
在线视频领域的繁荣离不开创作者在内容生产环节的辛勤耕耘。视频既是信息得以高速传播的有效载体,也是创作者的劳动成果,本质上也是一种虚拟资产。随着版权意识的崛起,越来越多的创作者和观众都在为保护版权做着不懈努力。然而整个版权环境的建立需要一定的过程,在此期间存在着大量的侵权行为,如对视频未经授权的盗用、剪辑、跨平台间的搬运、未经许可的商用行为等等。同时,对侵权行为的查验、举证、界定等环节都需要耗费大量的人力物力,并可能存在创作者较难处理的技术及法律难点,导致维权本身变成一个成本极高却收效胜微的事情,削减了版权所有者的创作热情。
目前主流视频网站会在视频上添加明文水印,例如在视频右上角贴上平台的logo来声明视频的版权,这是一种非常直接且有效的手段。但是针对这种明文水印,有基础视频处理经验的人只需要对视频画面进行一定程度的裁剪就能够轻易去除,更有甚者会采用目前已经非常成熟的AI去明文水印的方法进行抹除。可以看出,版权保护与侵权行为始终进行着的攻防战,也正是这个攻防过程促进了视频水印技术的不断发展。

除了以上这种明文水印的方式,还有一些基于传统图像处理方法的不可见水印算法,例如在空域上做像素微调的最低有效位(Least Significant Bit,LSB)算法、以及在频域内嵌入水印信息的DWT-DCT算法等等。传统方法在对抗更复杂的攻击方式上会显得非常无力,例如将某一个视频下载下来再上传到其它平台,一旦触发了其它平台的转码操作,那么这些水印信息就会被轻易地抹除掉。此外如果传统方法想要抵抗更强的降质攻击,势必导致加水印后的画面质量变差,产生肉眼可见的伪影噪声,破坏画面观感。
为了克服传统水印技术的诸多弱点,学术界和工业界开始探索基于AI的水印隐写手段。AI水印相较传统方法更为鲁棒,并且对画面质量的影响非常小,目前主流的AI水印算法已经能够抵抗典型攻击,且埋藏水印前后的视频画质无法被肉眼区分。然而基础的AI水印算法仍有一个致命的缺陷,水印编码和解码效率不高,这导致我们短时间内无法对大量的视频添加水印,影响视频的及时发布,也无法进行大规模鉴权,极大的限制了AI数字水印的应用范围。为此,我们设计了一套精巧的AI数字水印解决方案,它既能保证对典型攻击方式的高鲁棒性,又能保证高质量的视频画质,并且从效率和成本上具备可大规模应用的特点。
一、数字水印的相关背景
1. 一般流程
数字水印涉及到的流程可以分为加水印、信道传播和解水印三个阶段,分别对应版权声明、版权受侵犯和版权维护。针对视频的数字水印,与图像数字水印的处理方法类似,即对视频帧进行加水印和解水印操作。以下所述的图像水印也指代视频水印。
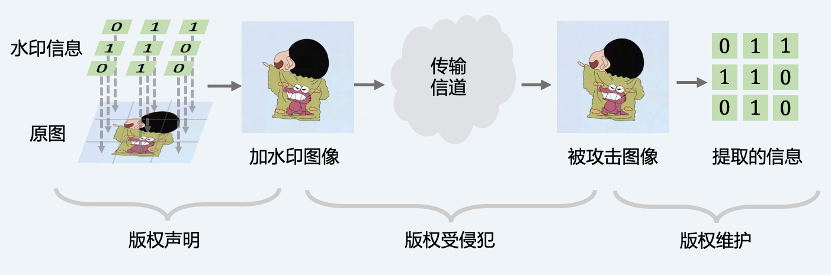
如图2所示,原图的版权所有者通过加水印算法将含有版权信息的水印嵌入原图中,得到加水印图像。加水印图像被发布至互联网,在传播过程中该图像会受到各种扰动,如第三方平台的压缩、盗用者的恶意篡改等,图像和水印信息都会因此发生改变。版权所有者发现版权受到侵犯并决定维护版权,可以将被攻击的图像进行解水印操作,将提取的版权信息作为证据提交法务机构。
2. 目标
数字水印的主要目标有两个:不可见性(invisibility)和鲁棒性(robustness)。不可见性指加水印的操作不影响图像的视觉质量,肉眼无法辨别图像是否添加过水印;鲁棒性指加水印图像经过干扰后仍可以被准确地提取出水印。不可见性要求对原图的改动尽可能小,此时水印信息很容易在传播中被修改、抹除。鲁棒性则需要对图像的改动足够大,从而在经历各种干扰后仍能保留足够的特征,进而可以准确地提取出水印。这两个目标相互制约,所以寻找一个合适的平衡点也是数字水印算法的难点所在。
二、数字水印的算法设计
为了实现数字水印的不可见性和鲁棒性的目标,我们设计了一套基于深度学习的端到端水印算法。以下从模型网络结构、降质层和损失函数分别阐述各部分的原理。
1. 模型网络结构
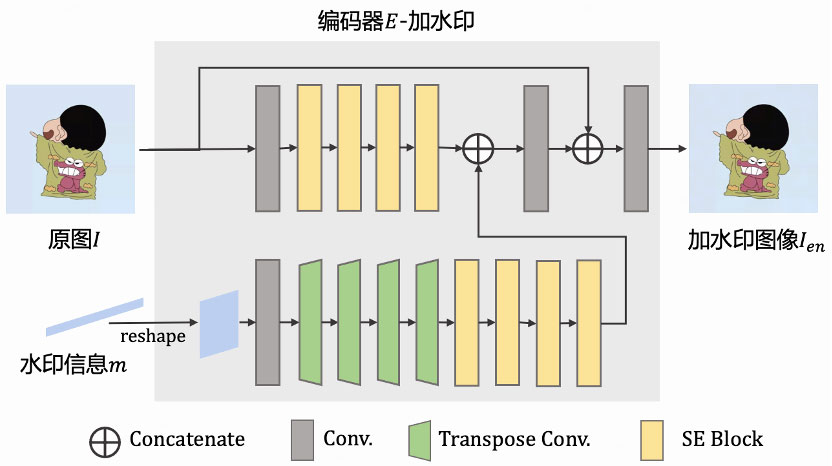
数字水印网络包含两个模块:水印编码器和水印解码器。编码器负责将水印信息嵌入原图中,得到加水印的图像,解码器负责从需要鉴权的图像,即被攻击的图像中提取水印信息。
编码器的具体结构如图3所示,原图经过卷积和SE Blocks提取特征,水印信息reshape成二维张量后通过反卷积和SE blocks提取特征,两路特征空间维度一致,然后在通道维度进行拼接后融合图像和水印特征,实现加水印操作。
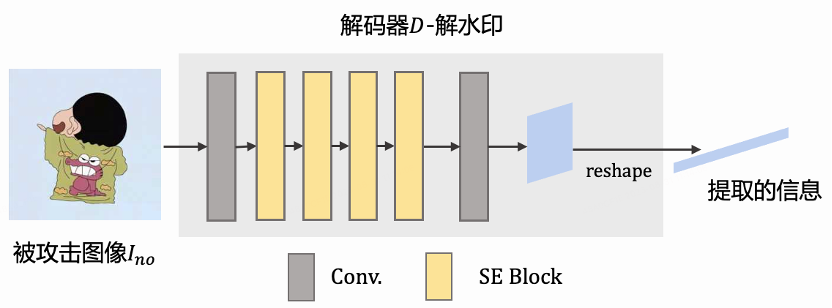
解码器结构如图4所示,加水印图像在开放世界中会经过某种干扰,变成被攻击图像,被攻击图像经过卷积层和SE Blocks提取特征,再使用一层卷积将特征通道降维至1,最后将该特征flatten成一维向量,从而提取出水印信息。
2. 降质层
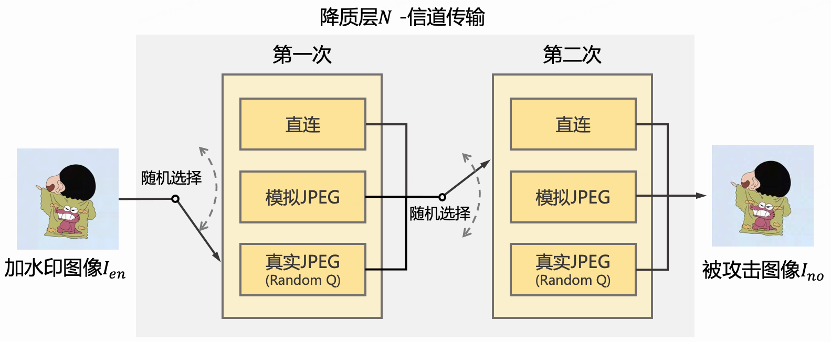
降质层在训练上述模型时应用在水印编码器和水印解码器中间,用来模拟版权受侵犯这个阶段。降质层的引入,可以大大提高模型的泛化能力,提高应对开放世界各种攻击的鲁棒性。在某一类型降质上设计和训练的水印算法难以在其他差别较大的降质上泛化,因此如何设计模拟实际使用场景的降质层成为水印算法的关键。对视频而言,无论是录屏还是平台转投,都涉及到压缩过程,因此拥有对压缩攻击的鲁棒性是水印算法的必要能力。
具体而言,这里的压缩攻击指的是图像在压缩和解压缩之后发生的像素损失,诸如JPEG、H.264这类主流的有损压缩。在这种有损压缩过程中,图像会首先变换至DCT域,然后对DCT系数进行量化,压缩对图像内容的干扰正来源于该量化操作,并且所有主流的有损压缩算法的干扰模式(pattern)是相似的,使用其中一种压缩算法参与训练可以在其他的压缩算法上也取得较好的鲁棒性,因此我们在降质层中引入最为广泛的JPEG压缩算法。压缩攻击最大的问题在于压缩算法中的量化操作是不可微分的,这个问题阻碍了端到端训练时水印编码器梯度的反向传播。对于该问题有两种解决方案:
使用可微的模拟JPEG算法对量化进行近似,由于压缩时量化更多集中于8×8或16×16 DCT系数的高频,因此可以通过将高频系数置零达到模拟量化的目的。但由于近似量化和实际压缩还是有差距的,这种算法对实际压缩的泛化性欠佳。
使用真实JPEG算法,采取两阶段的训练:第一阶进行端到端无攻击训练,水印的编码和解码模型收敛后,将第一阶段的模型参数作为第二阶段模型的初始化参数,然后固定编码器,只训练解码器。但由于第二阶段的编码器参数是固定的,训练收敛时得到的是次优解。
为了提高模型抵抗真实JPEG压缩攻击的能力,同时又能端到端训练水印的编码和解码模型并使之趋近整体最优解,这里将上述两种方案结合以达到更好的效果:每一次训练迭代过程中随机从【直连(无攻击)、模拟JPEG和真实JPEG】三者中选取一种攻击方式,并训练网络参数。
由于JPEG和其他压缩算法势必存在一些差别,使用单一的质量系数(quality factor)训练,网络容易过拟合至该单一压缩场景,并且实际场景中可能受到的压缩编码参数也是不固定的,因此我们将真实JPEG的质量系数设置为从区间[10, 90]中随机采样。进一步地,带水印图像还可能经历不止一次的压缩,我们将一次压缩攻击拓展为两次来模拟真实的盗链转码过程。如图5所示,相比单一质量系数的单次JPEG压缩,降质范围得到有效扩充,模型对多种压缩攻击的鲁棒性得以有效增强。
3. 损失函数
学术界关于数字水印的损失函数一般包含水印编码器的图像相似性约束和水印解码器的水印信息相似性约束。
编码器将水印信息 m 嵌入原图I中,得到加水印图像 Ien 。为了保证不可见性,基于深度学习的水印算法通常使用MSE Loss令输入输出图像接近:
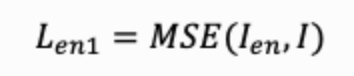
并使用对抗损失使得加水印图像的分布与自然图像的分布一致,视觉上难分彼此:
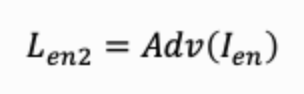
解码器 D 从被攻击图像 Ino 中提取水印信息 m’。为了保证提取精度(鲁棒性),使用MSE Loss令水印信息和提取信息接近:
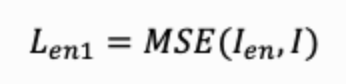
编码器损失 Ien1 会优化编码器的参数,其趋向于让编码器的输出接近于原图。解码器损失 Ide 也会影响编码器的参数,其趋向于让编码器生成显著的特征从而易于被解码器识别。但是显著的特征和趋近于原图是相矛盾的,所以一味地最小化 Ien1 和 Ide,二者会相互竞争、此消彼长,导致训练十分不稳定,并且难以确定模型的最优点。针对这种矛盾的情况,我们引入了如下两种损失函数改进算法的性能:
- Target PSNR Loss: 我们设定一个经验的PSNR值 p0 作为不可见性的最终目标,当PSNR在训练中逼近该值,有关不可见性的损失值接近于0,PSNR会稳定在 p0 附近。模型的优化会侧重于水印提取的精度,选择模型时只要以提取精度为衡量准则即可。我们使用该Loss代替原有的 Ien1 ,
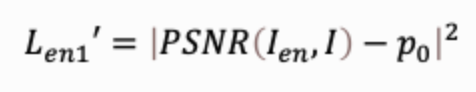
- LPIPS Loss[1]:使用 Ien1′和 Ien2 的结果仍会有一些视觉瑕疵,为了进一步提升加水印图像的视觉质量,我们使用LPIPS Loss在卷积神经网络感知空间约束加水印图像和原图接近,
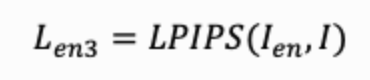
LPIPS由图像的神经网络特征映射得到,是一种更贴近人眼观感的衡量指标。将LPIPS作为Loss,可以使加水印图像在观感上更接近原图,提升视觉质量。
那么训练中总的损失函数L可以写为:
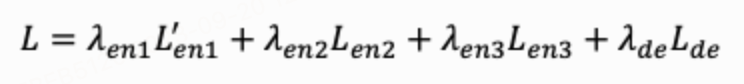
λ*其中为平衡各项损失权重的超参数。
三、数字水印的工程化应用
在工程化应用中,我们不光要关注数字水印算法本身的鲁棒性和不可见性,还需要考虑大规模应用的效率问题。
1. 块编码
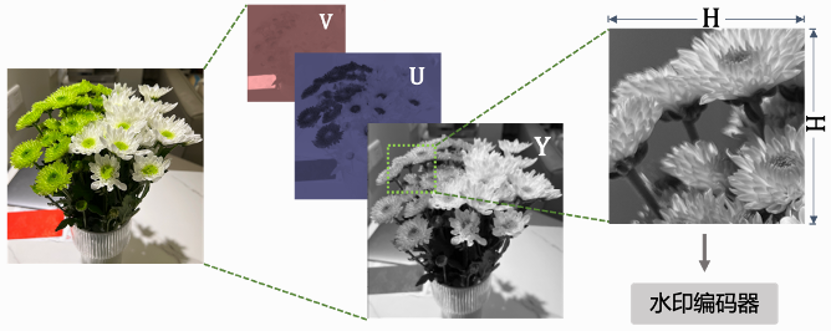
B站的视频数量巨大,为了保证视频发布的时效性,效率压力主要集中在水印编码阶段。为了提高数字水印的编码效率,水印信息采取分块嵌入的方式,这种方式的优势在于可以自行安排水印的嵌入量,相较于整图嵌入的方式更加灵活,且能保证整图画质与原始图像画质几乎没有区别,并且大大降低水印编码的计算量。例如一张4K分辨率的图像,如果进行全图水印编码,使用当前的水印编码模型,单帧编码计算量达到4TFLOPS,显存占用达到14G,硬件消耗巨大,主流显卡耗时400毫秒,编码效率太低,对于高分辨率视频的水印编码来说,工程应用难度很大。如果进行512×512大小的分块水印编码,单个图像块的计算量为0.13TFlops,显存占用为2.7G,主流显卡耗时仅为12毫秒。实际应用中,可以根据当前的硬件环境与效率要求确定水印编码的图像块数,图像块的大小也可以根据原始图像的分辨率动态调整,例如2k和4k分辨率原图可采用512×512分辨率的图像块进行水印编码,1080p和720p分辨率原图可采用256×256分辨率的图像块进行水印编码。为了进一步降低水印编码的计算量,我们只对图像的Y通道进行水印编码。Y通道表示图像的明亮度,UV通道表示图像的色度,对Y通道进行编码只会微弱的改变图像的灰阶值,在明亮度上会有肉眼不可见的扰动,且图像的色度几乎没有变化,可以极大保障图像的质量。
2. 锚点标定
由于视频在被攻击的过程中可能被缩放或剪裁,带有水印信息的图像块相较于原图的位置会发生变化。由于无法确定被侵权后的图像(视频)的水印信息的嵌入位置,所以无法进行有效的水印解码操作。因而在水印解码操作前确定含有水印信息的图像块的位置变得尤为重要。为了确定水印信息的嵌入位置,我们设计了一套锚点标定算法,具体的算法流程是在U通道嵌入若干锚点用来标记Y通道的含水印图块的位置。如果锚点出现在相邻图像块的共有边上,则很难区分该锚点属于哪个图块,所以我们将锚点设置在图像块内部。选择U通道来嵌入锚点的原因是,相较于亮度(Y)与红色分量(V),人眼对蓝色分量(U)的微小变化不敏感,并且锚点是离散且稀疏的,对画质影响很小。
单个锚点的数值通过如下公式计算:
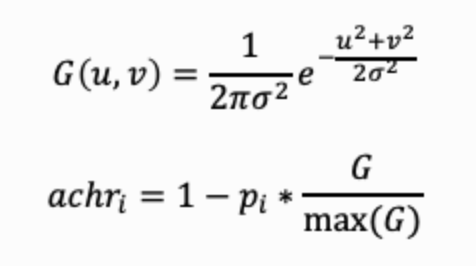
G表示一个二维高斯核,高斯核的形态通过σ来控制,(u,v)为以二维矩形方阵中心为原点的像素坐标。 archi 表示一组锚点中的第i个锚点,pi 控制锚点的数值分布,取值为0到1开区间,max(G)表示G中的最大值。锚点的位置即为该锚点最小值所在的图像像素坐标。
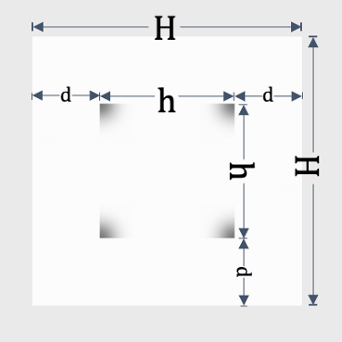
为了进一步区分锚点的类别,可以只保留上述锚点的某个扇区,如图7所示,左上锚点保留右下扇区,右上锚点保留左下扇区,左下锚点保留右上扇区,右下锚点保留左上扇区,未保留的扇区用数值1补全。H为带水印图块边长,h为图块内高斯锚点横向和纵向距离。图8展示了一种一组锚点的取值情况,在实际应用中,数值可以做进一步调整。

U通道的锚点嵌入只需将U通道与锚点图逐像素相乘,如图9。


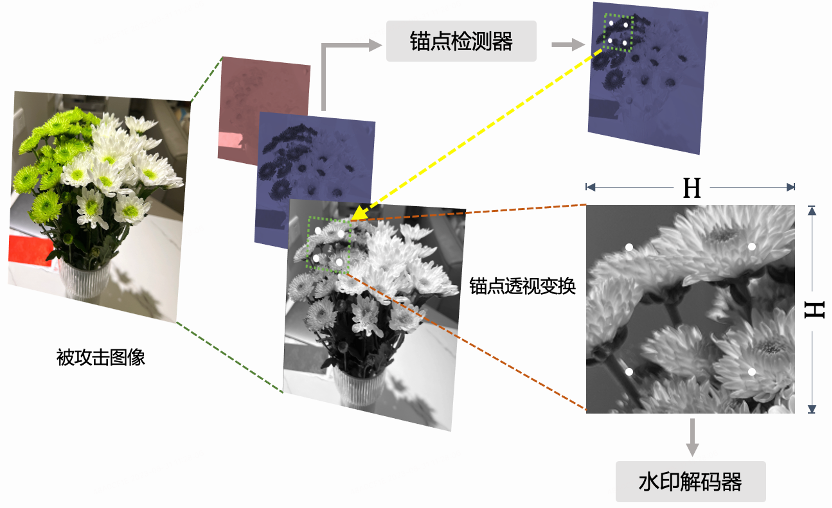
确定了锚点标记方式后,我们训练了一套锚点检测网络,该网络参考人脸关键点检测算法,可将每个图像块的四个锚点检测出来。对于水印解码网络的输入图像来说,输入图像的尺寸是固定的,四个锚点在输入图像上的位置也是确定不变的,所以根据从被攻击图像上检测出的四个锚点的位置和最终送进水印解码网络的图像上的四个锚点的位置,可以确定一个透视变换矩阵,进而可将图像对齐至被攻击前图块的位置后送入水印解码网络,大大提高水印解码的准确率。如图11所示,被攻击图像先分解为带水印的Y通道图、带锚点的U通道图和V通道图,将U通道图输入锚点检测器,得到一组或几组锚点,通过锚点得到水印图块的位置,根据目标锚点位置对水印图块进行透视变换得到目标位置的Y图块,再送入水印解码器得到水印信息。
3. 冗余校验策略
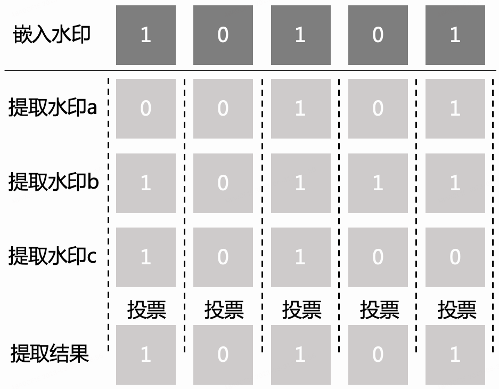
由于图像采取块编码的形式,一张图中可以嵌入多个带水印图块,且视频包含多帧加水印图,可以解码出多个水印信息,对这些水印信息的每个比特位进行投票,提高解码出来的水印的准确率。具体地,对于任意的水印位置k,首先将所有水印的第k位取平均,再使用阈值0.5进行二值化,便可以得到第k位的水印结果。如图12中的简化示例,水印被重复嵌入三次,对应的提取结果设为a、b和c,并假设三者都存在一些错误。将三者的对应位置进行投票从而得到最终的提取结果,此时错误比特被纠正了。
除了上述投票机制,还可以采用更高效的纠错码算法提高水印信息本身的容错能力。例如使用(7, 4)线性分组码(Linear Block Code, LBC)[2]对水印信息进行纠错编码,解码后的信息每7位码字出现1位错误的情况下,是可以正确纠错的。
四、效果演示
我们以两次CRF=32的H.264压缩模拟实际的视频盗用链路,使用字符串【bilibili@copyright】作为原始的水印信息,测试对1080p视频的水印算法的效果。对输入字符串进行ascii转码得到144比特信息,在信息尾部添加112比特随机数用来模拟嵌入视频的其他信息,最终输入的水印信息扩充至256比特。本算法中,每1比特水印信息需要16×16的图像块承载,256比特信息reshape成16×16后可嵌入256×256图像块,那么1080p的图像最多可以嵌入28个图像块的信息。

图13为视频中截取出的一帧图像,原图与加水印图像相比,几乎看不出区别,水印编码算法实现了不可见性的目的。再对加水印视频进行两次视频压缩转码攻击,使用水印解码器从中提取信息,只有当提取出信息包含“bilibili@copyright”时才被视为正确。通过实验测算,当解码出的字符串全部正确的情况下,水印的检出率(recall)为83%,即100帧被攻击的加水印的图像中可以检出83帧水印信息,并且对于未加水印图像完全不会提取出预设的水印信息,即水印的准确率(precision)为100%。
为了进一步验证数字水印算法的实际应用效果,我们在B站和抖音平台上传了带有水印信息的1080p视频,经过平台转码后,从B站下载1080p和720p的视频,从抖音下载1080p的视频,然后进行数字水印解码,成功解码出原始的水印信息。
五、总结
目前学术界对于数字水印的研究没有考虑多次转码造成的画质损失和编解码的效率问题,没有办法直接应用在工程实践中。对于视频画质的判断也只限于PSNR等硬性指标,对于画质的主观变化没有过多评判标准。同时受限于水印编解码算法的鲁棒性,可嵌入的水印信息量也十分有限。工程应用中需要解决的问题非常多,且非常复杂。我们设计的这套数字水印解决方案可以兼顾画质、鲁棒性的同时,保证大规模上量的效率。但随着工程化的进度不断加深,后续还会遇到其他问题,例如权衡信息嵌入量和码率提升的问题、处理更复杂的降质问题等等,以及水印在视频中的嵌入策略和解码策略都需要进一步优化。
参考文献:
[1] Zhang R, Isola P, Efros A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 586-595.
[2] https://en.wikipedia.org/wiki/Block_code
作者:
徐顺鑫:哔哩哔哩高级算法工程师
吕柯兴:哔哩哔哩资深算法工程师
成超:哔哩哔哩资深开发工程师
原文:https://mp.weixin.qq.com/s/hao7p80tYgMi3U71ZoqGmg
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
