
直播是一个庞大而复杂的业务形态,一个优秀的直播系统涉及众多团队的共同协作,有非常完整的直播链路。那么,直播链路中都有哪些角色?这些角色要解决的是哪些问题?要优化某个环节时需要哪些角色的配合?这些角色优化链路的手段有哪些?……想要厘清这些问题,对直播全链路接触比较少的同学无疑要花费大量的时间才能完成。本文将从直播拉流切入,力求帮助有兴趣的同学简单明了而全面地理解整个直播链路。
为什么直播拉流是“最后一公里”
从整个直播链路来看,直播拉流作为直播内容触达观众的最后一个环节,从客观现实上来说,就是直播链路的“最后一公里”。直播拉流作为整个直播链路的“最后一公里”,链路上任何一个前置环节出现问题,都会在拉流过程中体现出来。通过分析、理解拉流过程中产生的各类问题,会是理解直播链路最有效的方式之一。作为直播内容消费的关键环节,如何优化这“最后一公里”上的各类体验,是每个直播从业人员不断探索的问题,从直播拉流理解怎么做好直播无疑是一个好的选择。
从直播业务理解直播链路
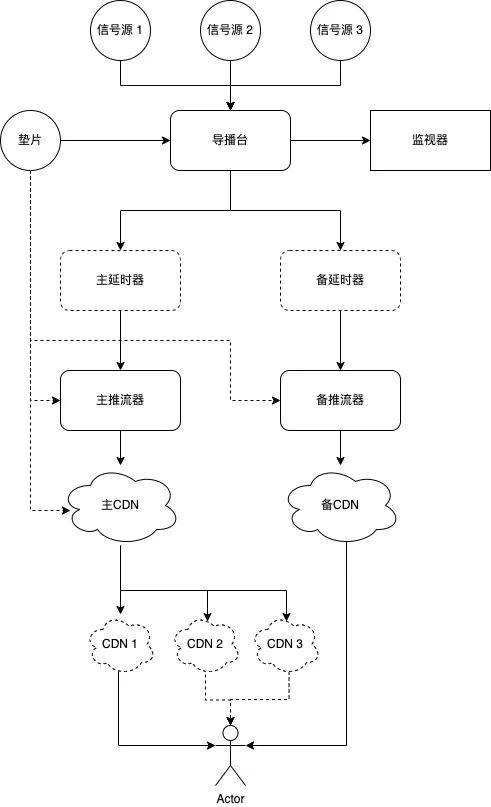
 上图所示是从业务层面看到的一次直播观播过程,也是对直播拉流的一个高度简化。麻雀虽小,但五脏俱全,图中显式或隐式地涵盖了整个直播链路几乎所有关键角色和流程。
上图所示是从业务层面看到的一次直播观播过程,也是对直播拉流的一个高度简化。麻雀虽小,但五脏俱全,图中显式或隐式地涵盖了整个直播链路几乎所有关键角色和流程。
直播链路上的关键角色
客户端
客户端中囊括了直播链路中多个 SDK,包括直播中台 SDK、直播推流 SDK,以及直播拉流 SDK。
- 直播中台 SDK
- 直播推流 SDK
- 直播拉流 SDK
CDN
CDN 全称是 Content Delivery Network,即内容分发网络。CDN 的核心任务是使内容传输的更快、更稳定。整个直播系统中,源站提供了鉴权、转码、回调、禁播等能力。CDN 通过边缘节点,在客户端和源站之间增加一层缓存,请求过的数据会在边缘节点缓存一段时间。动态请求内容会直接回源拉取,CDN 优化整个传输链路,解决跨网访问、传输拥塞等问题。
流调度
流调度主要处理与直播流管理相关的任务,内部封装了多家 CDN 供应商,屏蔽了不同 CDN 的细节区别。满足大规模的直播内容分发需求,同时保证了服务的高可用性。提供完整的解决方案,方便业务方快速接入直播业务。
关键流程
直播数据流
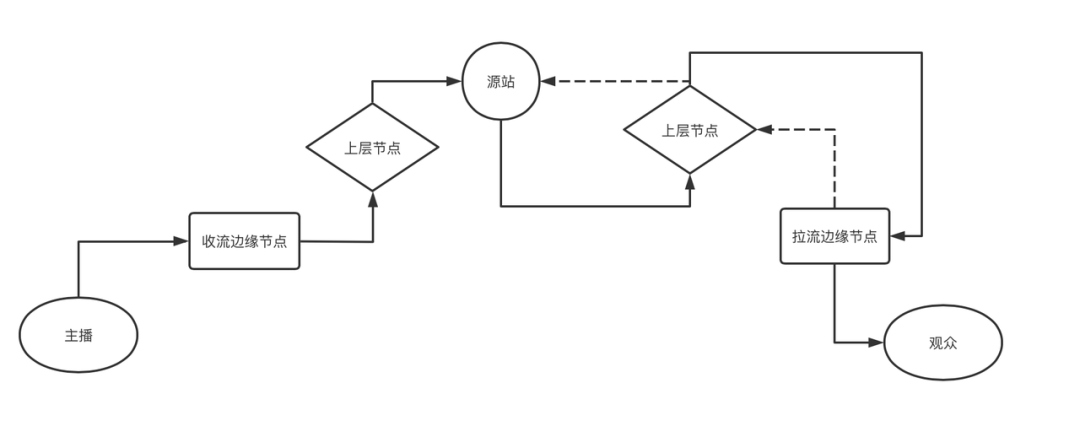 直播内容从生产到消费主要涉及到推流端、CDN(源站、边缘节点)以及拉流端,如图中实箭头所示即为直播数据流方向,其中:
直播内容从生产到消费主要涉及到推流端、CDN(源站、边缘节点)以及拉流端,如图中实箭头所示即为直播数据流方向,其中:
- 在推流端,推流 SDK 完成了主播的音视频采集,添加美颜、滤镜后,需要经过编码、封装,最终按照指定地址,向 CDN 边缘节点推流;
- 收流边缘节点在被动收到用户的推流请求后,这个节点会主动地将这个流转推(中继)到上层节点,上层节点经过同样的过程,最终将源流转推到源站;
- 源站内部会进一步地将源流转推至其他集群完成转码、录制等任务;
- 在拉流端,拉流 SDK 会根据流地址向 CDN 边缘节点拉流,此时根据这路流在该节点上的缓存命中情况,出现两种结果:
- 如果命中缓存,则边缘节点将直接返回缓存数据;
- 如果未命中缓存,边缘节点将逐级进行回源,最终将流数据返回边缘节点,最终返回播放器。
词语释义:
- 源流:推流端推出的那路流。
- 转码:当需要对源流的分辨率、码率、编码等参数进行修改时,就需要进行转码,例如媒体直播往往由专业设备或者三方推流器推出,码率会非常高,直接拉源流会造成带宽压力过大,这时就需要转码。但转码任务本身也需要消耗资源,因此衍生出推流转码、拉流转码等不同转码策略。
- 回源:往往发生在拉流侧,边缘节点上未命中缓存时,就需要到源站找到所需要的流,该过程即为回源。在上图中表示为虚箭头。完成回源后,边缘节点上会留下这路流的缓存。
流调度
在开播侧,参与到整个流程的角色包括 App、直播 SDK、开播服务、房间服务以及流调度。各角色在开播中的工作如下:
- 主播在 App 发起开播请求;
- 开播服务收到开播请求后根据不同的场景,使用不同的发布点 ID 向流调度发起请求创建直播流;
- 流调度根据具体要使用的发布点生成对应的推流地址,在这个过程中完成调度,决定使用哪家 CDN 以及使用何种协议等;
- 开播服务将推流地址返回至 App 后,App 开始推流、房间服务在推流成功后更新流状态;
在看播侧,参与到整个流程的角色包 App、直播 SDK、房间服务以及流调度,其中
- 观众在 App 发起进房请求;
- 房间服务收到进房请求后,透传请求中携带的用户信息、向流调度请求拉流地址;
- 流调度收到请求后,根据用户信息进行调度,决定下发的档位信息、功能信息等,并返回至房间服务;
- 房间服务获取到流信息后,完成档位映射等逻辑,最终返回 App;
- App 获得流信息后透传至直播 SDK,并触发播放。
流调度负责了与流管理相关的所有工作,包括流创建、流参数下发、流状态管理、生成推拉流地址等,同时流调度在重保活动中也起着举足轻重的作用。了解流调度是如何进行调度的,最好的方式是从流调度返回的数据来理解。例如在拉流端,所有调度信息是封装在 stream_data 中,随房间服务接口返回,由中台客户端透传给拉流 SDK,主要包含了以下重要信息:
- 分辨率,除源流外,目前支持的档位有UHD、HD、SD、LD、MD、AO、AUTO,其中
- AO、MD 仅在特殊情况下使用,例如后台播放等不需要高码率的情况
- 并以不同的标识符分别代表该档位为 H.265 或 H.264 转码
- 主备,为满足大型活动中的灾备需求,下发流数据中会包含两条线路–即主(Main)备(Backup)双线,实际上进行了 CDN 调度
- 格式,在每个档位的每条线路下,一般存在多种格式(format)供拉流使用,例如常规 FLV、用于超低时延的 RTM、以及时移直播 TSL 等
- 流调度参数,为直播拉流提供所需的各类参数,例如控制实际使用协议、格式等,在实现调度的同时,避免上层业务感知不必要的细节;此外可以根据具体的场景控制参数的生效范围,实现从 CDN 维度到单路流维度的精准控制
流调度在直播日常业务中,除了要对线上的默认分辨率、码率等进行控制之外,在重保活动中也起着举足轻重的作用。
- 当预估带宽很大时,往往需要多家 CDN 来共同分担压力,同时需要根据各家质量来调节占比;
- 为避免推流端故障往往需要一主一备两路流的热备方案(甚至还需要冷备),拉流端需要在其中一路发生故障时自行切换到另一路;
- 在带宽压力过大时,需要及时降低下发的默认清晰度以缓解带宽压力,同时在带宽充足时提高默认清晰度以优化体验。
词语释义
- ABR:即自适应码率,在直播间中作为 AUTO 分辨率档位,但是 stream_data 中实际不会包含这样一个档位,原因在于 ABR 实际是将要使用的若干档位拼装成了一个 MPD(Media Presentation Description)传递给播放器,播放器内部切档时实际使用的是对应档位的流地址。
日志与监控
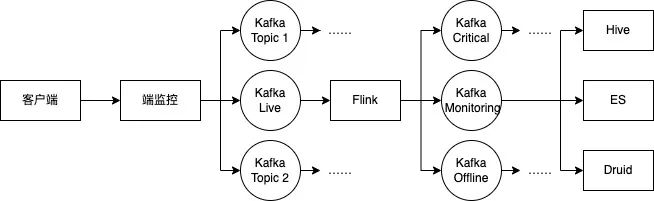
端监控作为日志上报的起点,将客户端产生的各类日志按照一定的规则(例如采样率等),进行上报;根据不同的 log_type,上报的日志会被分流并写入到 Kafka 的不同 topic 中;根据数据不同的消费场景及用途,日志会经历一系列处理(例如在 Flink 任务中进行清洗等),并最终呈现到各类数据工具当中。了解日志数据流对于定位日志相关的各类问题是非常有帮助的。例如在 Kibana 中找不到日志时,可以从日志是否上报(通过 Charles 抓取端监控 monitor 接口上报数据确认)、分流是否正确(通过检查 log_type 确认,一般不会在该环节出现问题)、是否由于日志中存在非法字段而被清洗(通过检查端监控中的原始日志确认)等。
从直播链路理解优化与问题
为什么拉不到流?
直播是一条完整的链路,链路上任何一个环节中断都会导致拉流端出现拉流失败的情况:
- 推流端-收流节点中断:单路流所有档位、所有观众将出现进房时拉不到流或直播间内卡顿;
- 收流节点-源站中断:一般不会出现,故障源站上的所有流将出现异常;
- 转码异常:某一个或几个转码档位出现异常,源流正常,观看转码档位的观众报障;
- 源站-拉流节点中断:从故障边缘节点上拉流的全部观众将会异常;
- 拉流节点-拉流端中断:单用户拉流出现故障。
前述情况主要描述的链路上某个环节中断导致的拉流失败,有时拉流失败其实是首帧耗时过长造成的,这种情况在拉流成功率指标波动分析时较为常见:首帧耗时增长导致了拉流成功率下降。
为什么首帧慢?
首帧分阶段分析
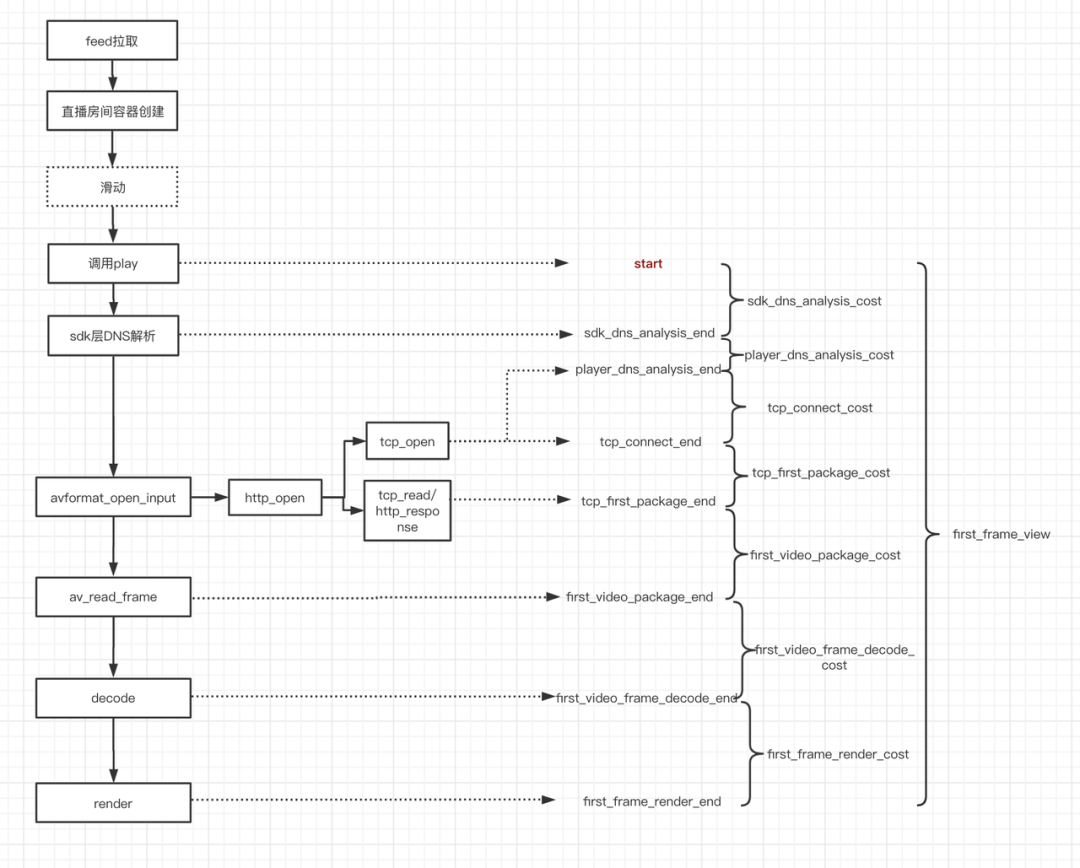 以 HTTP-FLV 为例,从触发播放器的 play 接口到最终完成首帧渲染,需要经历以下这些过程:
以 HTTP-FLV 为例,从触发播放器的 play 接口到最终完成首帧渲染,需要经历以下这些过程:
- DNS 解析:决定了要从 CDN 的哪个边缘节点拉流。这一过程在拉流 SDK 以及播放器内核中都会发生,后者往往是因为 SDK 层没有解析到 IP 地址。DNS 解析耗时通常在 100ms 左右(localDNS,使用 HTTP-DNS 会进一步增加),因此 HTTP 场景下,我们可以采用 IP 直连的方式规避 DNS 耗时。
- 实现 IP 直连需要在拉流前获取到 IP 地址,其关键在于 DNS 缓存(缓存之前的 DNS 解析结果,拉流 SDK 层的 DNS 策略)和 DNS 预解析(在 App 启动之后一段时间,对可能用到的所有域名进行 DNS 解析并缓存结果,节点优选 SDK 的核心逻辑);
- 缓存的 DNS 结果会过期,尤其是 CDN 进行节点覆盖调整时,缓存的 DNS 可能会导致调整不能及时生效,因此需要定期更新 DNS 结果;
- 用户发生跨网时,由于运营商变化,也会导致此前缓存的 DNS 不可用,因此需要在网络状态发生变化时更新 DNS 结果。
- TCP 建联:与边缘节点建立 TCP 连接,这一过程的耗时主要是三次握手,耗时1-RTT。要优化建联耗时,可以通过 TFO(TCP Fast Open,Wiki),或使用 UDP 协议(QUIC、KCP)。
- TCP 首包:HTTP 响应完成,此时开始返回音视频数据。如果此时边缘节点上有这路流的缓存,那么将直接返回缓存数据;如果没有命中缓存,TCP 首包返回之前将发生回源。要优化首包耗时,核心思路在于降低回源率,常见手段有增加边缘节点缓存保持时间,对于大型活动提前进行预热、以保证更多边缘节点上有缓存。
- 视频首包:耗时主要发生在 avformat_find_stream_info 函数调用,播放器在播放前需要探测一定量的流数据,以确定流格式、编码等流信息。由于目前在各个宿主中播放的格式相对固定,因此不需要探测过多的数据即可确定流信息。所以可以通过调节探测的数据量以优化视频首包耗时。通过减小探测数据量,首包耗时下降 300ms 左右。降低流数据探测的数据量也可能会带来不良后果。当探测的数据量过少时,可能会导致读取到的流信息不全,例如只探测到音频数据、没有探测到视频数据(尤其是在音视频数据交织不均匀的情况),最终出现有声无画或声音正常、画面卡住的问题。
默认参数:max_analyze_duration = 5 * AV_TIME_BASE; //5sfps_probe_size = 20; // 20帧视频max_probe_size = 1 << 20; // 1MB优化参数:fps_probe_size = 3; // 3帧视频- 视频首帧解码和视频首帧渲染:分别完成视频首帧解码和视频首帧渲染,优化的主要方向是 decoder 及 render 实例的预初始化等。
快启buffer
为了实现秒开,各家 CDN 都在边缘节点上开启了快启 buffer 策略。快启 buffer 的核心逻辑是基于边缘节点上的缓存(GopCache),调节缓存数据下发的具体数据范围,同时保证视频数据从关键帧开始下发。快启 buffer 也存在不同的策略,例如上限优先或下限优先,后者会要求对接的 CDN 厂商按照下限优先的原则下发缓存数据,比如下限 6s ,会先在缓存数据中定位最新 6s 的数据,然后向 6s 前的旧数据查找第一个关键帧下发(解码器要从关键帧开始解码,因此一定需要从关键帧开始下发)。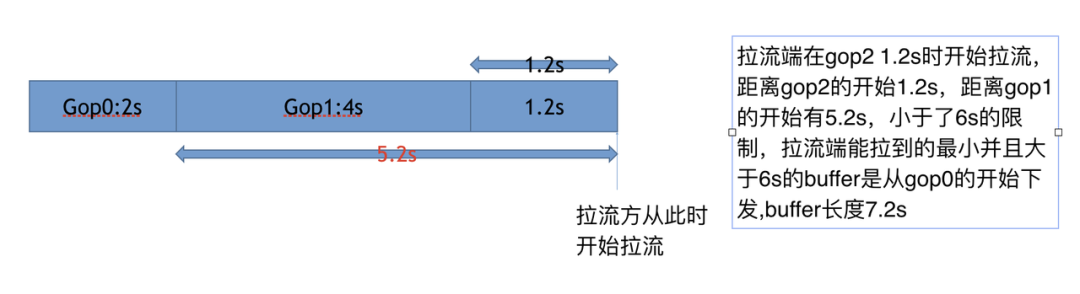 词语释义:
词语释义:
- IP 直连:即将 HTTP 地址中的 host 部分直接替换为对应的IP地址,并在 HTTP 请求的header中添加“Host”行,其值为原始的host,例如
http://x.x.x.x/app/stream.flv "Host:pull-host.comrn"。前述方法最为规范,有的 CDN 也会支持在 host 前直接插入 IP 的方式实现 IP 直连,但该方法并不通用,因此并不建议使用前插 IP 的方法。
为什么会卡顿?
拉流发生卡顿的直接原因是播放器中的缓存耗尽,此时播放器卡住其实是在进行 Rebuffering 。导致 buffer 耗尽的直接原因是播放器中 buffer 消费的速度高于 buffer 接收的速度:最为常见的例子就是当前拉流端的带宽显著低于视频的码率。同时,在带宽充足的情况下,链路上前置环节的中断也有可能导致拉流端卡顿。因此为了对抗卡顿,一个最直接的方法就是在播放器中缓存更多数据,以期在缓存数据耗尽之前渡过网络波动。最直接的做法就是增大播放器的最大缓存,使播放器能够缓存足够多的数据。但直播场景的特殊性在于直播内容是实时产生的,在最大缓存允许的情况下,播放器中的缓存完全取决于当前链路上有多少缓存(还记得 GopCache 吗)。在播放器数据消费速度不变、带宽充足的情况下,播放器在获得了链路上所有的缓存后,buffer长度将不再变化,也就意味着播放器只能依赖这些缓存来对抗卡顿。在能获得的缓存总量有限的情况下,进一步增强现有的缓存对抗卡顿能力的手段就是调整播放器消费数据的速度,例如在首帧之后判断当前水位( buffer 长度)以决定是否起播(对应起播 buffer 策略),或在水位较低时降低播放速度(对应网络自适应策略)。在有限的带宽条件下,如果能够更有效的利用带宽、采用更加高效的传输协议,也可以有效地对抗弱网条件下的卡顿问题。因此 KCP、QUIC、QUICU 等相较于 TCP 更加高效的协议被应用到了音视频传输当中。除此之外,在特定的带宽情况下选择合适的码率,也是降低卡顿的有效手段之一,因此ABR也在直播中得到了应用。实际上“卡顿”在用户反馈中涵盖的情况很多,例如:App 本身的卡顿,或者 CDN 某些操作(数据积压时丢弃视频数据造成的视频卡住、声音正常,或者在数据积压时主动使播放器报错发生重试进而导致播放器出现鬼畜),甚至视频本身帧率较低,都会导致用户出现“卡顿”的感觉。为了更加贴近用户对于卡顿的感受,我们增加了视频渲染卡顿这一指标。
为什么有延迟?
为了对抗卡顿,我们需要在直播链路中增加缓存,但是缓存的引入必然导致延迟的增加。例如在抖音上线低延迟 FLV 之前,端到端延迟在5~8s,而这些延迟的引入主要原因就在于 CDN 边缘节点上的 GopCache –只有缓存到足够的数据才会进行下发,在这个过程中便引入了时延(当然不管是推流端采集、服务端中间链路都会引入延迟,但是相对于缓存引入的延迟影响较小)。在客户端播放速度不变的情况下,延迟会一直保持下去,另外在发生卡顿(且未触发重试)时延迟会不断累积。因此通过调节边缘节点的 GopCache 大小可以直接影响到链路上的端到端延迟。与此同时,Gop 的大小也会影响到不同用户之间的延迟差,在具体场景中就体现为两个观众的延迟存在差异(比如内购会别人看到主持人说了“3、2、1,开抢”,你才看到“3”),两名观众进入直播间的时间差即使很短,但是延迟差可能达到一个 Gop(以下图为例,假设快启 buffer 下限为 1.3s ,用户分别在 1.2s 和 1.4s 进入直播间,延迟分别是多少?)。为了更好地保证观众端的延迟体验,我们在全面梳理了线上的延迟产生原因,实现了低延迟 FLV 方案,使得线上端到端延迟由 7s 左右下降至 3.5s 左右,并在抖音取得了显著的 QoE 正向收益;与此同时,RTM 低延迟拉流方案也在稳步推进中。
如何判断拉流异常问题的发生环节?
问题定位一般流程
如前文所述,直播是一个全链路的业务形态,尤其是拉流端处在整个链路的末端,各个环节的问题都会导致拉流端出现异常。因此如何根据现有信息及工具来定位问题的根源,便是解决问题的关键。定位问题一般要经历以下过程:
- 对于各类问题,首先需要的是明确的case与信息,针对具体case,需要的信息有:
- 拉流端device_id或user_id
- 问题现象描述(至少提供roomID或者流名)
- 问题发生时间
- 最好提供录屏
- 在Trace平台,根据前述信息检索相关日志,可以根据问题现象进一步查找对应的事件(对应event_key字段)
- 拉不到流?找到play_stop事件
- 根据first_frame_blocked字段判断首帧卡在哪个阶段
- 根据code字段判断错误码是什么(错误码是0?还记得拉不到流的部分原因是首帧慢吗?)
- 首帧慢?找到first_frame事件
- 根据前文中分阶段耗时对应的字段,寻找存在显著异常的阶段
- 卡顿?找到stall事件
- 根据流名查询对应时间点推流端的推流情况,是否推流端卡顿
- 根据拉流端在问题时间段前后的日志信息判断是持续性卡顿、短时间波动还是流相关卡顿
- 如果找不到stall事件,只有render_stall,那么可能的原因就是发生了丢帧
- 拉不到流?找到play_stop事件
- 例如花屏、绿屏之类的问题,在日志上一般没有特别明显的错误,此时可以通过查看流回放判断源流是否有异常。如果源流回放没有异常,且用户播放转码流,且流已经结束的情况下,就需要运营同学持续关注相关反馈,尽可能保留现场(因为转码流不会进行录制)。
问题范围与定位方向
除了前述定位问题的一般过程,问题发生的范围也是快速定位问题的有效依据。一般有以下判断方法,根据问题(同一时间段)发生在不同用户或场景判断:
- 所有主播及观众 –> 这种情况非常少见,如果出现,一般意味着出现了整个系统级别的问题
- 单个主播的所有观众 –> 推流端本身或推流端到边缘节点或源站引起,如果到边缘节点日志正常,一般为源站问题
- 同一CDN下的多个主播的所有观众 –> 收流节点问题(收流节点相同)或源站问题(收流节点不同)
- 单个主播的部分观众(仅转码流观众或仅源流观众) –> 源站转码问题(默认分辨率的存在导致判断易受影响,如果只有转码流播放,那么发生问题即使的是源流,最终反馈问题的也只有转码流观众)
- 单个主播的部分观众(某一地区) –> 分发CDN问题,一般是某一节点问题,层级因地区而异
- 单个主播的部分观众(CDN聚集) –> 分发CDN问题,这种情况一般出现在活动,有多家CDN参与分发
- 全量用户(或有版本等特征)某一时间点后 –> 基本是放量引起的
- 某些版本一段时间出现激增并骤降 –> 一般是流相关的问题,在某些版本触发了异常
- ……
问题定位的经验是需要不断积累的,不可能一蹴而就;除经验外,还需要深入理解各个角色在整个链路中的作用,根据问题的表现推测根因,再基于推测进行佐证。
止损手段
推拉流 SDK 对于新功能都会添加各类开关,以保证功能上线后、出现异常时可以及时关闭进行止损。但是对于一些新问题或者一些历史问题,如果没有相应开关进行控制时,对于业务线会造成不同程度的影响。这类问题一般会是流相关的,且在测试阶段隐蔽性高(测试阶段没有办法百分之百覆盖到这些流问题,尤其是新问题)、突发性强(往往随直播开播时发生、关播时结束)。这类问题在初步分析问题、确定问题可以通过调度等手段解决时,可以尝试与转码、流调度配合完成这类问题的及时止损。随后在新版本进行问题修复。
总结
在实际的直播相关业务开发过程中,还有许许多多有趣且值得深入挖掘的内容,这篇文章仅仅是对直播链路做了一个简单的概览,力求帮助没有直播开发相关经验的朋友对直播全链路有一个全局性的理解,相信各位朋友在理解了直播全链路之后,对于直播体验优化或问题排查一定能够更加得心应手。
关于「字节跳动视频云技术团队」
字节跳动视频云技术团队,负责字节跳动旗下抖音、西瓜视频、今日头条等多个业务视频点播、视频直播、Web多媒体等音视频技术方案建设、播放体验优化等工作,为数亿用户提供优质的音视频服务体验。
同时,团队也致力于研究、探索多媒体领域的前沿技术,参与国际、国内多媒体方向的标准化工作,为多媒体内容分析、处理、压缩、传输、创新交互等领域提供软硬件解决方案,众多创新算法已经广泛应用在抖音、西瓜视频等产品的点播、直播、实时通信、图片等多媒体业务,并向火山引擎的企业级客户提供技术服务。
作者:陈昭杰 字节跳动视频云技术团队
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。