
2D 人体姿势估计旨在从整个图像空间中定位所有人体关节。但是想要实现高性能的人姿态估计,高分辨率是必不可少的重要前提,随之带来的是计算复杂度的提升,导致很难将其部署在广泛使用的移动设备上。因此,构建一个轻量且高效的姿势估计网络已经成为目前关注的热点。当前主流的人体姿态估计方式主要是通过2D单峰热图来估计人体关节,而每幅单峰热图都通过一对一维热向量进行投影重构。本文基于这一主流估计方式,研究发现了一种轻量级的高效替代方案——Spatially Unimensional Self-Attention (SUSA)。SUSA 突破了深度可分离 3×3 卷积的计算瓶颈,即降低了1 × 1卷积的计算复杂度,减少了 96% 的计算量,同时仍不损失其准确性。此外,本文将 SUSA 作为主要模块,构建了轻量级的姿态估计神经网络 X-HRNet。在 COCO 基准测试集上进行的大量实验表明了 X-HRNet 的优越性,而综合的消融实验则展示了 SUSA 模块的有效性。
作者:Yixuan Zhou等
来源:ICME 2022
论文题目:X-HRNet: Towards Lightweight Human Pose Estimation with Spatially Unidimensional Self-Attention
论文链接:https://arxiv.org/pdf/2310.08042.pdf
内容整理:王柯喻
方法
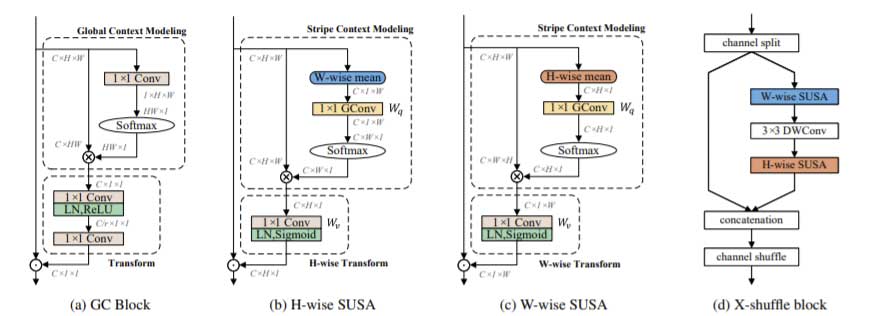
SUSA概述
SUSA模块遵循全局上下文块(Global Context)的设计模式,其详细结构如图1(a)所示,由条纹环境建模(Stripe context modeling)和空间线性变换(Spatially unidimensional transform)两部分组成。对于输入特征图 x = RCxHxW 存在两个空间维度:H 和 W 。因此,我们提出了两个相应的 SUSA 模块:H-wise SUSA 和 W-wise SUSA。如图 1(b) 和图 1(c) 所示,它们在处理不同的空间维度时完全相同。总体上 SUSA 模块可以分为三个步骤:
1. 条纹环境建模
SCM 利用分组矩阵 xq 在单一空间维度( H 或 W )上将特征分组,并输出条纹环境特征。 xq 的计算公式为:

2. 空间线性变换
SUT 通过一个1 × 1卷积核将已经分组的特征进行转换,其中该卷积核通过剩余空间维度上的关注向量来训练。H-wise SUT通过单个1×1卷积核对 fh 进行编码,并输出最终的水平注意力向量 ah。 ah 通过 LayerNorm(LN)在维度 C 上进行归一化,然后由 Sigmoid 作为激活函数。得到的 ah 通过广播操作作为水平注意力向量 (horizontal attention) 乘回 x 。相应地,W-wise SUT 学习垂直注意力向量,并通过逐元素乘法将其与 x 结合在一起。SUT的公式可以写为:
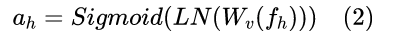
其中 LayerNorm(LN) 为横向维度规范化函数,广播操作 (broadcasting) 为一种操作机制,使得向量的形状匹配并且可以进行元素级运算
3. 特征聚合
利用逐个元素相乘将学习到的注意力向量与输入的特征图进行聚合。
总体而言SUSA公式可以表示为:
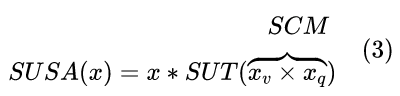
X-HRNet构建
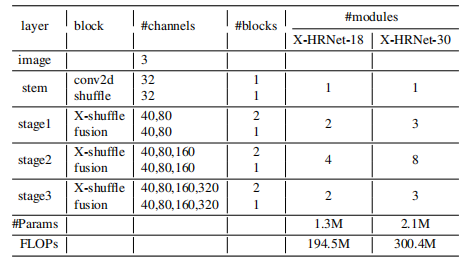
将网络中 Shuffle 模块的 1×1 卷积部分按顺序用 H-wise SUSA 和 W-wise 代替,得到如图2(d)所示的 X-Shuffle。基于此模块,按照HRNet网络结构搭建网络,在保持高分辨率的条件下同时实现了轻量化,即 X-HRNet 网络。其中X代表被估计的十字注意力向量(cross-shape attention vector)。X-HRNet分为三个阶段,每个阶段分别有2、3、4个分支。每个分辨率分支的通道维度分别为C 、2C 、4C 、8C ,其中 设置为40。XHRNet 的骨干架构如表1所示,其中 XHRNet-N 中的 N表示块的数量:
实验
选取COCO测试集对X-HRNet网络进行评估,并与最新技术进行比较。同时进行综合的消融研究,以评估网络中模块的效果。
设定
- 数据集:选取 COCO tran2017 数据集来训练 X-HRNet,该数据集包括57,000张图像和150,000个人体实例。使用 val2017 集和 test-dev2017 集来评估网络,他们分别包含5,000张和20,000张图像。
- 训练:将检测框宽高比拓展至 3:4,并裁剪图像,然后将其调整为256×192或384×288。在区间[0.75, 1.25]内对每个样本进行随机缩放,在区间[-30°, 30°]对样本随机旋转,并进行水平翻转与额外的半身增强。
- 优化:采用 Adam 优化器,初始学习率为2e-3,训练不超过210个时期,同时在第170个和第200个时期时将学习率分别降至 2e-4 和 2e-5。
- 测试:通过平均原始图像和翻转图像的热图来计算最终的热图。通过调整最高响应位置从热图中解码得到关键点的坐标。
- 评估指标:采用基于 OKS(Object Keypoint Similarity)的 mAP(Average Precision score)指标来评估网络。OKS 比较了真实姿势和预测姿势之间的相似度。
结果
1. 对比实验
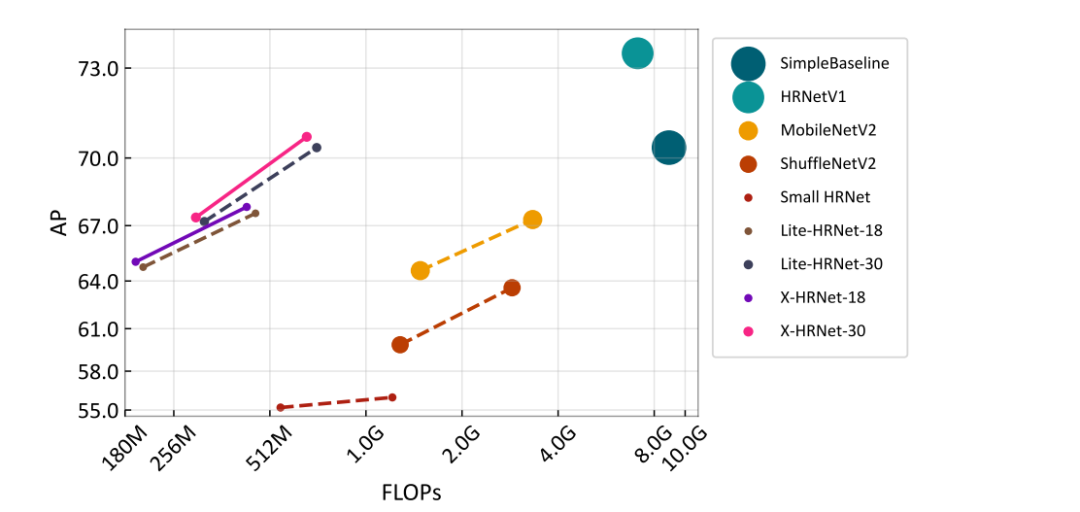
如图2所示,X-HRNet网络在浮点计算方面具有明显优势。与专为分类任务设计的主流轻量级网络 MobileNetV2 和 ShuffleNetV2 相比,X-HRNet 在性能上具有明显优势。与在ImageNet数据集上预训练的 ShuffleNetV2 网络相比,X-HRNet-30 显著提高了7.6个 AP 分数,只需要28%的FLOPs。同时 X-HRNet-18 在性能上也超过了小型 HRNet,只需要35%的FLOPs。证明了SUSA模块在捕捉高分辨率细节方面具有明显优势。
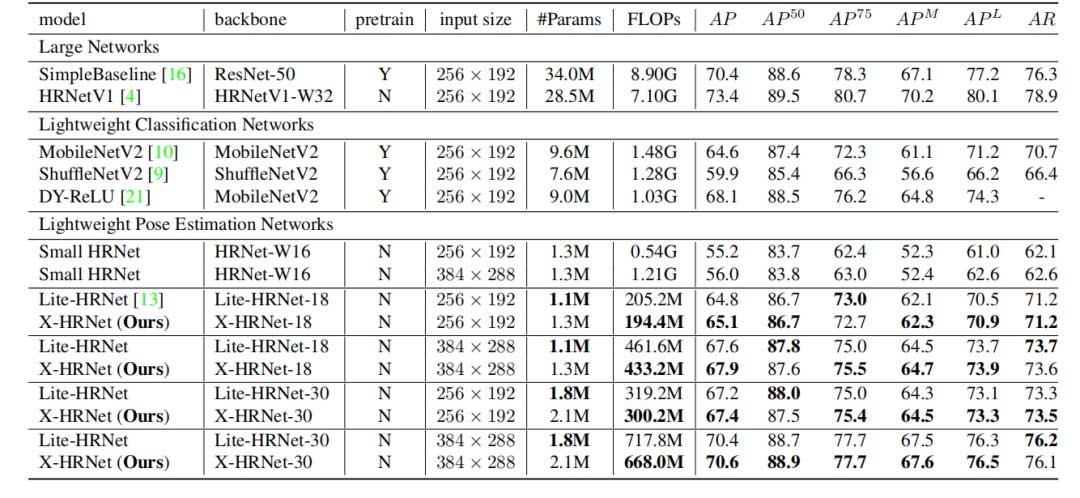
如表2所示,针对不同的输入大小与模型深度,X-HRNet在性能上都全面超过了 Lite-HRNet。与大型姿势估计网络 SimpleBaseline 相比,X-HRNet-30也显著减少了计算复杂性。
2. SUSA 模块的效果
为了 SUSA 模块1×1卷积模块的效果,本文将 X-HRNet 与 Lite-HRNet (WNL-HRNet) 进行了比较,其主要模块是标准的 Shuffle 块。同时在所有Shuffle块中移除了两个1×1卷积,并将得到的网络作为 baseline。如表3所示。
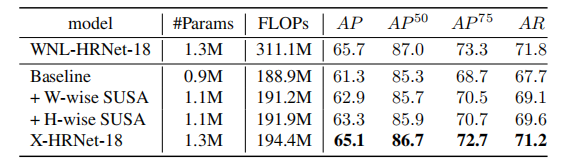
- WNL-HRNet 的AP分数为65.7,当去掉 Shuffle 块中的两个1×1卷积时,分数下降了4.4。对于 Shuffle 块中的每个1×1卷积,FLOPs 减少了61.1M,共减少了122.2M。在 Shuffle 块的深度3×3卷积之后插入一个 H-wise 或 W-wise SUSA后,baseline 的 AP 分别提高了2.0和1.6。而组合使用时 (X-HRNet),性能增加了3.8(大于单独添加的分数总和:3.6)。
- SUSA 模块只消耗了2.7M的 FLOPs,仅为1×1卷积的4%,但 AP 分数达到65,与 NL-HRNet 几乎相同。1×1卷积在跨通道信息交换中起到重要作用,但计算成本高昂。SUSA 模块通过学习交叉形状的注意力向量,只需在单个空间维度上执行卷积计算,发挥了类似于1×1卷积的作用。
3. 消融实验
不同融合方式对 SUSA 的性能具有重要影响。分别在 GC 块和 SUSA 模块上,用加法和乘法融合模块,不同融合方式的消融结果如表4所示。
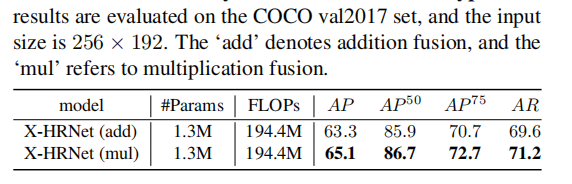
可以发现乘法融合比加法融合更适合人体姿势估计任务。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
