
隐式神经表征 (INRs) 已经成为一种很有前景的表示各种数据模式的方法,包括3D形状、图像和音频。虽然最近的研究已经证明了 INRs 在图像和 3D 形状压缩方面的成功应用,但它们在音频压缩方面的潜力仍未得到充分开发。基于此,本文提出了一项关于使用 INRs 进行音频压缩的初步研究。
来源:ICML 2023 Workshop
论文链接:https://openreview.net/forum?id=AgkMFYcOmM
作者:Luca A Lanzendörfer, Roger Wattenhofer
内容整理:王妍
Siamese SIREN
INRs
INRs 是一类函数,其中一组函数参数 p 描述一个数据样本 D。INR 是在 D 上训练近似函数 f (音频信号函数 T→R,其中 T 为时间输入域,R 为幅度输出域的神经网络。
尽管 INRs 还不能与视觉和音频领域的其他数据压缩方法竞争,它仍然值得进一步研究。INRs 具有一些有趣的属性,例如对输入数据具有分辨率不变性,这意味着存储大小不随输入大小而缩放,并且能够在推理期间使用任意分辨率重建数据。
SIREN
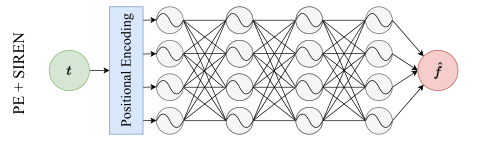
正弦表示网络,简称 SIREN,是一类特殊的 INR 模型,它使用多层感知器 (MLP) 架构,正弦函数作为其激活函数:
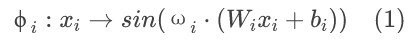
其中,ϕi 为网络的第 i 层,Wi 和 bi 分别为第 i 层的权重矩阵和偏置向量。频率标度超参数 wi有助于 SIREN 更快收敛。设置 wi = 30,在音频的情况下w0 = 3000。
SIREN INRs 在图像、音频和 3D 几何图形上的表现优于标准的 relu 激活 INRs 。
Siamese SIREN
然而,当使用 INRs(包括 SIREN INRs)重建音频时,会出现一个重大挑战。在图像中,噪声可能存在,但通常不太明显。然而,在音频数据中,由于人类听力的对数特性,即使相对较小的重建误差也会以平稳背景噪声的形式被清晰地感知到。
因此,本文提出了一种新的 SIREN 扩展,即 Siamese SIREN。为了去除重建信号的背景噪声, Siamese SIREN 使用了 Noise Reduce ,这是一种计算信号和噪声估计的频谱图的算法。信号和噪声估计用于计算每个频带的噪声阈值。噪声掩模是基于阈值计算的,然后用来去除噪声。
为了构造降噪的噪声估计,假设一个有噪声重构的信号可以线性分解为真信号 f 和噪声分量 ε。因为 ε 的抽样分布通常是未知的,所以必须估计。在相同的信号 f 上训练两个具有不同随机权值初始化的 INR,得到 f 的两个近似值f0 , f1。使用以下规则来估计噪声信号 ε 。
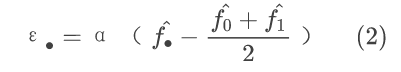
其中 α 是控制噪声估计幅度的超参数。调整 α 对结果有影响,本文所有实验采用 α = 2。ε. 可以为 ε0 或 ε1,本文将 ε0 作为噪声估计输入到降噪中。
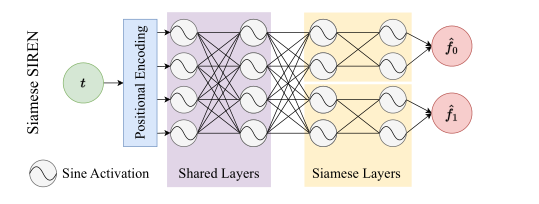
本文提出的 Siamese SIREN 网络不是单纯地训练两个 INR 来估计信号的噪声,从而导致参数数量翻倍,而是合并了一个层的子集,减少了所需参数的数量,同时仍然允许学习信号 f0 和 f1 。这样,每个连体双胞胎既拥有共享的层,也拥有仅针对它的层(连体层)。换句话说,共享层形成 INR 网络的公共主干,而连体层充当两个独立的头,如下图所示。
在减少参数内存占用方面,权值量化策略通过转换网络权值来降低 p 值并提高推理吞吐量。这些通常以 32 位浮点精度存储,但通常可以量化为更小的数据类型,例如 8 位整数。量化方案多种多样,常见的两种方法是:训练后量化 (Post-Training Quantization, PTQ) 和量化感知训练 (Quantization-Aware Training, QAT) ,量化后的 QAT 往往具有较低的重构误差。然而,QAT 需要在训练时成为网络的一部分,或者在训练非量化模型后进行微调。PTQ 可以在训练后应用,不需要再训练网络,代价是重建质量稍差。本文使用 PTQ,因为 PTQ 误差不会显著影响主观信号质量。
实验
实验设置
数据集:GTZAN 和 librisspeech 数据集。GTZAN 包含 10 种不同流派的 1000 个音乐片段,每个 30 秒。librisspeech 采用了 train.100 中的 14 秒的英语朗读文本的音频片段。本文以 22050 赫兹的采样率裁剪每个音频片段的前 10 秒。
评估指标:ViSQOL ,近似于主观听力测试,并产生参考和测试信号之间的平均意见分数。CDPAM ,近似于两个信号之间的感知音频相似性。PESQ 和 STOI ,测量信号中语音的感知质量和可理解性。
实验结果
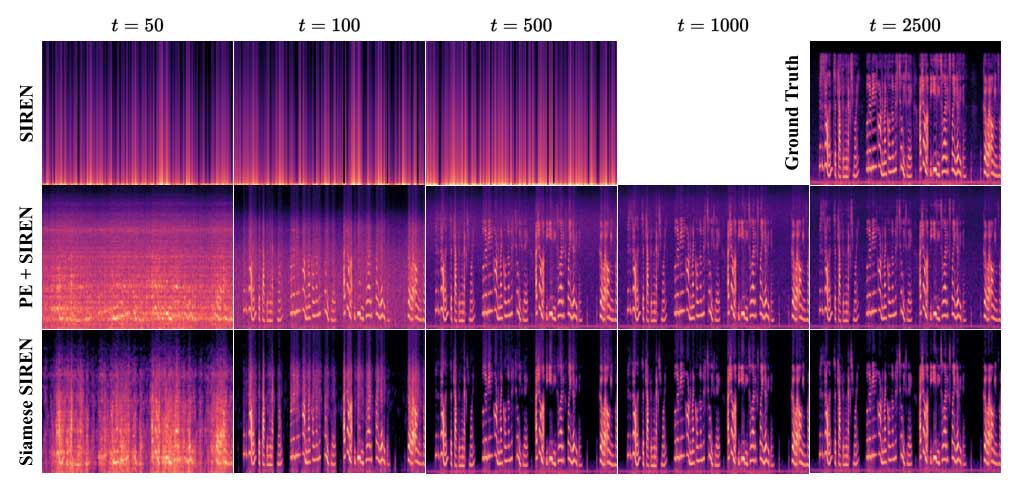
没有位置编码 (PE) 的 SIREN 在量化后无法再现数据。PE + SIREN 能够再现带有噪声的信号。Siamese SIREN 可以使用比 PE+SIREN 更少的参数成功地估计和去除背景噪声。

表 1 显示了原始 SIREN 和 Siamese SIREN 之间的消融研究结果。可以看到 Siamese SIREN 在 3 个指标上得分最高。
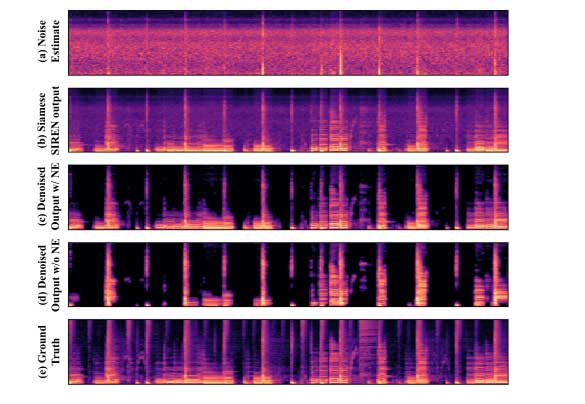
对噪声估计进行消融研究,当不提供噪声估计时,可以观察到更明显的截止,特别是对于音乐信号。并且信号保真度的最大差异来自于重建——量化后的信号主观上只是稍微下降了一点。

在随机 librisspeech 样本上评估层共享的效果,发现参数数目对信号的重构质量有很大影响,这表明在减小网络规模和保持重构质量之间存在权衡。进一步实验表明,保持网络的大部分共享,只将最后一层分割成连体头,可以实现最佳的质量-尺度权衡。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
