
高度逼真的面部动画生成需求量很大,但目前仍然是一项具有挑战性的任务。现有的语音驱动面部动画方法可以产生令人满意的口部运动和嘴唇同步,但在表现力情感表达和情感控制的灵活性方面仍存在不足。本文提出了一种基于深度学习的新方法,用于从语音生成富有表情的面部动画,可以展示出具有可控情感类型和强度的广谱面部表情。我们提出了一种情感控制模块,用于学习情感变化(例如类型和强度)与相应面部表情参数之间的关系,使得情感可控的面部动画成为可能,其中目标表情可以根据需要连续调整。定性和定量评表明,我们的方法生成的动画在面部情感表达方面更加丰富,同时保持准确的嘴唇运动,优于其他最先进的方法。该工作由维多利亚大学人工智能与数据科学中心和清华大学语音与音频技术实验室(SATLab)合作完成,获得ICME 2023 3DMM Workshop的最佳论文奖。代码已公开在github项目网页上。
3D语音驱动的动画合成-导言
语音驱动的面部动画旨在模仿基于声音音轨所携带的信息而产生逼真的面部运动。与2D图像的动画化相比,对3D模型进行调节直接适用于大多数3D应用,如3D游戏和视觉后期效果。目前尝试探索音频与3D面部运动之间的依赖关系的已有工作,大多数侧重于下半部分脸部和嘴唇的运动以及它们与语音的同步。尽管它们能够产生可信的基本发音相关的面部运动,但在合成面部表情,尤其是情绪的表达方面仍然有很大的不足之处。
仅基于音频实现情感动画是一项具有挑战性的任务。尽管对于同一人的声音产生和嘴唇运动之间的依赖关系是确定性的,但它们与不同情感类别和强度的表达之间的依赖关系却具有强混淆性。对于不同用户,同一情感的传达方式有许多不同的个性化方式。这种固有的多样性使得神经网络难以精准的根据音频输入处理情感的变化,即使提供长时序的信息。现有研究尝试从语音中提取情感特征,并将其隐式嵌入到神经网络的学习中以实现情感合成。然而,由于训练数据的限制,已有的解决方案不可避免地具有过度平均化的问题,从而导致表现力受限。实际上,我们发现,即使提供最具表现力的语音作为输入,现有方法生成的动画仍然无法实现高表现力的情感动态合成。
在这篇文章中,我们提出了一种新方法来实现可控情感的面部动画。与从音频中恢复嘴唇运动不同,我们的方法能有效增强情感表现力,并允许调整情感效果的强度,以满足动画师的需求。我们提出了一个情感控制模块,包括一个情感预测网络和一个情感增强网络,以显式的建模情感变化与相应面部表情参数之间的关系。基于图像的情感识别模块被用来生成情感信息,作为先验信息来引导训练过程。在推理过程中,使用指定的情感作为条件将其应用于语音驱动的面部动画,以实现情感增强和定制。通过显式建模情感,我们的系统可以定制情感类型和强度值,使得用户(动画师)使用更加友好。我们的方法在合成可控情感的面部动画方面表现出又是的同时又能保持高精度的嘴唇同步,优于现有技术。
高表现力可控语音驱动动画合成
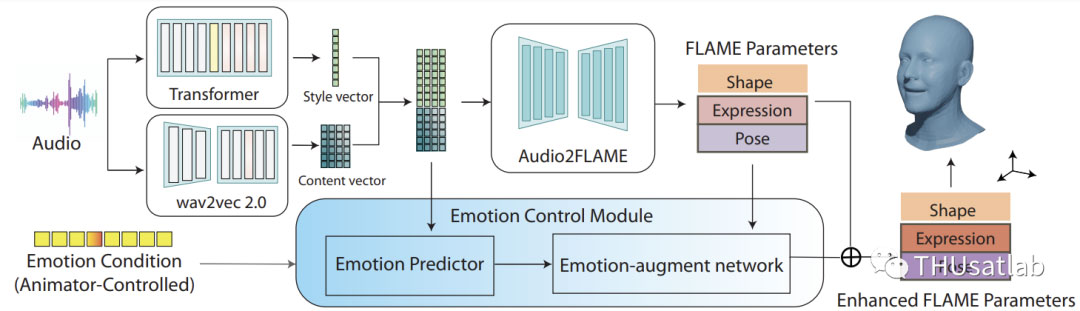
我们提出的网络(结构如图1所示)从输入音频中估算使用FLAME参数表示的面部运动。给定某时段音频段及其相邻帧时,首先分别由wav2vec2.提取局部性的内容向量特征和一个Transformer编码器提取全局风格向量特征,然后它们连接在一起通过Audio2FLAME模块预测FLAME参数。Audio2FLAME模块是一个多层CNN网络。预测的FLAME参数,包括表情参数,位姿参数,形状参数,被转换为3D网格作为输出。在这个阶段,重点将主要放在嘴唇同步上,并确保口部运动合成的精确性。
我们引入了一个情感控制模块,包括一个基于双向LSTM网络的的情感预测器,串联一个Embedding层,用于根据Audio2FLAME模块生成的音频特征以及用户自定义的情感向量生成与情感相关的潜在特征(情感特征向量)。此外,我们还引入了一个基于CNN网络的情感增强网络,根据情感特征来增强FLAME参数的表现力,将Audio2FLAME模型预测的FLAME面部参数映射为情感增强的面部参数。我们以残差方式将情感增强网络纳入主干网络,使得在保留与内容相关的表达的同时,更加针对性的优化与情感相关的表达。通过这种方式,用户可以明确地设计帧级别的情感强度和类别,有效的调节动画输出。
情感预测及控制网络
情感控制合成的核心挑战在于使模型不仅能够适应情感状态,还有情感强度的变化,以允许直接的强度调整。我们提出的训练和推断流程如图2所示。
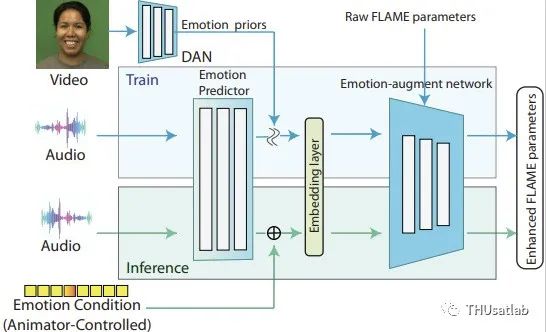
在训练阶段,为了让网络更好的学习输入中的情感变化,我们利用基于图像的情感识别模型来获取帧级别的情感信息,作为情感的先验信息,以促进模型的训练。我们使用了Weng等人提出的DAN模型,但该模型也可以由其他类似的模型替代。我们假设从2D视觉图像解码出的情感特征比从音频中获得的更可靠和信息丰富,更有益于模型的学习。
然而,来自DAN的情感分类概率不能表明情感的强度。相反,我们发现情感识别网络的最终softmax层之前的情感logits,包括七种情感的七维向量,如快乐、愤怒等,与感知到的情感强度高度一致。因此,我们将它们用作模型训练的情感先验,并与用户的情感控制向量相结合。在我们的实验中,我们发现情感logits向量不仅在情感合成方面是有效的,并且可以很好地与情感类别和强度的调整配合使用。情感增强网络对于来自DAN模块的情感先验的预测误差具有鲁棒性,并可以从中生成鲁棒的情感表达。
在推断阶段,情感向量先验是通过一个双向LSTM网络从音频中提取出来的,然后通过自定义的情感类别和强度进行修改。双向LSTM网络是通过最大化音频和视频之间的情感先验之间的互信息来进行训练的,其中以图像为基础的情感先验被视为伪基准。用户提供的情感条件将被转化为一个取值范围从0到1的one-hot向量,然后添加到分散的基于音频的情感先验中(段级均值归一化),从而生成最终的情感先。
情感增强网络:
在输入情感增强网络之前,情感先验将通过一个嵌入层转换为情感特征向量,以驱动3D面部表情增强。嵌入层是一个可学习的2D矩阵,在训练过程中将进行优化。通过与学习到的嵌入矩阵相乘,7维的先验向量将转换为128个情感特征向量,然后输入到由CNN块构建的情感增强网络中,以实现情感引导的面部表情增强。为了在嘴唇同步和情感表达之间达到适当的平衡,我们以残差方式添加了情感增强网络。从Audio2FLAME中提取的原始面部参数具有较好的嘴唇同步。原始面部参数与ground truth之间的差距主要是由于它们不同的情感表达引起的,残差结构使得增强网络更能有效地学习情感引起的差异。
损失函数:
顶点位置损失以及嘴型损失函数加权相加的损失函数被用来训练整个模型。我们将预测的FLAME参数转换成3D网格,然后计算转换后的顶点与实际顶点之间的L1差异然后,将一个顶点蒙版应用于网格,以覆盖前脸区域并排除耳朵和眼睛。为了确保嘴唇同步,我们选择顶部、底部、最左侧、和最右侧顶点的位置,并计算嘴巴的高度,和嘴巴的宽度,作为形状描述。使用实际嘴巴形状和预测的嘴巴形状之间的高度和宽度的L1距离作为嘴巴形状损失。详情见论文。
数据库设置
手动标记的具有丰富情感多样性的3D数据集有限。我们的模型使用包含丰富情感演讲、视频以及3D数据集进行训练,其中包括VOCASET(3D)和CREMAD(2D)。对于2D CREMAD数据集,使用了EMOCA方法来从2D图像重建3D面部模型如图3 所示,并提取FLAME参数作为ground truth。

实验
情感动画控制:根据用户的控制实现3D情感面部动画是我们方法的关键贡献之一。图4显示了针对”幸福”和”恐惧”情感的可控面部动画结果,强度分别为0.5、0.75和1.0。所有示例都由相同的音频输入驱动。结果表明,受相同音频输入驱动,我们的模型可以生成多样的情感面部动画效果,显示出用户的情感定制。生成的面部表情受到用户的改变和音频输入的影响。

具体来说,使用相同的音频输入,嘴巴在恐惧情感中上扬而不是在幸福情感中下降。连续的情感强度变化也可以有效的生成表情的变化。例如,在“恐惧”情感动画中,嘴巴张得更大,嘴角随着情感强度从0.5增加到1.0而向下移动。与“幸福”情感类似,对于强度为1.0,嘴角和脸颊会上扬,而对于强度为0.5,它们则会下降到中性关闭。通过我们的情感可控方法,用户可以通过指定所需的强度值在任何关键帧上编辑动画而无需额外准备,这比传统方法更加直接和高效。
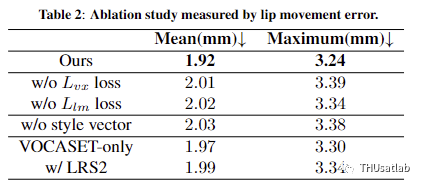
SOTA对比:我们将我们的方法与最先进的语音驱动面部动画方法进行比较,以展示我们的方法在情感合成和嘴唇同步方面的性能。我们选择了Pham等人和Chun等人的研究来进行情感合成比较,以及VOCA和FaceFormer来进行嘴唇同步比较(分别表示为[Pham17]、[Chun21]、[VOCA19]和[FaceFormer22])。

情感合成:图5展示了具有“愤怒”情感的面部动画生成示例。我们观察到[VOCA19]和[FaceFormer22]显示出准确的嘴唇运动,但表情偏中性。而我们的方法可以在不牺牲嘴唇同步和口语内容的可理解性的情况下增加额外的情感变化。在我们的结果中,眉毛下垂,脸颊收缩出现,嘴巴的张合程度根据情绪的波峰和波谷而变化。[Pham17]可以生成一些情感表达,但嘴唇运动不如我们的准确,上半脸的动态非常有限(几乎静止)。[Chun21]提供了具有精确嘴唇同步的情感表达,但由于情感模板是手动给定的,并且均匀应用于所有帧,因此生成的结果在情感表达上受到限制。情感动态方面,我们的动画具有更多的情感波动,看起来就像真实人类的表情,尤其是在上半脸区域(请参见开始和结束帧)。另外,我们的方法还能够将情感从一个身份转移到另一个身份,这得益于FLAME方法对形状和表情的解耦,而[Chun21]和[Pham17]则不具备这一能力。
嘴型同步:嘴唇同步方面,对于语音驱动的动画来说,准确的嘴唇运动对于传达内容信息至关重要。为了在嘴唇同步方面进行公平比较,我们使用了从Audio2FLAME中得到的FLAME参数并与其他先前方法进行定量比较。使用的测试数据与FaceFormer使用的数据相同,包括来自VOCASET的两个主题的数据,每个主题包含20个句子样本。
为了避免引入不同方法输出的不同网格之间的额外对齐错误,我们在进行度量计算之前执行线性的3D变换,以使它们具有可比性。在对齐之后,我们均匀选择了嘴唇周围的24个关键点顶点,并计算它们与ground truth的距离作为嘴唇同步的测量。表1显示,与所有其他方法相比,我们的方法取得了最佳结果,证明了我们提出的流程能够生成良好的嘴唇同步以及增强情感。其中,“RandInit”模型为随机初始化的未训练模型,所以精度最低。以它用作参考来对不同训练方法带来的改进进行说明。
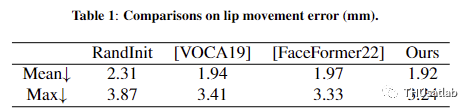
消融实验:我们进行了去除损失项、网络组件和训练数据集的实验,以了解它们的贡献。表2总结了我们提出的模型在没有顶点位置损失、没有嘴唇形状损失和没有从Transformer编码器中提取的风格向量的情况下的效果。我们观察到,顶点位置损失和嘴唇形状损失都有助于嘴唇运动的准确性。去除其中任何一个都会导致错误指标的增加。风格向量也有助于网络捕捉来自音频输入的长上下文特征,并提高嘴唇同步。
我们还尝试了不同的训练数据集,以研究不同训练数据的影响。仅使用3D VOCASET数据集会降低嘴唇运动的准确性。我们还研究了LRS2数据集,该数据集包括来自BBC电视的3000个肖像视频剪辑,其中包含各种主题、背景噪音和环境。尽管结果在实验数据集上没有提高嘴唇运动的准确性,但我们观察到它改善了我们模型在wild test中的泛化能力。
我们还在有情感控制模块和没有情感控制模块的情况下对网络结构进行了定性比较。图5显示了基于Auido2FLAME生成的FLAME参数的结果(标记为Ours (w/o ECM))和情感控制模块的结果(标记为Ours)。我们可以看到,与没有情感控制模块生成的中性动画相比,我们的方法可以通过情感控制模块提高动画的表现力,实现更多的情感表达。
论文链接:
https://www.computer.org/csdl/proceedings-article/icmew/2023/131500a387/1PYLMSYw8mc
https://arxiv.org/abs/2301.02008
指导教师简介:赵军红博士,清华大学电子系语音与音频技术实验室联培博士毕业,现任新西兰惠灵顿维多利亚大学人工智能与数据科学中心研究员 (Research Fellow)。主要研究方向包括人工智能和机器学习及应用,在语音、图形图像智能处理相关领域的重要国际会议及期刊发表论文20余篇,包括IEEE TVCG, ISMAR, ICASSP 等。Email: junhong.jennifer@gmail.com。
作者:赵军红
来源:THUsatlab
原文:https://mp.weixin.qq.com/s/HxEAJzOJwjylE0IQQHO7bg
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
