
视频压缩的大多数方法旨在改进重建视频质量,而非特别保留AI任务所需的语义信息,这会降低下游AI任务的完成效果。此外,任务无关的网络将编码系统与下游任务解耦,并且对于数据稀缺情况友好,但鲜有编码方法是任务无关的。本文试图建立一套方法满足上述两个要求。为解决压缩期间丢失的语义信息,本文提出了语义挖掘并补偿(SMC)框架作为基线方法,以提高当前普通视频编解码器的语义编码能力。至于框架的自监督优化,本文以MAE作为基本方法,并引入NSS进一步抑制非语义信息。本文提出的方法在广泛的任务范围内表现出色,且无需利用任何数据标签。
来源:ICCV 2023
题目:Non-Semantics Suppressed Mask Learning for Unsupervised Video Semantic Compression
作者:Yuan Tian, Guo Lu, Guangtao Zhai, Zhiyong Gao
原文链接:https://openaccess.thecvf.com/content/ICCV2023/html/Tian_Non-Semantics_Suppressed_Mask_Learning_for_Unsupervised_Video_Semantic_Compression_ICCV_2023_paper.html
内容整理:刘潮磊
引言
背景
- 从(压缩后的)低分辨率视频重建高分辨率视频很难
- (压缩后的)低分辨率视频对下游任务不友好
- video understanding tasks算法大多针对原视频,但实际中常用于压缩后的视频
目的
- 减少传输码流大小
- 优化下游任务效果,并减少下游任务计算量
- 提升重建视频的质量(但不是主要关注点)
特点
- 用MAE方法针对损失的语义信息进行补偿
- 引入NSS对非语义信息进行抑制
- 优化是和任务无关的,无监督的
贡献
- 针对无监督视频语义压缩问题提出SMC
- 利用掩码图像建模进行语义编码
- 提出非语义抑制的学习策略,进一步减少传输比特率
相关工作
视频压缩
视频编码算法有很多,如广泛应用的H.264、H.265,但是它们都是为了更好地保证重建视频有着更高的质量,并且编码的质量指标(PSNR、SSIM)都是为了保证人的视觉体验设计的,没有专门为下游AI相关任务设计编码算法。
自监督语义学习
主要方法有:对比学习(Contrative Learning)、掩码图像建模(Contrative Learning)
- 对比学习:将某一图像增强的图像作为正样本,其余图像作为负样本。学到的语义信息依赖于所采用的增强方法,并且偏重于全局语义。
- 掩码图像建模:从未被掩盖的块中预测出被掩盖的块。
框架
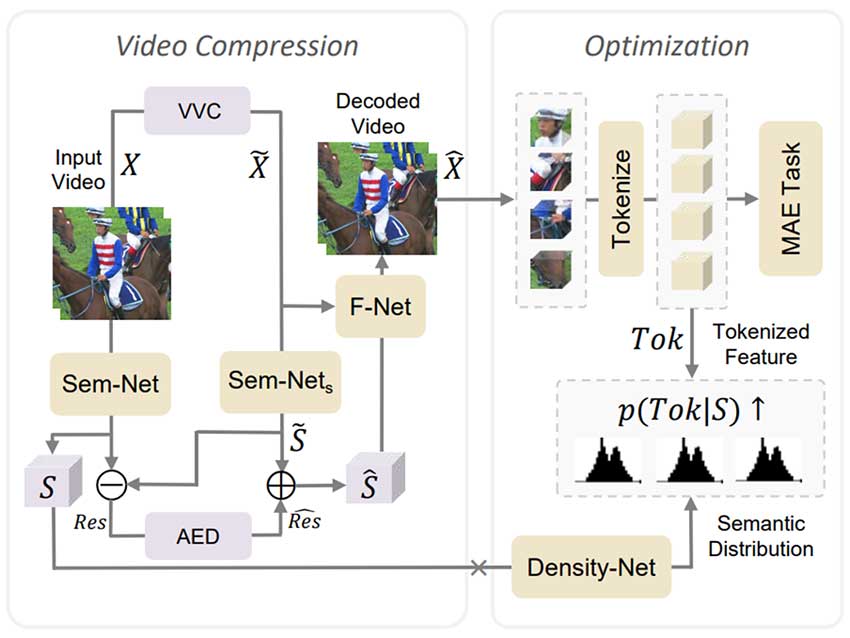
Semantic Extraction Network
提取出视频中的语义信息。文中使用ResNet18网络作为Sem-Net。而由于Sem-Net~s~在网络中需要计算两次,采用了相对轻量级(由五个卷积层组成)的网络。
Semantic Residual Coding
原视频语义信息S、有损编码之后的视频的语义信息S的残差Res,将被自动编解码器(AED)网络压缩,编码、解码器都由三个因果时间卷积组成。
Semantic-Visual Information Fusion
使用UNet形式的生成器网络来综合出最终的重建视频X^。
优化
目标:解码后视频语义信息尽可能丰富;减少残差语义特征流的大小。
损失函数

自监督语义学习
基础: MAE框架
改进: 引入NSS减少非语义信息的保存
MAE:
- 将解码后视频分成16×16的块;
- 将每个块转成一个token(用线性嵌入的方式),形成一个集合Tok;
- 将Tok中一部分掩盖,另一部分输入预测网络ψ中重建视频。
MAE的重建损失:
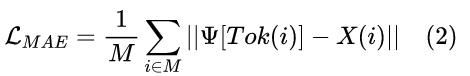
NSS(基于挖掘出的语义信息S实现):
1. 为估计信息熵,在化为Tok之后,加入量化操作;
2. 用高斯混合模型估计Tok的分布,参数由Density-Net(S)给出;

实验
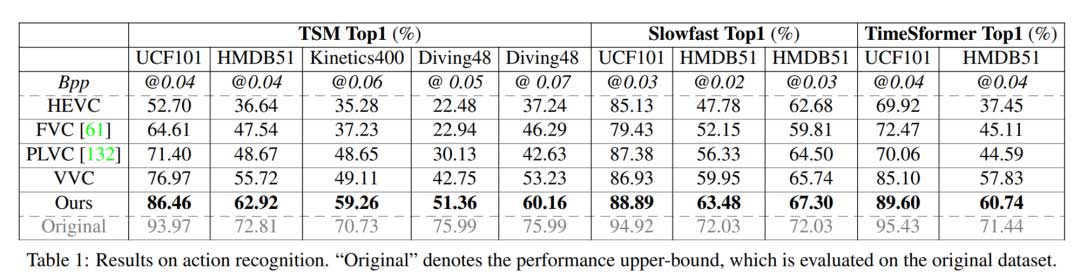
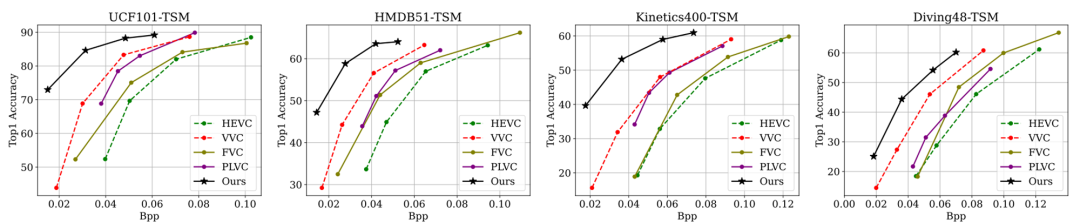
动作识别结果
多目标追踪结果
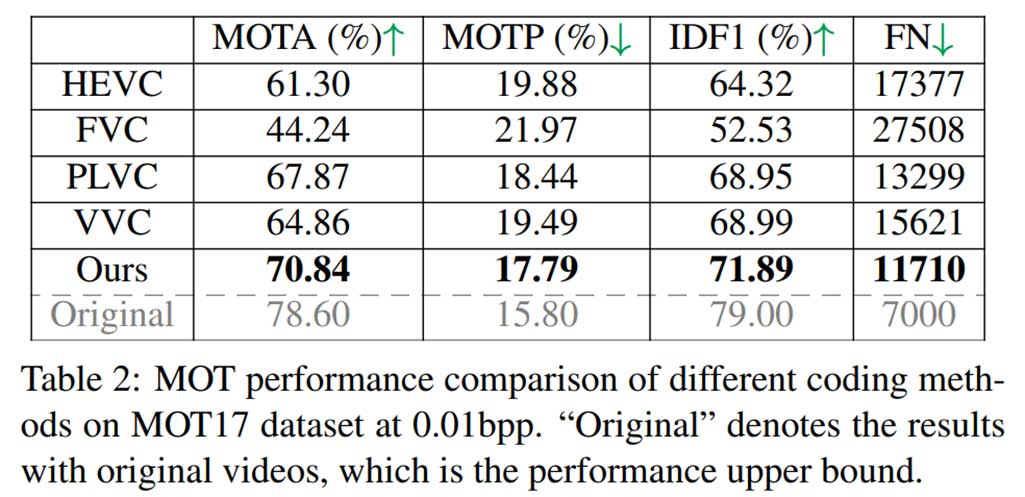
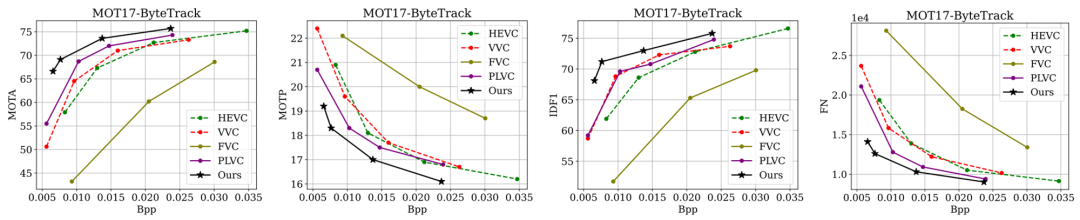
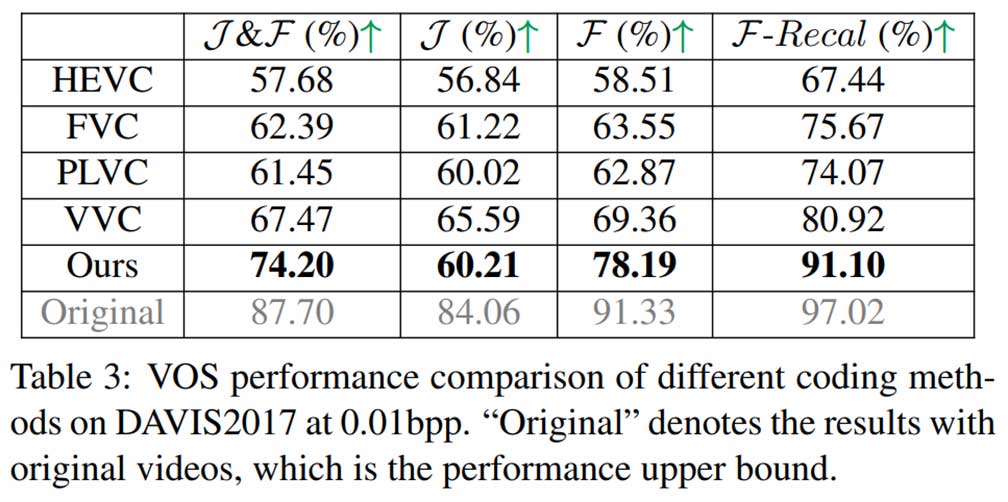
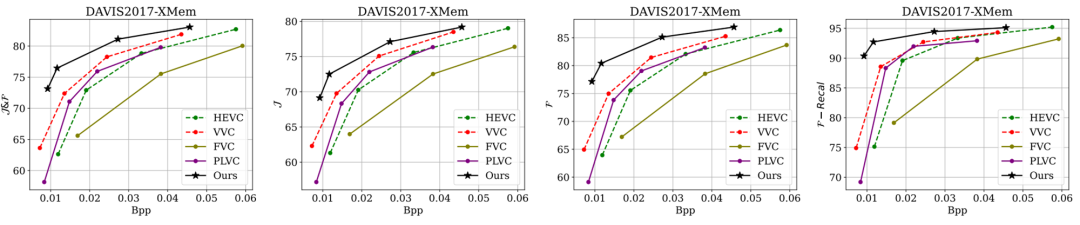
视频对象分割结果
消融实验
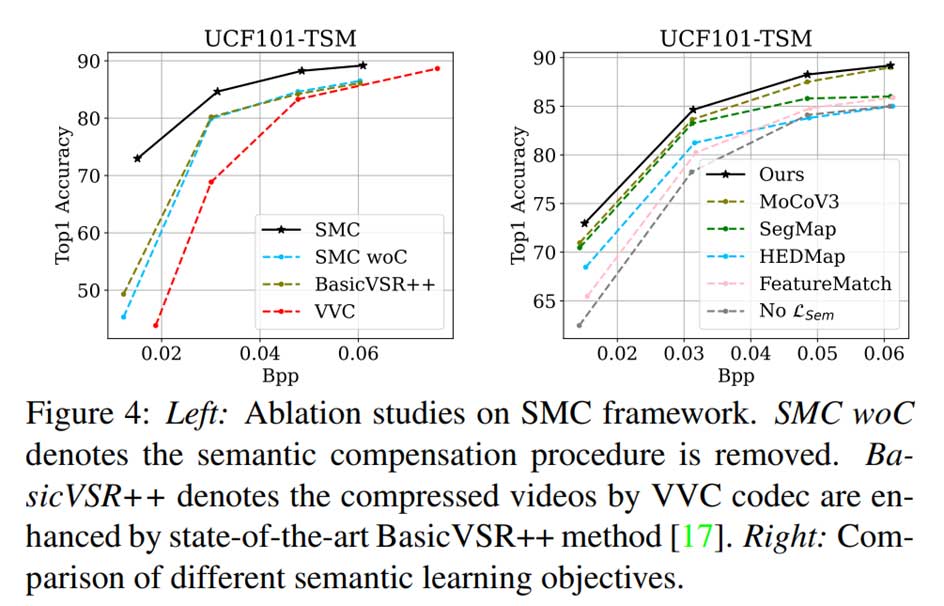
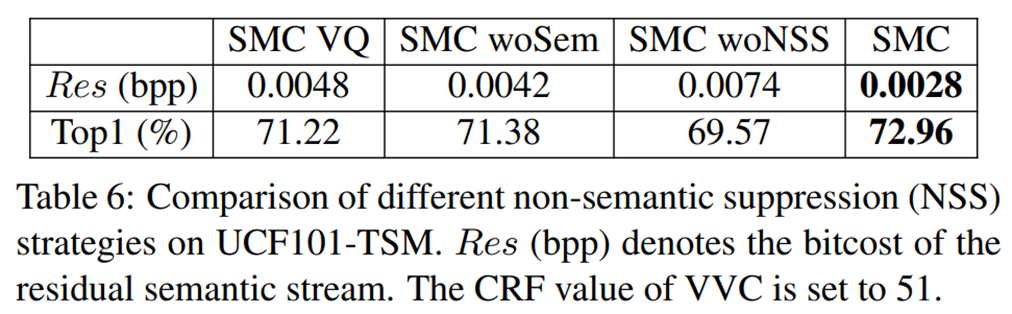
结论
这篇论文中专注于无监督视频语义压缩问题。本文提出了一个简单的基线框架SMC,并采用非语义抑制的MAE损失来解决这个问题。本文还将几种视频编解码器在三个常见的视频分析任务上建立了一个基准,并进行了全面的实验。实验表明本文的方法取得了显著的结果。但是本文的方法依然存在一些限制,其中一个限制是:学习到的语义仍然依赖于由自然图像组成的训练数据集,可能导致在专业领域(如医学图像分析)等方面表现不佳。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
