
MPAI(MOVING PICTURE, AUDIO AND DATA CODING BY ARTIFICIAL INTELLIGENCE)是一个国际化的非盈利性质的组织,主要的研究方向为基于 AI 的数据编码标准。数据编码的含义即为通过一定的编码将数据从一种形式转化为另一种适合应用的形式。
MPAI 的活动主要有 4 个特点,分别为基于严格的流程的开发标准、在制定标准前制定知识产权指南、在标准的AI框架(AIF)中执行聚合的AI模块(AIM)以及治理MPAI的生态问题。
AI框架(MPAI-AIF)
Al 框架能够创建、执行、组成和更新基于 AIM 的工作流程,用于高复杂度的 AI 解决方案,将多厂商的 AIM 相互连接起来,并在标准的 AI 框架中运行,以标准格式交换数据。
标准的 AI 框架可以为各方面带来好处:
- 技术供应商将能够向开放的市场提供符合要求的AI技术。
- 应用开发者将在开放的市场上找到他们的应用需求。
- 创新将因对新型和更高性能的AI部件的需求而得到推动。
- 消费者将通过竞争性市场获得更广泛和更好的AI应用选择。
MPAI 的 AI 框架(MPAI-AIF)标准规定了能够执行AI产品、服务和应用的 AI 框架(AIF)所需要的架构、接口、协议和 API。MPAI-AIF 的主要特点为基于组件定义了不同部分之间的接口。各组件在可信区运行以确保安全性,并且支持硬件和软件的混合实现,支持分布式和本地执行环境,支持机器学习以及支持类似的框架中的操作和算子。
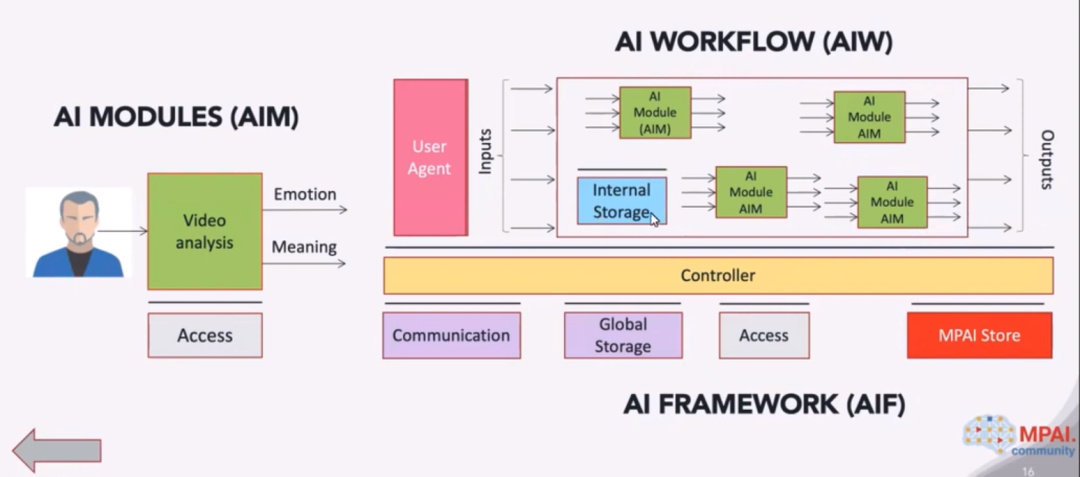
MPAI-AIF 的框图如下图所示。在图中的 AI WORKFLOW(AIW)中,包含了多个不同的 AI Module(AIM)。这些 AIM可以访问共享一个共同的内部存储中的数据。整个流程由一个控制器 Controller 来进行控制。Controller 能够管理一些基本的功能,包括调度以及内部 AIM 之间的通信。Controller 可以控制多个不同的 AIW,并且可以选择性地开启和挂起指定的 AIW 或是 AIM,并提供负载均衡的功能。Controller 同样可以控制每一个 AIM 可以访问和通信的范围。
除了 controller 之外,还包括了一系列控制模块。其中 Communication 模块控制 AIF 中不同模块的连接;Access 模块提供对静态和缓慢变化的数据如领域知识,数据模型等的访问控制;User Agent 提供给外部用户访问 AIF 中的 Controller 的接口;MPAI Store 为用户保存了不同的实现方法以用于下载。
MPEG-AIF 主要有以下特征。
- 支持基于事件和基于端口和通道的单播。
- 消息有两种类型。高优先级信息和普通优先级信息。信息可通过通道或事件进行通信。通信可以是非线性的。
- 控制器可以运行在与 AIW 不同的计算平台上。
- AIW 的 AIM 也可以运行在不同的计算平台上,例如在云端或无人机群上。适当的 API 配置文件允许在不同的计算平台和不同的编程语言上实施。在 AIF 的轻量级实现中也同样包括控制器。
- AIMs 可以是热插拔的,并在变动后立刻注册自己,且支持具有多个控制器的设备群。
基于上下文的音频增强功能(MPAI-CAE)
MPAI-CAE 的发展目标主要为提高与音频相关应用的用户体验。在 MPAI-CAE VERSION1 中,主要考虑了以下四种用例
- 情感增强语音(Emotion-Enhanced Speech,EES):在无情感的语音中加入指定的情感。
- 录音保存(Audio Recording Preservation,ARP):从读头的录像带中提取保存的信息。
- 语音恢复系统(Speech Restoration System,SRS):恢复数字人声轨道的受损部分,为受损人声生成替代品。
- 增强型音频会议体验(Enhanced Audioconference Experience ,EAE):改善电话会议体验。
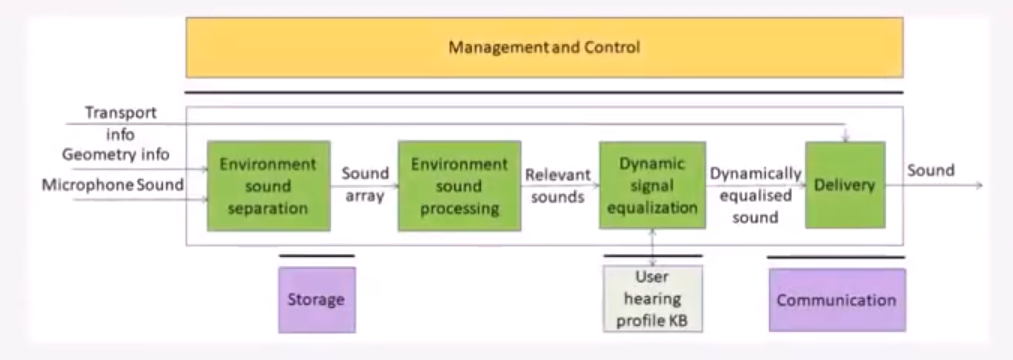
而在 MPAI-CAE VERSION2 中,新增了一个单独的用例为随身携带的音频(Audio on the Go, AOG)。该用例的目标为使得用户在不同的环境中都能够播放高质量音频,并且保持与周围环境的联系。AOG 的实现框图如下图所示。AOG 能够记录位置信息,并从麦克风中提取出环境音进行处理。
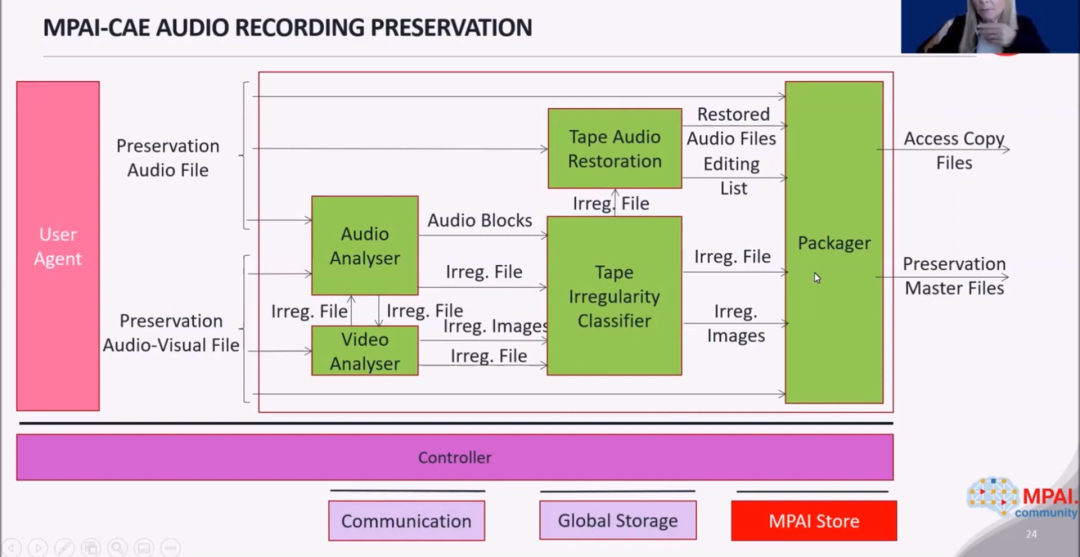
演讲者随后对 ARP 用例进行了仔细的介绍,该用例的具体框图如下所示。在磁带的数字化过程中,获得的磁带的音频信号和视频上可以发现不规则的地方(如载体的损坏、拼接、标记),可以通过人工智能算法对检测到的不正常现象进行分类和选择,选定的不规则因素用于恢复音频信号,该过程也包括在保存和访问录音内容的副本中。
多模态对话 (MPAI-MMC)
多模态对话的特点为使用人工智能来实现一种人机对话的形式,在完整性和强度上模仿人与人的对话。在 MPAI-MMC 标准中,主要包括了 3 个用例。
- 有情感的对话(conversation with emotion,CWE)。与一个由合成语音和动画脸谱构成的机器的对话。
- 多模态问题回答(multimodal question answering,mqa):请求提供关于一个显示物体的信息。
- 翻译一个口语化的文本句子,在翻译后的语音中保留说话者的语音特征。
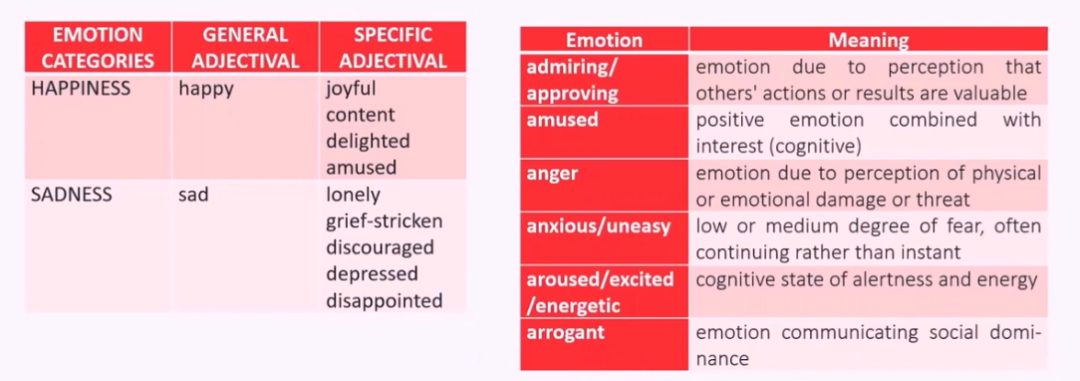
MPAI-MMC 目前支持的数据形式包括了预定义的 Emotion,语音特征以及对象标识符、文本以及视频文件。MPAI-MMC 中定义的层次化情感类型如下所示。
AI 增强的视频编码(MPAI-EVC)
在过去的传统的视频编码中,基于块的混合编码框架几十年来没有明显变化。而在 MPAI 增强型视频编码的任务中,则是利用人工智能的进步来开发视频编码标准,提高编码效率。
MPAI-EVC 是在 MPEG-5 中的 EVC(Essential Video Encoder)标准上进行开发的。EVC 定义了 Baseline 和 Main 两个配置文件,Baseline 配置文件只包含超过 20 年的技术,或以其他方式免费提供给标准使用的技术。此外,Main 配置文件中增加了少量额外的工具,每一个工具都可以被禁用或单独切换到相应的 Baseline 工具上。
在 MPAI-EVC 中,则是通过使用 AI 工具来增强 EVC 的编码性能。主要包括了增强的帧内预测以及超分辨率模块。具体的框图如下图所示。
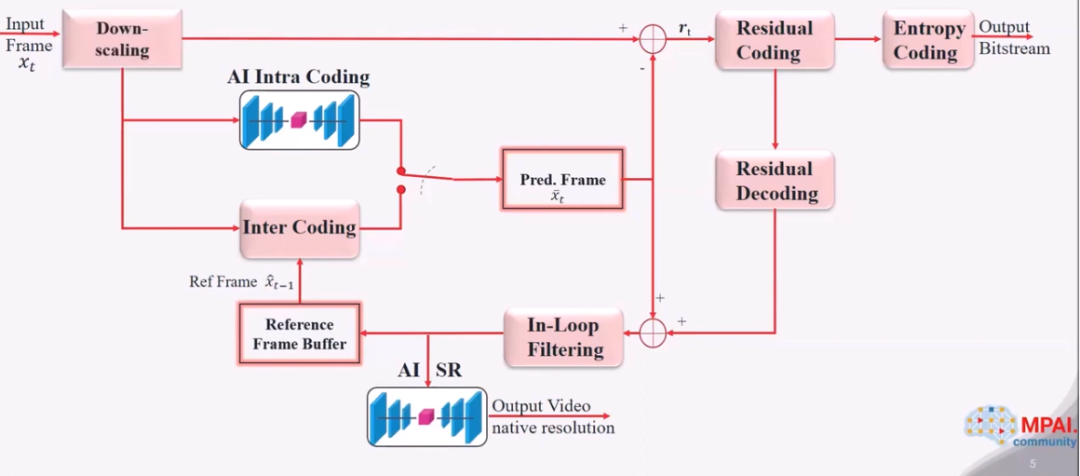
增强的帧内预测
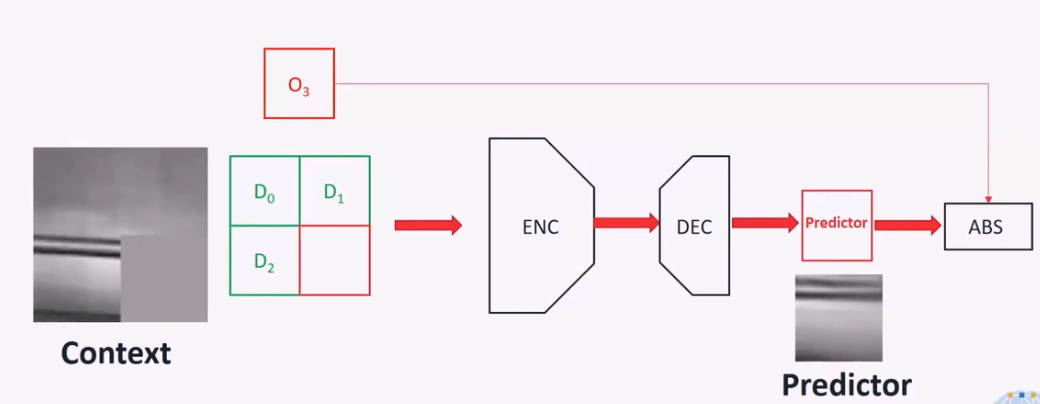
帧内预测可以消除同一张图中的空域冗余,并生成后续编码所需要的预测块。之前已经解码的块则被称为上下文。上下文预测的更为准确,需要编码的残差信息就更少。在 MPEG-EVC 中,将给定上下文,对块的预测过程看做是 Image paiting 问题。通过卷积网络来实现根据上下文对待编码块的预测过程。
对于每个,例如 32×32 的 CU,64×64 的内部预测器上下文被发送到自编码器,自编码器返回一个 32×32 的预测结果。自编码器的输出无条件地取代了 DC 预测器。自编码器输出的比特流是可以被解码的。
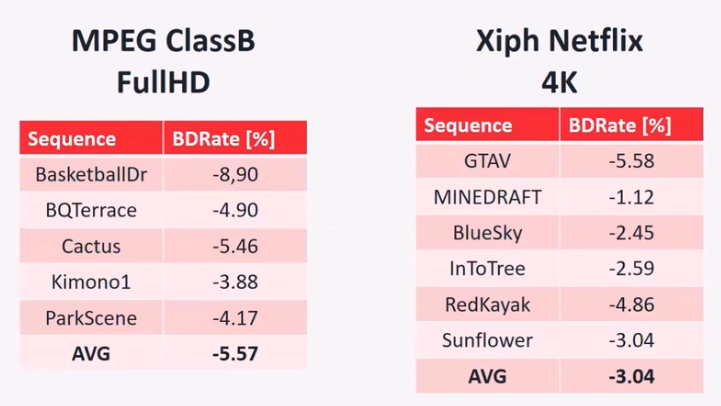
增强的帧内预测可以带来的 RD 性能增益如下图所示。预测的 CU 大小为 32×32 到 4×4。该工具在 FullHD 序列上可以带来约 5% 的性能增益,而在 4k 序列上可以带来约 3% 的性能增益。
该工具在未来发展的挑战主要在于更好的建模和控制模型输出的码率,以及控制卷积网络的复杂度和部署在 FPGA等硬件上。
超分辨率
超分辨率工具的作用是将图像的分辨率按照指定倍数进行放大。在 MEPG-EVC 中,首先对输出帧进行下采样操作,并在后处理过程中使用超分辨率模型将图像恢复到原始的分辨率。
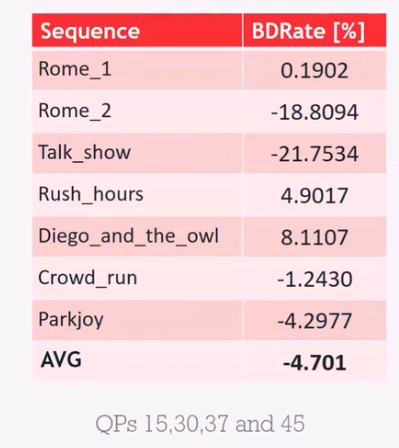
超分工具可以带来的性能增益如下图所示。该工具可以带来约 5% 的性能提升。
未来工作
- 滤波:通过滤除一些高频分量来减小因为编码块导致的块效应
- 帧内预测:使用深度学习架构来细化帧内预测块的质量,并引入新的帧内预测模式来预测新的一帧,并且避免使用额外的 side information。
来源:IBC DIGITAL 2021
主讲人:MPAI
内容整理:张一炜
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
