
这篇文章主要介绍了一种基于深度学习网络的图像压缩框架,该框架并不把提升人类视觉质量作为最终目标,而是面向进行计算机视觉任务的机器并进行进行端到端的训练,最终得到了优于标准VVC的图像压缩方法。
题目:Boosting neural image compression for machines using latent space masking
来源:arXiv
作者:Fischer K, Brand F, Kaup A.
论文链接:https://arxiv.org/pdf/2112.08168.pdf
内容整理:陈星晗
引言
现今,大部分的图像与视频编码算法都是面向人类视觉,即为了人类更好的观测复原后的图像而设计。然而,现今越来越多的图像被直接传输到机器,用于计算机视觉任务如目标检测、目标分割。这些图像不由人类进行观测,而是通过机器直接识别并得出结论。因此,编码的主要目标不是保持视觉质量,而是在给定的比特率下保持机器的任务准确性。在这样的需求下,需要新的编码方案以更好的满足机器视觉任务的需求。
在本文中,我们的目标是通过使用完全基于神经网络的编解码器,以此提高机器的图像编码性能,并以端到端方式优化了所应用的分析网络在更少的比特率和更好的性能之间的权衡。为了改进应用于 VCM (Video Coding for Machines) 场景的标准神经压缩网络(NCN)架构,我们提出了一种新的附加潜在空间掩蔽网络(LSMnet),它可以屏蔽潜在空间的非显著成分,以显著降低比特率,但仍能保持检测精度。此外,我们提出了一种基于启发的特征失真,允许 NCN 适应 VCM 任务,而不需要注释的训练数据。本文的主要贡献如下:
- 采用了一个带有额外超先验的 NCN,并针对实例分割的 VCM 任务调整了其训练损失,从而得到一个针对 VCM 场景进行端到端优化的 NCN 模型。
- 首次在 VCM 环境中采用了基于特征的失真损失,极大地提升了编码性能。
- 提出了一种新颖的掩蔽网络 LSMnet,它与NCN编码器并行运行,并在潜空间中屏蔽了某些值,减少了传输的比特率。
- 对目标检测和分割任务进行了广泛的研究,证明了基于 NCN 的 VCM 框架和 LSMnet 优于针对人类视觉系统(HVS)优化的标准方法。
基本框架
基本神经压缩网络
对于核心自动编码器,输入图像 x 被输入编码器网络 genc,通过卷积层将图像信息压缩到潜在空间 y,随后呈非线性。随后,y 被量化,得到的 y^以比特流 b1无损传输到接收侧。在那里,解码器网络 gdec从传输的y^ 重构压缩图像x^。
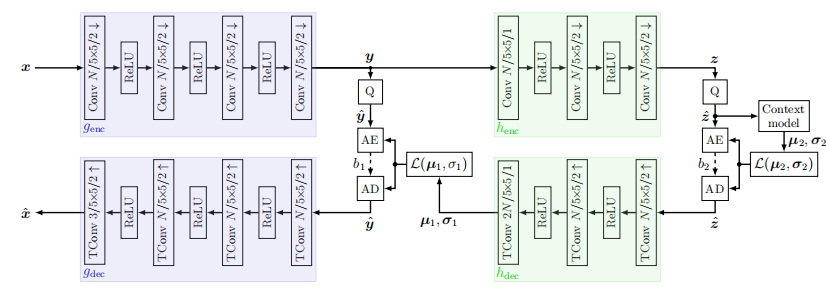
由于图片中的像素存在空间依赖性,即每一个像素与其周围的像素存在一定的联系。根据经验法则,我们认为当前所需传输的值对应的概率越高,传输所需要的位数就越少。为了减少传输所需的比特率,我们利用了图像的空间依赖特性。我们采用了一个额外的超优先网络以估计像素的平均值和方差,将其归一化至一个拉普拉斯分布。所采用的超先验网络也是一个自动编码器。首先,将图像的潜在表示y 输入超编码器 henc,生成潜在空间 z。与核心自动编码器类似,z 被量化为 z^,并通过比特流 b2传输。我们将四个子网络的可学习参数进行联合训练,以得到最优的网络性能。
Mask R-CNN 评估网络
为了将编码框架针对计算机视觉任务进行优化,我们选择了 Mask R-CNN 的实例分割网络作为编码框架的后端网络,将其进行实例分割的损失函数返回原框架进行优化。在 Mask R-CNN 网络中,原始图像首先通过 CNN 结构输入 backbone 以获得高水平的语义特征映射。根据这些特征,Mask R-CNN 的区域建议网络(RPN)估计出感兴趣的区域(RoI)。对应于每一个 RoI 的特征图被裁剪出来并输入到 RoI 池化层中,该池化层为每个 RoI 返回一个固定空间大小的特征图。最终,将 RoI 头应用于特征向量,得到最终的预测结果,其中包括类标签、一个边界框和每个 RoI 的一个二进制掩码。其返回的损失值为:

基于 VCM 优化的特征损失
我们发现在像素空间的经典 MSE 等失真度量上优化的压缩方案,并不一定使得神经网络的性能最佳。同时,上述方法还有一个缺点,它需要经过注释的标签来计算特定任务的损失函数。但在实际应用中,我们常常只有原始的图片数据。因此,我们提出了一种新的损失函数,其中编码器的失真是在特征空间测量的,而不是在像素域中。这允许编码器省略在以后的特征图中不存在的信息,这些信息对后端计算机视觉任务来说不那么重要。

通过 LSMnet 屏蔽潜在空间
在过去的一些论文中,一些编码模型通过减少在非显著区域,即对后续网络性能几乎没有影响的区域的传输开销,以较少传输的总比特数。受这种显著性驱动过程的启发,我们提出了 LSMnet mLSM 网络,其与核心 NCN 编码器 genc并行运行。它可以生成掩蔽特性 α,以便获得潜在表示y 的软掩模元素,这些元素包含的信息对训练后的分析任务可能不重要。因此,这些元素可以以较低的质量传输,因此也可以节约在这些信息上的比特率开销,同时不影响分析网络的检测精度。
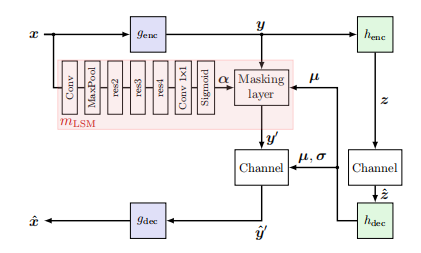
网络训练与结论
我们使用 Python 深度学习库 PyTorch 实现并训练了我们所有的模型,分别使用 Cityscapes 数据集以及 DIV2K 数据集,基于对人类视觉的失真、基于计算机视觉任务的失真和基于特征的失真分别进行了优化。


版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
