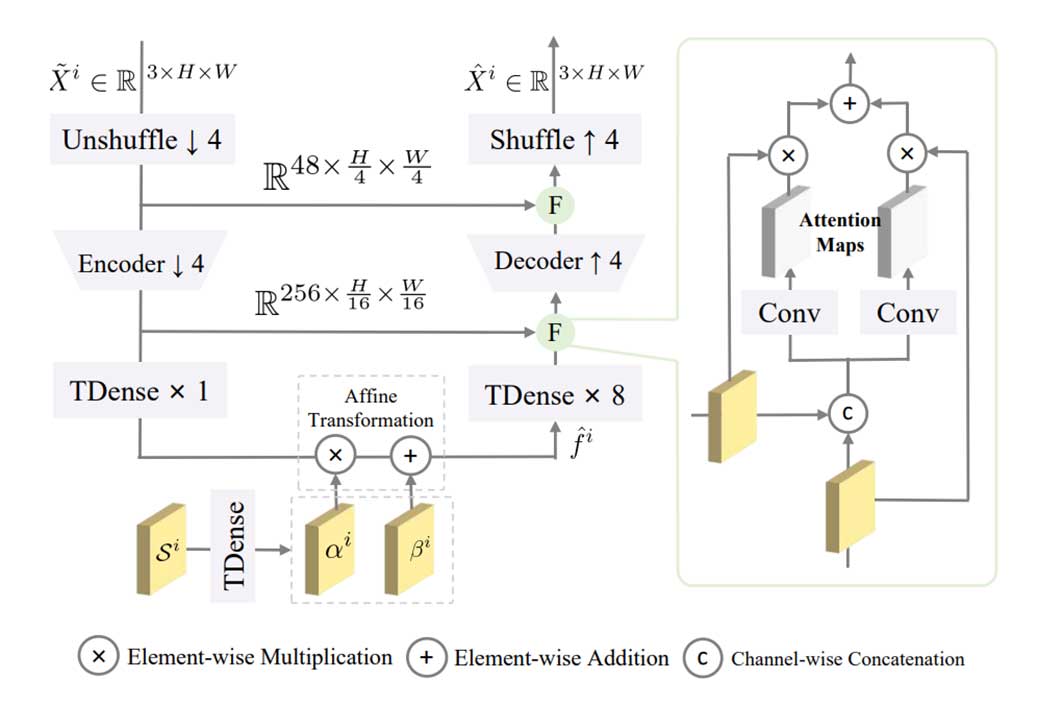
1. 降采样(倍率为4);
2. 使用一个CNN进一步降采样,并增加通道数;
3. 用Tdense处理Si得到前半、后半分别是αi和βi ,并进行变换得fi;
通道融合(F):利用自适应机制保存对下游任务有用的信息(压缩伪影会被抑制)。
优化
目标:替代目标损失最小化;减少分析流的大小。
与下游任务无关的替代目标
要实现无监督就找一个替代目标,本文选择:重建视频的边缘信息与原视频误差最小。
全局边缘信息描述:
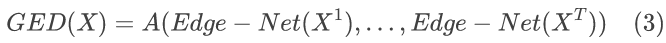
(Edge-Net:边缘信息提取器;A:全局聚合操作)
全局边缘信息约束:
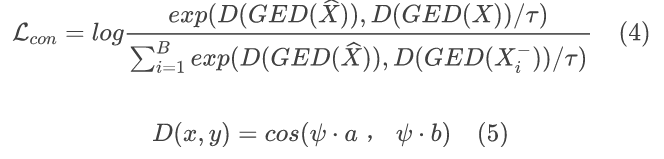
(采用对比学习的形式给出,并以余弦相似度为指标)
局部边缘图相似度约束:
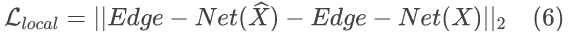
损失函数
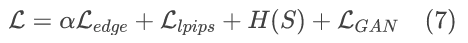
下游任务的替代损失:一部分是之前的边缘损失,另一部分是感知损失,用于约束块级别的分布,只有边缘损失的话,只约束到了帧的级别,重建出的视频可能随机性比较大。
分析流比特率:用于约束分析流的大小。
GAN loss:用于约束域间隙,减少不同数据分布或数据源之间的差异而导致的模型性能下降。
实验
数据集
- 动作识别任务:UCF101, HMDB51, Kinetics, Something V1, Diving48
- 动作检测任务:AVA
- 多目标追踪任务:MOT17
动作识别结果

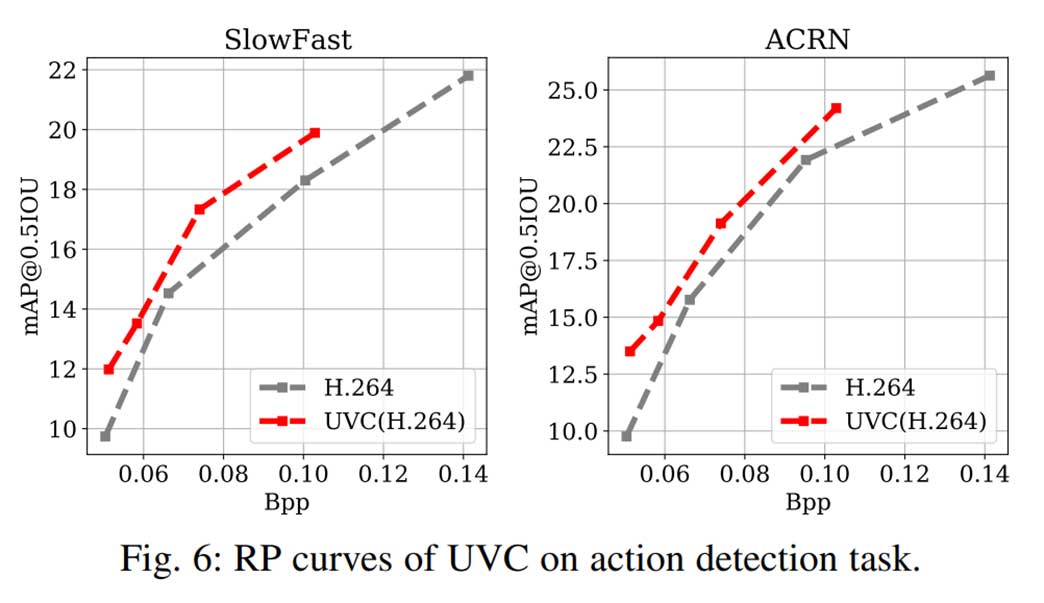
动作检测结果
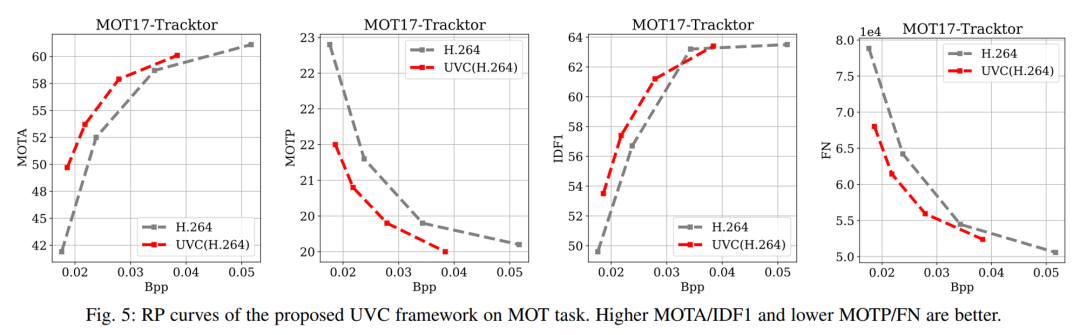
多目标追踪结果
结论
本论文提出了一种用于压缩视频理解的编码框架 UVC 。本文的框架继承了传统视频编解码器高效性和神经网络灵活编码能力的优点。实验结果表明,本文的方法在三个下游视频理解任务(动作识别、动作检测和多目标跟踪)上远远优于基准工业编解码器。此外,本文全面构建了针对这一问题的基准测试,涵盖了七个大规模视频数据集。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。