
本文作者提出了一个精心设计的图像Tokenizer:SEED。它能为大语言模型赋予同时理解和绘制的能力。由于使用量化视觉Tokens的框架在多模态理解和生成方面的表现欠佳,此前关于图像Tokenizer的研究陷入了僵局。在本文中,作者确立了可有效地简化后续与大语言模型对齐的关于 SEED 结构与训练的两个关键原则:(1)图像Tokens应该独立于二维物理修正位置,转而由一维因果依赖性质(1D causal dependency)产生,最后通过与大语言模型中从左到右的自回归预测机制对齐表现出内在的相互依赖性(2)图像Tokens应当能够捕获与单词语义抽象程度一致的高阶语义,并在Tokenizer训练阶段针对区分性和重建进行优化。因此,现成的大语言模型能够通过高效的LoRA调整,结合本文中提出的 SEED 来执行图像到文本和文本到图像的生成。本版本下的 SEED 仅使用 64 个 V100 GPUs 和 500 万个公开可用的图像-文本数据对,在5.7天内完成了训练。本文的研究初步表明了离散视觉Tokens在多模态大语言模型中的巨大潜力。
题目: Planting a SEED of Vision in Large Language Model
作者: Yuying Ge, Yixiao Ge, Ziyun Zeng, Xintao Wang, Ying Shan
论文链接: https://arxiv.org/abs/2307.08041
主页链接: https://github.com/AILab-CVC/SEED
内容整理: 张俸玺
引言
近年来,在海量文本语料库上进行预训练的大语言模型已趋于成熟,表现出在理解、推理和生成各种开放式文本任务上的卓越能力。最近的研究聚焦于进一步利用大语言模型的强大通用性来提升视觉理解和视觉生成任务的效果,统称为多模态大语言模型。先前的工作通过将预先训练的图像编码器(例如CLIP-ViT)的视觉特征与大语言模型的输入嵌入空间对齐来执行开放式视觉QA。GILL通过将其输出嵌入空间与预训练的稳定扩散模型对齐,从而赋予大语言模型图像生成能力。虽然这些研究促进了技术进步,但在新兴能力方面,多模态大语言模型尚未取得像大预言模型那样的显著成功。
作者做了一个大胆的假设:多模态功能出现的前提是文本和图像可以在统一的自回归转换器中互换地进行表示和处理。幸运的是,作者在并行工作中与其他的同类研究工作达成了共识。所有的工作都采用图像到文本和文本到图像的生成任务来展示在一个框架中统一视觉理解和生成的新兴能力。无论是离散还是连续的视觉Tokens,它们的训练范式都可以概括为三个阶段:Visual Tokenizer训练,多模态与训练以及多模态指令调整。虽然同类的并行研究主要强调多模态训练以及多模态指令调整阶段,本项工作则主要聚焦Visual Tokenizer训练阶段。作者认为,适当的Visual Tokenizer可以通过以下方式促进后续多模态训练:(i)简化视觉和文字Tokens之间的语义对齐。(ii)使得多模态数据无需对是视觉Tokens进行特定调整就可启动大语言模型的训练。将图像表示为一系列离散ID自然地与大语言模型地自回归训练目标相兼容。不幸的是,利用离散视觉Tokens进行多模态任务的作品已经不再引人注目,这是因为此类模型通常依赖于超大规模的训练来实现收敛,从而导致大量的训练成本。此外,作者发现现有研究中占主导地位的TokenizerVQ-VAE捕获信息的水平太低阶,无法让大语言模型有效地执行多模态理解任务。现有的图像Tokenizer无法满足统一视觉理解/生成任务和促进多模态训练的要求。
因此,作者提出了一个基于VQ的图像Tokenizer:SEED, 它可以生成具有一维因果依赖性的离散视觉代码以及视觉理解和生成任务所需的高阶语义,如图1所示。通过将离散视觉Tokens标记为新单词并使用映射的视觉代码更新词汇表,现成的大语言模型可以轻松配备SEED。本文中,作者通过调整具有低秩适应器的预训练的大语言模型来有效地与SEEDTokenizer对齐,从而提出了多模态大语言模型。SEED的设计原则是:(1)为什么使用因果依赖性Tokens?现有的视觉Tokens(比如来自于VQ-VAE或CLIP-ViT的Tokens)是使用二维上下文来生成的,这与主流的大语言模型中的单向注意力机制不兼容。因此,作者将二维栅格排序嵌入转换为具有一维因果依赖性的语义代码序列。(2)为什么需要高阶语义?由于大语言模型中的视觉和文本Tokens预计是可互操作的(共享权重和训练目标),因此它们应该包含相同程度的语义(即单词中所固有的高阶语义)以防止不一致。这项工作旨在使用离散视觉Tokens将多模态理解和生成任务集成到大语言模型中,从Tokenizer设计的角度探索了促进模型多模态功能的发展方向。
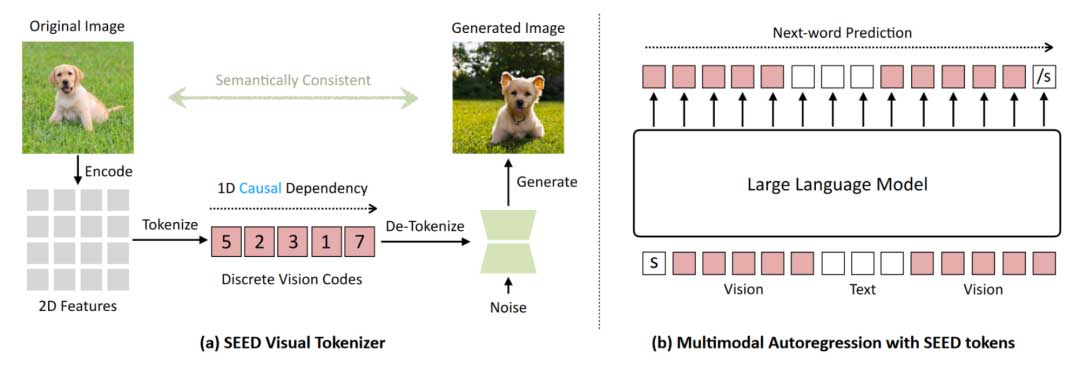
方法
SEED Visual Tokenizer
结构:
在这项工作中,作者引入了基于 VQ 的图像 Tokenizer SEED 以生成具有一维因果依赖性和高级语义的离散视觉代码。具体而言,如图2所示,SEED Tokenizer由ViT的图像编码器、Causal Q-Former、VQ Codebook、Reverse Q-Former和UNet的解码器组成。ViT的图像编码器和UNet的解码器分别直接源自预训练的BLIP-2和SD模型。作者首先训练Causal Q-Former将ViT编码器生成的二维栅格排序特征(16×16 Tokens)转换为因果语义嵌入序列(32个Tokens)。随后,作者训练了一个视觉码本,将因果嵌入离散化为具有因果依赖性的量化视觉代码(32个Tokens)。作者采用Reverse Q-Former将视觉代码解码为生成嵌入(77个Tokens),这些嵌入与预训练的稳定扩散模型的潜在空间对齐。
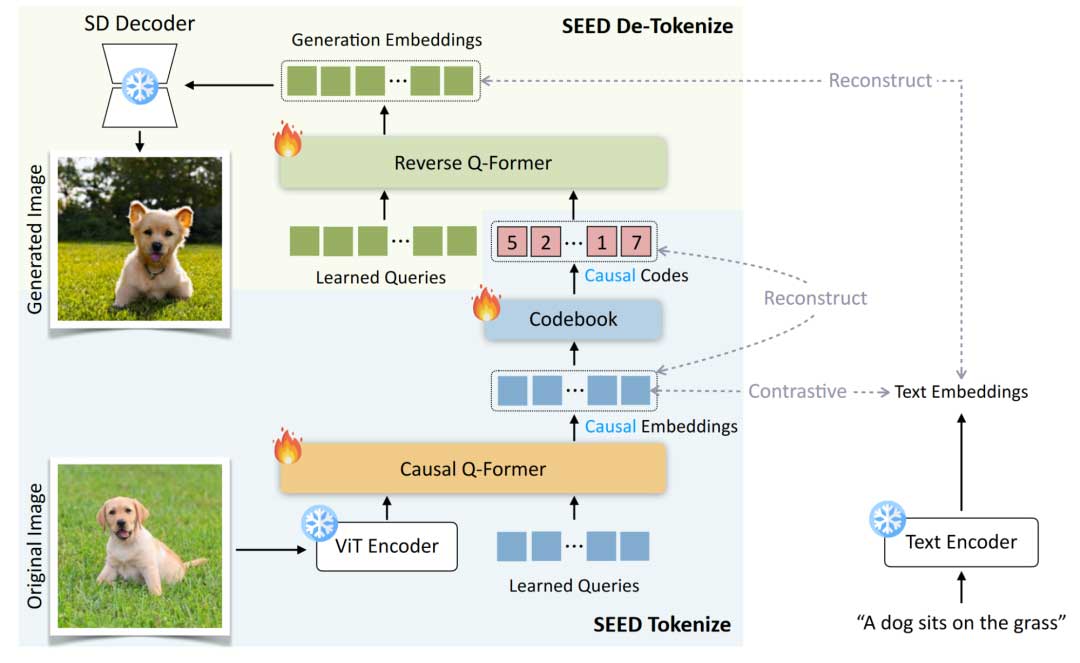
Causal Q-Former(第一训练阶段):
如图2所示,一组可学习的查询嵌入(32个Tokens)和预先训练的ViT图像编码器的特征被输入到Causal Q-former中,以对输入图像的固定数量因果嵌入(32个Tokens)进行编码。具体来说,查询嵌入可以通过带有因果掩码的自注意力层仅与先前的查询进行交互,并通过交叉注意力层与冻结的图像特征进行交互。作者采用对比学习来优化Causal Q-former,该Causal Q-former从预训练的BLIP-2的Q-former上对五百万个图像文本对进行微调。作者使用对比损失来最大化最终因果嵌入与相应标题的文本特征之间的相似性,同时最小化最终因果嵌入与批处理中其他标题文本特征之间的相似性。
视觉量化和去标记化(第二训练阶段):
如图2所示,作者训练了一个VQ码本,将因果嵌入(32个Tokens)离散化为五百万个图像文本对上的量化视觉代码(32个Tokens)。具体来说,量化器在码本中查找每个因果嵌入的最近相邻部分并获得对应的代码。作者使用一个解码器,这是一个多层Transformer,从离散代码中重建连续因果嵌入。在训练过程中,在训练过程中,作者最大化解码器输出和因果嵌入之间的余弦相似度。并进一步采用反向Q-former从离散代码中重建冻结的稳定扩散模型的文本特征。一定数量的可学习查询嵌入(77个Tokens)被输入到反向Q-former中。查询嵌入通过自注意力层相互交互,并通过输出生成嵌入(77个Tokens)的交叉注意力层与因果代码(32个Tokens)交互。在训练期间,作者最小化了SD的生成嵌入和文本特征之间的MSE损失。在推理时,生成的嵌入可以输入SD-UNet来解码真实场景中的图像。
Multimodal Autoregression with SEED Visual Tokens
基于预训练的SEED Tokenizer,作者通过在 OPT2.7B 模型(该模型具有500万个图像文本对,包括CC3M、Unsplash、COCO数据集)上微调低秩自适应模块(LoRA)来呈现 SEED-OPT2.7B。如图4所示,作者进行了图像到文本和文本到图像的自回归预训练,以实现统一的多模态理解和生成。
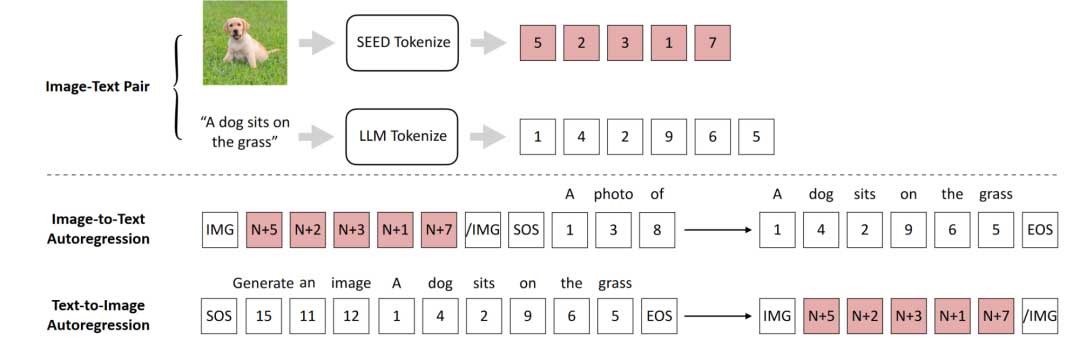
图像到文本的自回归:
作者首先实行图像到文本的自回归,将预训练的 VQ码本的词汇与 OPT2.7B 对齐。具体来说,作者使用全连接层将视觉 Tokenizer 中的因果代码线性投影到与 OPT2.7B 的词嵌入相同的维度。投影的因果代码和 “A photo of” 的词嵌入前缀被连接起来作为 OPT2.7B 的输入。相应标题的文本Tokens被用作生成目标。作者在训练中冻结了 OPT2.7B的参数并对LoRA进行了微调。
文本到图像的自回归:
作者联合实行了图像到文本和文本到图像的自回归,使得大语言模型除了文本 Tokens 之外还能生成视觉 Tokens。对于文本到图像的自回归预训练,前缀 “Generate an image” 和标题的词嵌入被输入到 OPT2.7B 中。来自作者先前预先训练的Tokenizer 中的相应图像的视觉代码被用作生成目标。作者同样在训练中冻结了 OPT2.7B 的参数并对 LoRA 进行了微调,在这时模型的训练目标是预测下一个视觉Token。
在推理时,给出 Prompt”Generate an image”和文本描述,OPT2.7B 自回归地预测视觉Tokens。输出的视觉 Tokens 被输入到 Reverse Q-Former 中进行生成嵌入的操作,最终通过 SD-UNet 对其进行解码来生成逼真的图像。

多模态理解的评估:作者在本文中通过零样本下的图像字幕生成和视觉问答来评估的SEED-OPT2.7B性能。对于图像字幕生成,作者对COCO测试集和NoCaps验证集进行评估。对于视觉问答任务,作者在VQAv2验证集和GQA测试集上进行了评估。如表1所示,与在129兆个图像文本对上训练的BLIP-2相比,在五兆个图像文本对上训练的SEED-OPT2.7B在零样本下的图像字幕生成和视觉问答任务上都实现了可喜的结果。

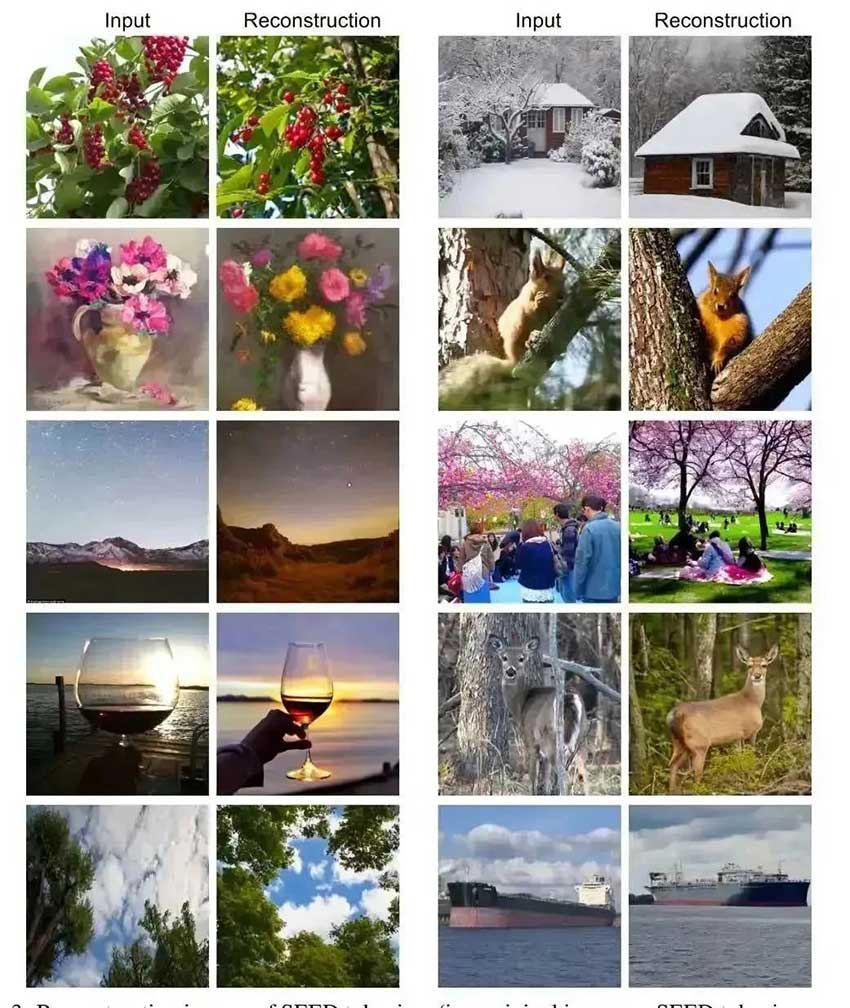
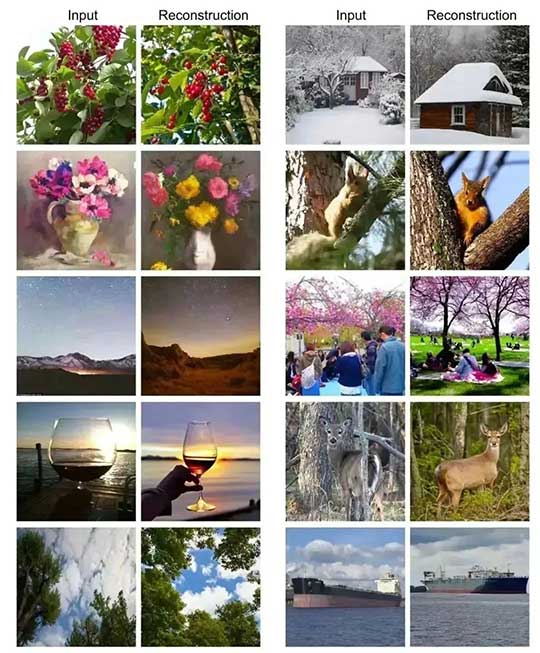
多模态生成的评估:SEED 可以促进视觉Tokens和大语言模型之间的对齐,图6展示了使用SEED-OPT2.7B的文本到图像生成结果的定性示例,这证明了其已经能够在LoRA调整后执行文本到图像和图像到文本的生成任务。
相关工作
用于压缩的多模态大语言模型
随着大语言模型的巨大成功,最近的研究致力于通过利用大语言模型的强大通用性来提高视觉理解能力,进而实现多模态大语言模型,以图实现通用人工智能的设想。先前的工作将与训练图像编码器的视觉特征与基于图像-文本数据集的大语言模型对齐,使得大语言模型能够用文本描述解释视觉信息。然而,这些工作通常使用下一个文本Token的预测作为训练的目标,并且不对视觉数据进行监督,因此只能在给定多模态视觉和语言输入的情况下输出文本。
用于生成的多模态大语言模型
为了赋予大语言模型图像生成的能力,CogView通过重建图像像素来预训练Visual Tokenizer,同时需要以下一个Token为目标对GPT进行微调。其中,图像和文本Tokens被同等对待。GILL则通过学习大语言模型的Embeddings和冻结的与训练图像生成模型之间的映射来实现目的。以上提到的两项工作都旨在利用大语言模型生成图像,但都没有明确针对多模态理解的设计。
Visual Tokenizer
Visual Tokenizer旨在将图像表示为类似于自然语言的离散Tokens序列。先前的工作通过重建输入图像的像素来训练作为Visual Tokenizer的矢量量化的变分自动编码器(Vector Quantized Variational AutoEncoders),这样的Visual Tokenizer仅鞥捕获图像的低阶细节,例如颜色、纹理和边缘等。Beit v2则通过重建来自教师模型的高阶特征来训练语义丰富的Visual Tokenizer。但其来自Vision Transformer的二维特征视觉代码与主流大语言模型中用于多模态生成的单项注意力机制不兼容。
结论
作者在本文中提出一个离散图像Tokenizer:SEED。这一设计基于的前提是,与大语言模型兼容的视觉Tokens应能够捕获高阶语义,且同时可以通过一维因果依赖性进行生成。SEED使得大语言模型可以按照原始文本配方(即下一个单词的预测),通过使用多模态数据进行训练。经过训练的多模态大语言模型能够执行图像到文本和文本到图像的生成任务。更合理的Visual Tokenizer可以大幅度降低多模态大模型的训练成本和复杂性,促进低碳和更大规模的模型训练。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
