
本文提出了一种名为 OTAvatar 的方法,用于构建具有可控性、泛化性和高效性的人脸化身。OTAvatar 使用一种泛化可控的三平面渲染方案,从单个参考肖像构建个性化化身。它首先将肖像图像反演为运动无关的身份编码,然后利用身份编码和运动编码生成三平面体,最后使用体渲染技术生成任意视角下的图像。实验表明,在训练集以外的主体上,该方法在跨身份重演方面表现出了良好的性能,并具有更好的 3D 一致性。
来源:CVPR 2023
论文题目:OTAvatar: One-shot Talking Face Avatar with Controllable Tri-plane Rendering Interactions
论文链接:https://arxiv.org/abs/2303.14662v1
论文作者:Zhiyuan Ma 等人
内容整理: 林宗灏
引言
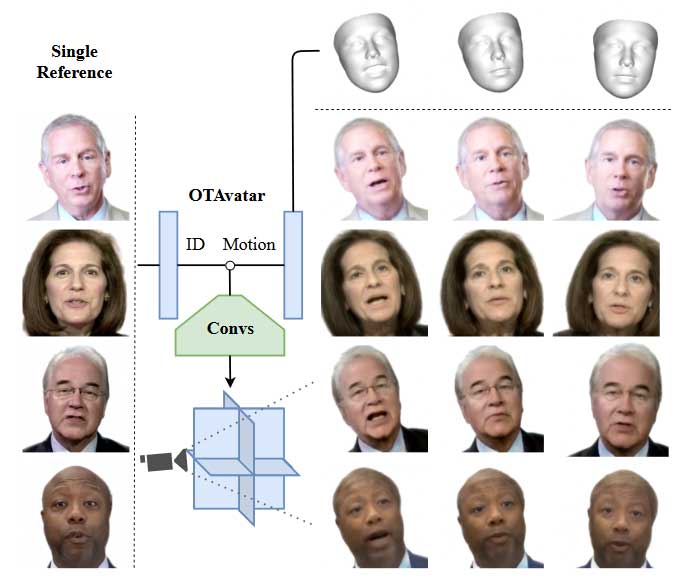
可控性、泛化性和高效性是构建以神经隐式场为表示的人脸化身的主要目标。然而,现有的方法无法同时满足这三个要求。它们或专注于静态肖像,表示能力局限于特定主体;或面临巨大的计算成本,限制了其灵活性。在本文中,我们提出了单样本说话脸化身(OTAvatar),通过泛化可控的三平面渲染方案来构建人脸化身,如此即可从单张参考肖像构建个性化化身。具体而言,OTAvatar 首先将一张肖像图像反演为一个运动无关的身份编码。然后,身份编码和运动编码被用于对高效 CNN 进行调制,生成编码主体在预期运动下的三平面体。最后,采用体渲染技术生成任意视角下的图像。本方案的核心是一种新颖的反演解耦策略,通过基于优化的反演将隐编码中的身份和运动解耦。得益于高效的三平面表示法,我们在 A100 上以 35 FPS 的速度实现了可控的泛化人脸化身渲染。本文的主要贡献总结如下:
- 我们首次尝试通过改良预训练的 3D 生成模型进行运动控制,从而实现单样本 3D 人脸重建和运动控制的渲染。
- 我们提出在反演优化的过程中,采用反演解耦策略,在优化前提示隐编码的运动分量,从而将与运动相关和运动无关的隐编码解耦。
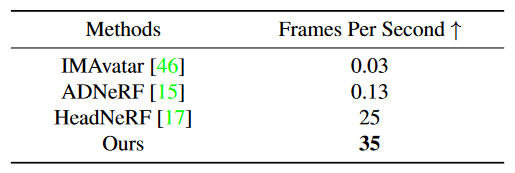
- 我们的方法能以 35 FPS 的速度逼真地渲染任何具有所需表情和姿态的身份。实验表明,我们的方法在 2D 和 3D 数据集上的自然运动和 3D 一致性均取得了有前途的效果。
方法
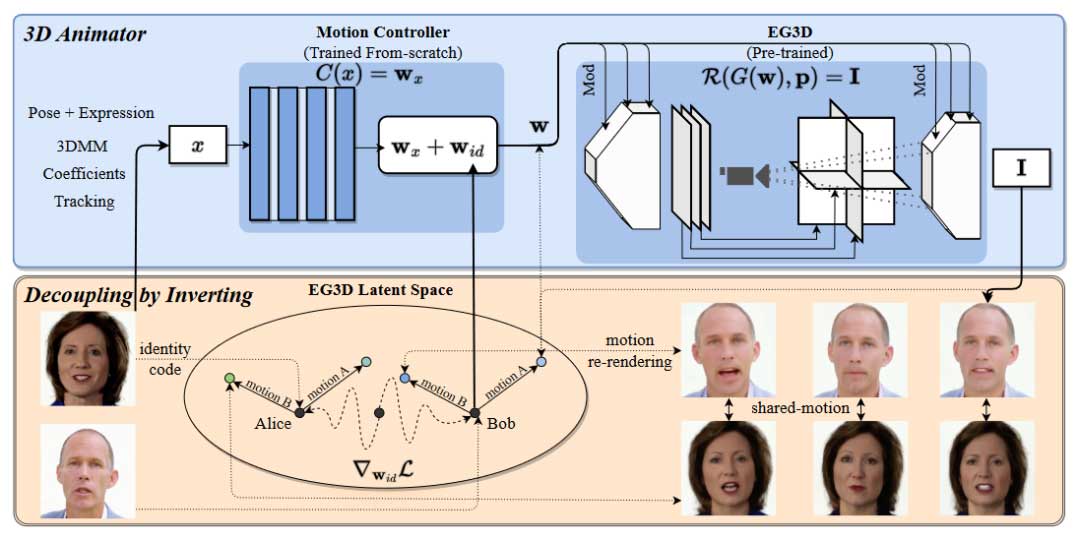
3D 动画器网络结构
三平面体表示

动画器结构
我们使用两阶段策略来实现单样本化身重建:1)建立 3D 人脸生成器;2)使生成器可控。我们的 3D 人脸生成器基于预训练的 EG3D 网络,该网络采用三平面表示方法以实现高效的 3D 面部生成:

控制器结构
我们串联 3DMM 姿态和表情系数来表示运动 x。实践中,我们使用特定半径内的相邻的姿态和表情系数来表示当前帧的运动信号。首先通过 3 个 1D 卷积层在时间维度上对系数加权求和以去除噪声,然后采用 5 层 MLP 将加权求和转换为运动特征,最后构建一个具有可学习正交基的码表,将运动特征投影至最终的运动编码 wx。上述操作总结如下:

控制器训练
给定一对源帧 Is和驱动帧 Id,以及它们的运动信号 xs,xd 和相机视角 p8,pd,我们进行双目标优化:

单样本化身构建
在推理阶段,给定单张肖像图像 Ir、3DMM 系数 xr 和相机视角 pr 作为化身构建的参考,我们对参考肖像的身份编码 wr 估计如下:
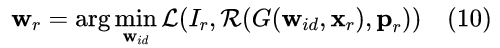
然后,我们可以基于来自任意主体的驱动运动 xd 和相机视角 pd 来对身份进行动画:
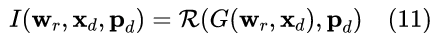
损失项
首先,我们使用预训练的 VGG-19 网络来计算多尺度激活图距离:

然后,我们利用眼睛和嘴部区域的 L1 距离来监督表情细节:
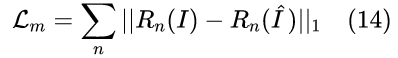
其中, Rn表示眼睛或嘴部区域。最后,使用 ID 损失来维持身份一致性:

实验
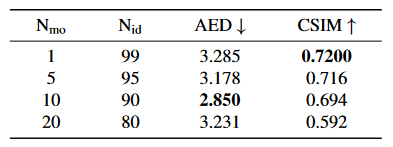
我们在照片级说话脸视频的动画化上评估 OTAvatar 并与支持身份泛化的 SOTA 动画方法进行了比较。在 HDTF 数据集上,我们通过迁移一个主体的运动来驱动另一个主体,即跨身份重演来检验身份-运动的解耦度。所采用的运动提取自具有较大运动变化的视频以评估极端条件下的结果。在 Multiface 数据集上,我们评估了不同视角下动画的一致性,即多视角重演。该数据集中的所有数据均未用于训练我们的方法和基线。对于每个语料,我们选择第一帧正机位图像作为参考,并由网络对后续帧在正视角和其他视角下进行动画处理。
定量结果

定性结果


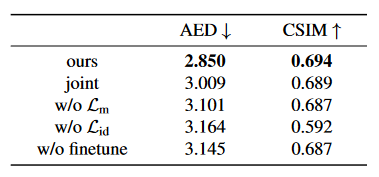
消融实验

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
