
随着深度学习模型变得越来越庞大,开发性能退化最小的轻量级模型至关重要。在本文中,作者提出了一种SHAP-SAE(SHapley Additive exPlanations based Sparse AutoEncoder)算法,该算法可以显式地测量各单元和链路的贡献,并选择性地激活重要的单元和链路,从而实现轻量级稀疏自动编码器。该算法也解释了为什么以及如何构造稀疏自动编码器。作者证明了SHAP-SAE优于包括密集自动编码器在内的其他算法,还证实了SHAP-SAE对自动编码器的苛刻稀疏性是鲁棒的,因为即使在高稀疏性水平下,它也显示出显著有限的性能退化。
题目:Lightweighted Sparse Autoencoder based on Explainable Contribution
作者:Joohong Rheey, Hyunggon Park
来源:ICML 2023
论文地址:https://openreview.net/forum?id=aIwo6eY4hg
内容整理:李江川
引言
随着深度学习方法解决了越来越多的现实世界问题,对提高性能的需求导致了更庞大模型的开发。然而,这些大而密集的网络在推理过程中通常需要大量的浮点运算。因此,在不影响模型质量的情况下,设计能够增强可扩展性和效率的轻量级模型是至关重要的。在深度学习推理必须遵守严格的能量约束的情况下,轻量级模型的重要性变得更加明显。特别是在移动设备和物联网设备等电池供电设备上部署模型时,这一点尤为明显。
与其他深度学习模型类似,自动编码器重点关注于如何有效压缩输入数据,这使得它的结构也变得更庞大。自动编码器通常是一个具有全连接层的密集网络,大多数现有架构都基于这种结构。由于缺乏对轻量级自动编码器的研究,我们专注于通过对隐藏单元施加稀疏性约束来设计轻量级自动编码器。要制作压缩或稀疏的自动编码器,必须识别在经过训练的通常密集的自动编码器中哪些单元和链接是重要的,然后选择性地激活比其他单元更重要的单元。稀疏化通常通过激活函数、采样和不同类型惩罚的组合来执行。虽然这使得自动编码器变得稀疏和高效,但稀疏的自动编码器往往缺乏可解释性。
在本文中,提出了一种新的SHAP-SAE算法,该算法可以使自动编码器稀疏且具有可解释性。与先前的工作不同,本文使用Shapley值(shapely值的概念来源于上世纪合作博弈理论,主要是用来处理合作问题中如何公平的分配奖励的问题。近年来,这个概念被运用到机器学习的可解释性问题上来,主要用于衡量不同输入特征的重要程度)来明确量化自动编码器中单元和链接的重要性。这使模型能够识别具有更高重要性的单元或链接,因此,可以通过仅激活具有更高Shapley值的单元和链接来稀疏地表示自动编码器。值得注意的是,这种方法不仅提供了修剪链接的方式,而且还解释了稀疏自动编码器工作的方式——仅有标记为更高重要性的链接在稀疏自动编码器中被激活。此外,所提出的单元和链路重要性的度量可以允许直接控制自动编码器的稀疏性,因为可以修剪具有低重要性的单元或链路以满足目标稀疏性水平。所提出的SHAP-SAE算法通过对稀疏自动编码器中修剪后的链路分配零权重,可以完全去除重要性较低的链路。该特性允许在推理过程中降低计算复杂性。
基于Shapley值的稀疏自动编码器
自动编码器概述
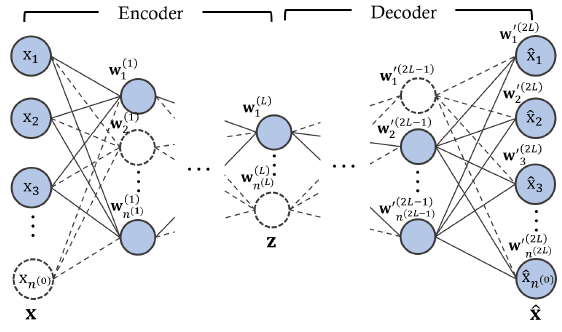
考虑一个由编码器f和解码器g组成的自动编码器,其中编码器和解码器都具有L层,编码器和解码器拥有完全对称的结构。对编码器来讲,第l个隐藏层拥有的单元数量为n(l),且有n(l)<=n(l-1),代表单元数量在逐层递减。因为是全连接网络,每层拥有一个维度为n(l)x1的偏置向量和一个维度为n(l)x(l-1)的权重矩阵。解码器就是编码器的逆结构。训练的目标是获得一个最佳的参数合集,使得重建误差最小。
基于Shapley值的链路重要性
为了估计自动编码器中每个链路的贡献,我们使用Kernel SHAP方法,该方法基于LIME(Local Interpretable Model-agnostic Explanations)和Shapley值来近似SHAP值。为了根据链路对下一层输出的贡献来衡量链路的重要性,基于Shapley值定义了链路重要性(LI)。具体来讲,对于链接第l-1层的第j个单元和第l层的第i个单元的链路,定义其LI为:
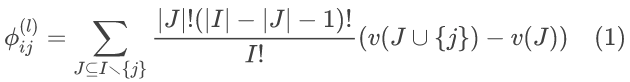
其中I代表了所有从第l-1层链接到第l层的第i个单元的链路集合。J代表了I中去除掉第j条链路后,所剩下链路集合的全部子集。|.|操作代表求取集合的元素个数。v(.)是Shapley值中计算边际收益的函数,这里使用Kernel SHAP方法来计算。
为了衡量每个单元对下一层的影响,定义了单元重要性(UI)。第l-1层的第j个单元的UI定义为:
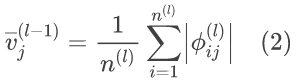
可以看到,每个单元的UI代表了其输出链路的重要性的平均值。因此,越大的值意味着对其下一层的影响越大。
SHAP-SAE算法
对于一个训练得到的自动编码器,为了制作一个轻量级的稀疏自动编码器,本文设计了一个掩码函数M,该函数只能激活训练后的自动编码器中的重要链接。M在疏化阶段执行掩蔽过程,如果M认为权重矩阵中的某个参数不重要,就会将其变为0。
为了得到这个掩码函数M,还需要进行一系列的计算。首先,定义第l层的总的LI为该层每个独立链路的LI的总和,即所有输入链路的重要性之和,计算公式如下:
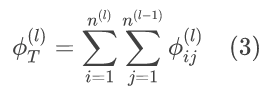
此外,将第l层的所有LI进行降序排列,得到一个新的集合:

实验
SHAP-SAE与合成数据集
为了验证所提出的SHAP-SAE的性能,首先考虑由15000个实例组成的合成数据集。x1是一组恒定的值。x2和x3是根据区间在[a,b]的均匀分布生成的。x2中的数据是从U(0,1)中采样的。x3包含从两个均匀分布中相等采样的数据,一个来自U(0,1/4),另一个来自U(3/4,1)。类似地,x4包含从两个高斯分布采样的数据,一个来自N(1/4,0.1),另一个来自N(3/4,0.1)。其他两个数据集和由这些数据集合成,即x5=x1+x2和
x6=x3+x4。
考虑一个简单的自动编码器结构,该结构由一个具有6个单元的输入层、一个具有3个单元的隐藏层和一个具有6个单元的输出层组成,已经提前训练得到了相应的权重矩阵。对其使用SHAP-SAE算法,设置重要性等级m=0.8。可以得到两个集合:

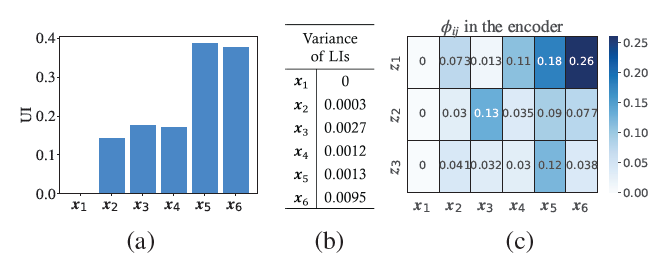
为了讨论所提出的SHAP-SAE的可解释性,量化了输入特征xi的UI和LI。数据集的UI如图2(a)所示,可以清楚地观察到x5和x6的UI显著高于其他输入特征。这是因为x5和x6包含了其他输入特征的信息。这也意味着x5和x6可以对自动编码器的训练做出更大的贡献。而x1是一个常数,对模型训练没有意义,因此UI为0。为了分析输入特征的分布对LI的影响,计算了LI的方差。从图2(b)可以看出,具有相似UI的数据集可能具有不同的方差。方差越大,相应的输入特征对下一层的影响就更为集中,具体结果可见图2(c)。
SHAP-SAE与真实世界数据集
考虑使用MNIST和Fashion MNIST数据集。数据集中的每个图像都被重塑为列向量,像素值在[0,1]的范围内进行归一化。
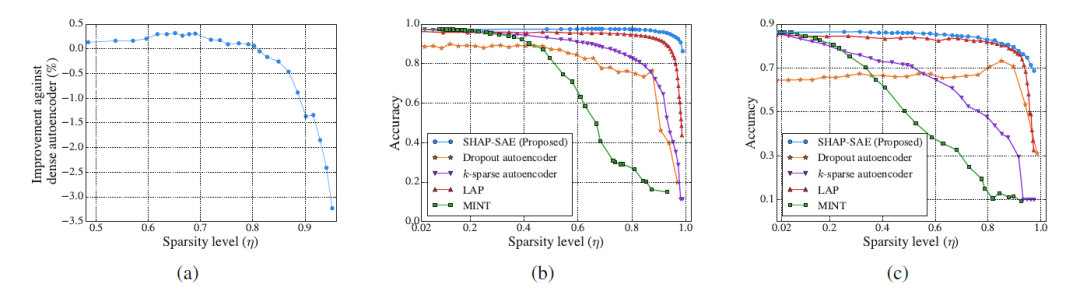
图3(a)显示了与密集型自动编码器相比,SHAP-SAE在精度方面的性能改进。可以预期,随着自动编码器变得越来越稀疏,性能会下降。但有趣的是,可以观察到,SHAP-SAE在η<=0.8时优于密集自动编码器。这是因为,根据Occam’s hill原理,最初的修剪可能会导致学习噪声的减少。直观来讲,较小的模型可以强制学习过程专注于模型的更重要和更一般的方面。
图3(b)和图3(c)显示了将SHAP-SAE的性能与其他自动编码器修剪算法进行比较的实验结果。可以清楚的看到,SHAP-SAE在一定的稀疏性范围内优于所有其他对比基准。
结论
在本文中,作者提出了SHAP-SAE算法来设计一个轻量级的自动编码器。SHAP-SAE算法可以基于Shapely值显式地测量自动编码器的单元和链路的重要性,从而只有重要的单元和链路才能被激活。这允许稀疏自动编码器在高稀疏性水平下具有可解释性和鲁棒性。实验结果表明,SHAP-SAE算法优于其他修剪算法。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
