
本文提出了MVDream,能够根据给定的文本提示生成几何上一致的多视图图像。通过利用在大规模网络数据集上预训练的图像扩散模型以及从3D资源渲染的多视图数据集,得到的多视图扩散模型既能够实现2D扩散的通用性,又能够实现3D数据的一致性。因此,这样的模型可以应用为3D生成的多视图先验,通过分数蒸馏抽样(Score Distillation Sampling),它极大地提高了现有的2D提升方法的稳定性,解决了3D一致性问题。最后,我们展示了多视图扩散模型也可以在少量样本的情况下进行微调,用于个性化的3D生成,并且经过学习后仍能保持一致性。
作者:Yichun Shi 等
论文题目:MVDream: Multi-view Diffusion for 3D Generation
论文链接:https://arxiv.org/abs/2308.16512
内容整理:王怡闻
引言
最近的一些工作表明,预训练的2D生成模型可以应用于3D生成。如Dreamfusion和Magic3D,它们利用2D扩散模型作为优化3D重构方法(如NeRF)的监督,通过得分蒸馏采样(SDS)进行优化。然而,由于这些模型仅具有2D知识,它们只能提供单视图的监督,生成的图像容易受到多视图一致性问题的困扰,其结果通常包含严重的瑕疵。
在将2D模型迁移至3D的过程中中,由于在得分蒸馏期间缺乏全面的多视图知识或3D感知,会出现如下问题:
- 多面向的问题:角色或动物的关键部分可能会在某些视角下被隐藏或自遮挡。然而,人类可以从多个角度评估这些物体,但2D扩散模型无法做到这一点,因此会产生冗余和不一致的内容。
- 内容在不同视图之间漂移:生成的内容在不同视图之间会发生变化。

这些问题的根本原因在于2D扩散模型缺乏对多视图知识或3D感知的理解,因此在多视图场景下,它们往往难以产生一致的结果。
为了解决这些问题,本文提出了MVDream。我们保留了2D图像扩散的架构设计,但在多图像生成方面稍作修改。这使我们能够利用预训练的2D扩散模型进行迁移学习。为了确保我们模型的多视图一致性,我们从真实的3D数据集中渲染出一组多视图图像。通过在多视图图像和真实图像上联合训练模型,我们发现得到的模型既能够实现良好的一致性,又具有通用性。我们进一步将这些模型应用于通过多视图得分蒸馏进行的3D生成。结果表明,我们模型的多视图监督比单视图2D扩散模型更加稳定。我们仍然可以生成未见过的3D内容,就像2D扩散模型一样。受到DreamBooth和DreamBooth3D的启发,我们还利用我们的多视图扩散模型从一组提供的图像中吸收身份信息,并在少量样本的微调后表现出稳健的多视图一致性。当纳入3D生成流程时,我们的模型,即MVDream,成功生成了没有多面向问题的3D Nerf模型,并在多个评价指标上具有优越性。
方法
为什么使用扩散模型?
为了解决2D扩散模型在3D生成中存在多视图一致性问题的问题,一个典型的解决方案是提高其对视角的感知能力。例如将视角描述添加到文本中作为条件。然而,即使是一个完美的相机条件模型也不足以解决问题,不同视图中的内容仍然可能不匹配。
我们的灵感来自于视频扩散模型。由于人类没有真正的3D传感器,感知3D对象的典型方式是围绕它旋转,并从所有可能的角度观察它。这样的评估过程类似于渲染和观看一个环视视频。视频生成领域的研究工作展示了将图像扩散模型调整为生成一致内容的可能性。然而,将这种视频模型迁移到我们的多视图生成问题并不容易,因为几何一致性比时间一致性更加难以控制。我们的初步实验表明,当视角差距较大时,视频扩散模型生成的视频之间的帧之间仍然可能发生内容漂移。此外,视频扩散模型通常是在动态场景中训练的,当作为静态场景的先验时,存在domain shift的问题。
基于这些观察,我们发现直接为3D生成任务训练多视图扩散模型非常重要,这样我们可以利用3D渲染的数据集来生成静态场景,并获得精确的相机参数。
从文本到多视图的扩散模型

多视图一致的图像生成
类似于视频扩散模型,我们希望调整注意力层以建模跨视图依赖性,同时保持其余网络作为一个2D模型,仅在单个图像内操作。然而,我们发现简单的时间注意力机制无法学习多视图一致性,即使我们在3D渲染的数据集上对模型进行微调,内容漂移仍然会发生。相反,我们选择使用3D注意力。具体来说,我们可以通过在自注意力层中连接不同的视图来将原始的2D自注意力层转换为3D。通过这种方式,模型在不进行微调的情况下会生成相似的图像。在多视图数据集上训练后,即使视角差距很大,也能够生成相当一致的图像。
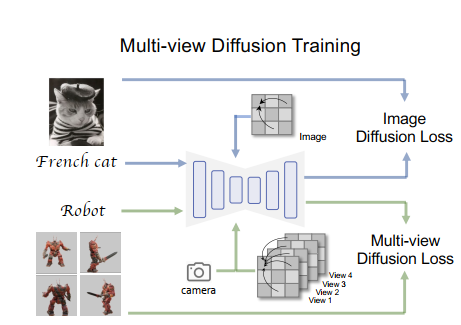
相机参数的嵌入
最初,我们尝试使用与视频扩散模型相同的相对位置编码,然而,结果表明,这种相对位置编码对于我们的任务来说过于模糊,模型经常生成重复的视图。另一方面,简单地嵌入外部相机矩阵(使用一个2层MLP)会产生更精确的结果,其中每个视图可以与其他视图区分开来。
还有一个问题是在哪里注入这些相机嵌入。我们确定了两种方法:(1)将每个视图的相机嵌入添加到其时间嵌入中作为残差,和(2)将相机嵌入附加到文本嵌入进行交叉注意力。我们的实验显示,这两种方法都有效,但第一种选择更加有效,因为相机嵌入与文本描述的关联性较小。
数据与训练
尽管可以获得真实的3D渲染数据,但如何利用这些数据仍然对多视角扩散模型的通用性和质量至关重要。关键因素总结如下:
- 视点选择。
- 生成图像的视图数量。
- 生成图像的分辨率。
- 与原始文本到图像数据集的联合训练。
具体来说,我们发现使用完全随机的视点进行渲染会导致训练困难度过大,模型几乎无法生成良好的结果。因此,对于每个对象,我们选择仅使用均匀分布在相同仰角的不同视点,该仰角在0度到30度之间随机选择。至于视图数量,我们发现视图数量越多,收敛难度也会增加,因此我们选择在当前模型中仅使用4个视图,将图像大小缩小为256×256,这对于多视角一致性非常有帮助。
从文本到3D生成
我们有了一个能够从文本描述生成一致的多视角图像的扩散模型,我们按照如下两种方法利用它进行3D生成:
- 使用多视角生成的图像作为输入,通过少样本3D重建方法生成3D内容。
- 使用多视角扩散模型作为3D优化的先验,通过得分蒸馏采样(SDS)进行3D生成。
尽管前一种解决方案更为直接,但3D重建方法通常需要许多输入角度才能获得令人满意的结果。它们对输入图像之间的一致性有更高的要求。虽然我们的扩散模型的多视角图像看起来一致,但它们的几何兼容性不能保证。
因此,在这项工作中,我们主要关注后一种选择,我们通过将常用的稳定扩散模型替换为我们的多视角扩散模型来修改现有的SDS流程。首先,我们更改了相机采样策略,以便每次在相同的仰角上均匀分布F个视角。其次,我们将绝对相机外参矩阵作为输入提供给我们的扩散模型。与Dreamfusion中使用带有方向注释的提示不同,我们只使用原始文本提示来提取文本嵌入。
多视角3D生成迁移至Dreambooth
我们将上述得到的模型扩展为用于3D DreamBooth应用的DreamBooth模型。感谢多视角扩散模型的通用性,具体来说,我们考虑两种类型的损失,即图像微调损失和参数保持损失:

实验
前四个示例中,上排和下排分别是训练和生成的图像。下面四个示例是使用未见过的提示生成的图像。

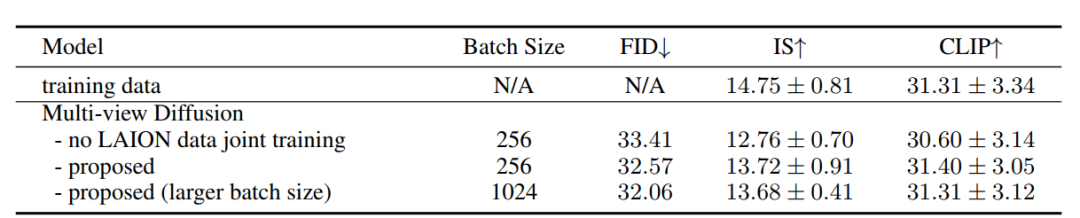
定量比较的实验结果:
总结
在本论文中,我们提出了第一个能够从任何给定的文本生成对象/场景的多视角扩散模型。通过在3D渲染的数据集和大规模文本到图像数据集的混合上对预训练的文本到图像扩散模型进行微调,我们的模型能够在保持基础模型的通用性的同时实现多视角一致的生成。通过全面的设计探索,我们发现使用带有相机矩阵嵌入的3D自注意力足以从训练数据中学习多视角一致性。我们展示了多视角扩散模型可以作为良好的3D先验,并可以通过SDS应用于3D生成,相对于当前开源的2D升维方法,可以获得更好的稳定性和质量。最后,多视角扩散模型还可以在少样本设置下进行训练,用于个性化的3D生成(多视角DreamBooth)。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
