
如今,屏幕内容图像呈现爆炸性增长。然而,针对自然图像设计的图像 SR (Super-Resolution,超分辨率)方法对于 SCIs(screen content images,屏幕图像内容)往往效果不佳,因为它们具有不同的图像特性,而且需要以任意比例浏览 SCI。因此,本文提出了一种新颖的 Implicit Transformer Super-Resolution Network (ITSRN)来处理 SCI SR。为了实现高质量的连续 SR,本文通过提出的隐式变换器将查询坐标处的像素值从键值坐标处的图像特征中推断出,并提出了一种隐式位置编码方案,用于聚合相似的相邻像素值。本文构建了 SCI1K 和 SCI1K-compression 数据集,包括 LR 和 HR SCI对。大量实验表明,提出的 ITSRN 在压缩和未压缩的 SCI 上都明显优于几种竞争性的连续和离散 SR 方法。
来源:NeurIPS 2021
题目:Implicit Transformer Network for Screen Content Image Continuous Super-Resolution
作者:Jingyu Yang, Sheng Shen, Huanjing Yue, Kun Li
原文链接:https://proceedings.neurips.cc/paper/2021/hash/6e7d5d259be7bf56ed79029c4e621f44-Abstract.html
内容整理:刘潮磊
引言
SR 的必要性:SCI(屏幕内容图像)需要经降采样、压缩以匹配低的终端带宽。需经 SR(超分辨率处理)之后重新成为高分辨率图像(HR)供人们观看。
SCI的特点:SCI有显著不同于自然图像的特征(如:边缘薄而锐利、对比度高)。另外,SCI 需要任意比例缩放。因此,针对 SCI 设计 SR 算法很有必要。
传统SR算法:一方面是针对自然图像设计的;另一方面常常只能用于不连续的放大比率。
贡献
提出ITSRN(Implicit Transformer Super-Resolution Network):最大特点是从坐标中推断出像素特征值。
提出IPE(Implicit position encoding):利用邻近查询点的关系优化预测出的像素特征值。
Dataset:建立了 SCI1K 和 SCI1K-compression 两个数据集,包含了大量屏幕内容图像。后者是用 JPEG 压缩将低分辨率图像进一步处理后的数据集。
相关工作
Implicit neural representation
核心思想:真实世界的物体可以视为一个坐标到像素值的连续函数,INR 通过神经网络逼近这个连续函数。
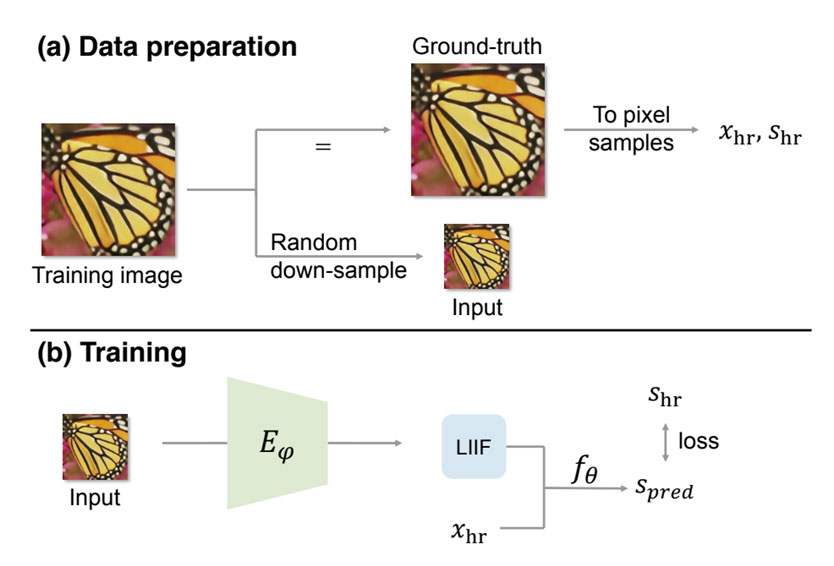
上图为 LIIF 中的隐式神经表示方法,也是隐式神经表示的一般形式,其中:Data preparation:将数据预处理成高分辨率和低分辨率的图片。Training:低分辨率图片经过一个 encoder,得到feature map,然后与高分辨率图像坐标(x,y)一起输入一个 MLP 预测高分辨率图像的像素值。
Super resolution for compressed screen content video
- 算法引入了重构模块解决压缩伪影的问题。
- 但是算法并没有针对屏幕内容特点设计,仍由全卷积层构成。
- 并且算法是利用前一帧重建当前帧,不适用于逐帧的SCI SR。
MetaSR
- 引入了 meta-upscale 模块实现连续放大倍率。
- 但是算法对于不在训练范围内的上采样因子效果不好。
- 只需要一个权重预测网络就能实现任意比例放大,不需要存储大量的权重信息。
框架
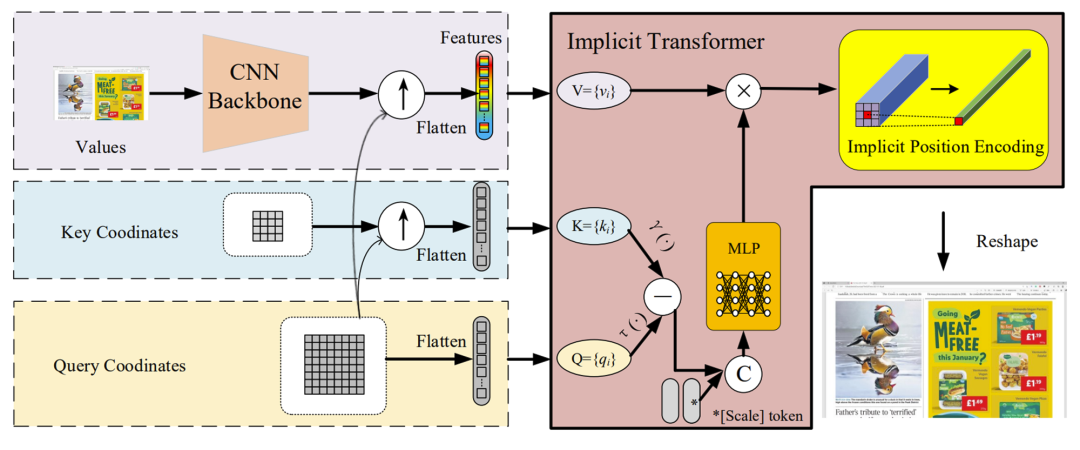
Step1:
1.低分辨率图像经过 CNN Backbone 并展平成为输入网络的 Features;
2.键值坐标展平成为输入网络的 K;
3.查询点坐标展平作为输入网络的 Q。
Step2:
1.将K、Q相减,并引入用于表示全局的放大因子 scale token;
2.通过 MLP 将其映射为另一个向量;
3.与 Features 相乘得到初步的查询点像素特征值。
Step3:
经过隐式位置编码,利用不同查询点之间的关系,同时防止相邻点的不连续性。
方法
Implicit Transformer Network
隐式 transformer 函数如下(LIIF算法中的形式):
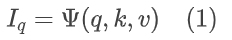
各参数含义:与 transformer 不同,transformer 中 q、k 是像素特征值经变换之后的参量。隐式 transformer 中 q、k 分别是 HR 和 LR 中的像素坐标;v 是键值坐标处的像素特征值;I_q 是预测出的查询点像素特征值。
由于 q、k 是坐标,与 v 的物理意义不同,这篇论文在 LIIF 的基础上将二者分开表示,于是可以将网络表示成以下形式:
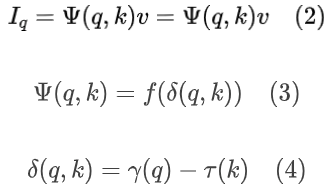
其中,𝛿 是表示 q、k 关系的函数,f 将其映射成另一个向量,再与v相乘,实现坐标到像素特征值的变换。𝛿 可以用点积、哈达玛积等方式实现,论文中采用上式的形式,𝛾、𝜏 可以是可训练函数,也可以是恒等映射。
引入scale token:scale token 用于表示全局的放大因子,是一个二维向量,分别代表在纵、横方向上的上采样比例。引入之后网络就能将查询点的像素形状作为一个额外条件,以便更好地重建目标点RGB值。引入之后,网络函数可表示为:
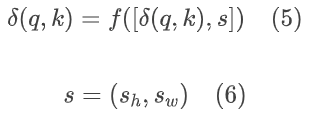
Implicit Position Encoding
隐式位置编码的引入是为了更好地利用不同查询点之间的关系,同时防止相邻点的不连续性。因为已经以q、k的方式将位置的绝对坐标表示出来,所以不用再像显示位置编码一样去编码位置信息。隐式位置编码是对一个局部邻域中的像素特征值进行编码,使得最终的预测值取决于邻近像素的像素特征值。网络函数如下:
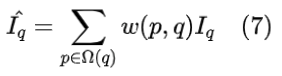
其中,Ω(q) 是以q为中心的局部邻域;w代表了相邻点p对查询点q像素特征值的贡献度(可以用高斯滤波器、双边滤波器实现)。
实验
Datasets: 既有自己构建的数据集 SCI1K 和 SCI1K-compression,也有已有的数据集 SCID 和 SIQAD。
Training Details: 训练时为了模拟连续放大率,将降采样因子设置为均匀在1到4之间。
与其他方法的对比
下图是论文算法与现有最先进算法重建结果比较:

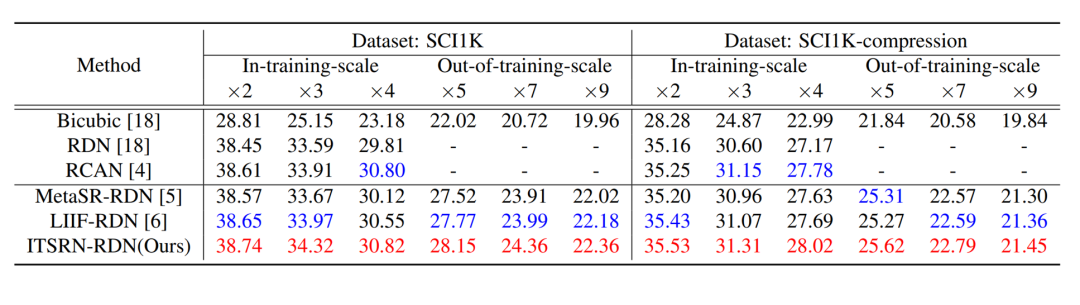
下图是在作者建立的数据集(SCI1K)上以 PSNR(dB) 为指标的论文算法与现有最先进算法的对比结果:
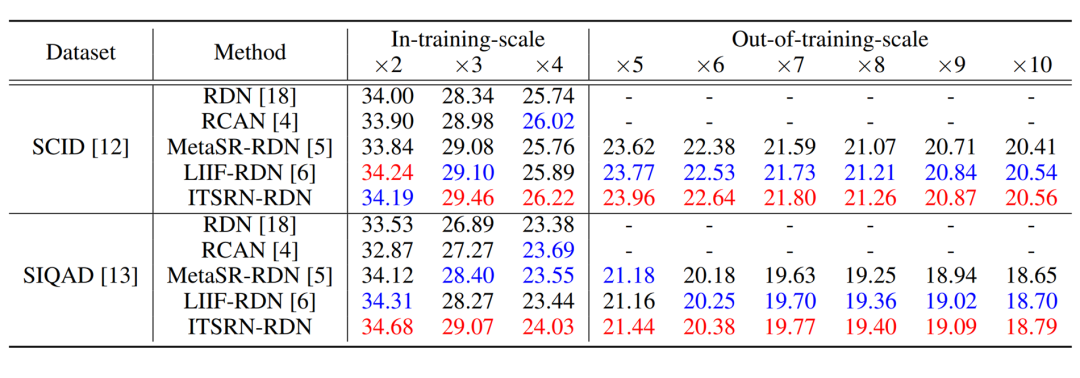
下图是在现有的数据集上以 PSNR(dB)为指标的论文算法与现有最先进算法的对比结果:
消融实验
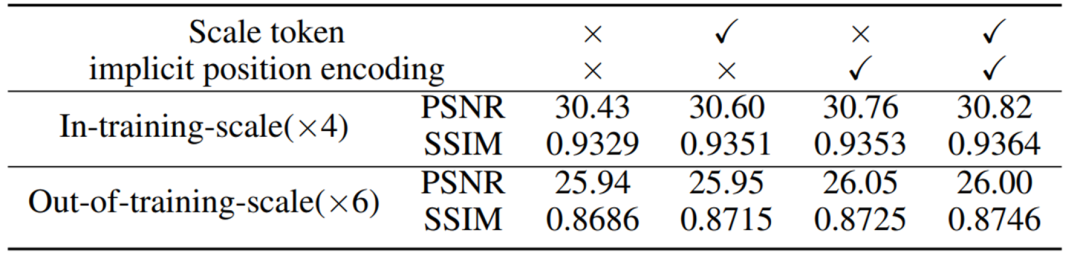
下图是对 scale token 和 implicit position encoding 进行消融实验的结果:
下图是隐式位置编码中用固定的 w 与论文方法学习得到的 w 在不同放大比率下的对比结果:

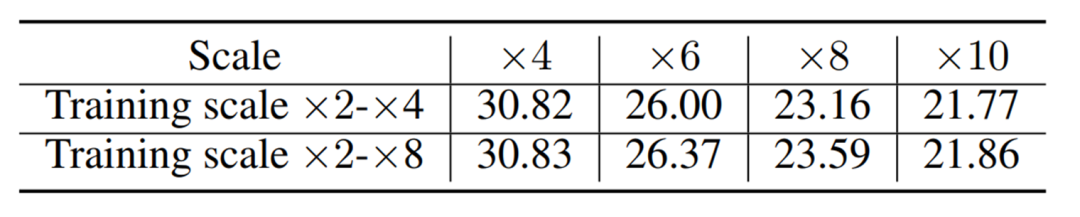
下图是不同训练范围下的SR对比结果:
讨论
本文提出了一种新颖的屏幕内容图像任意比例超分辨率(SR)方法。通过使用隐式 transformer 网络和隐式位置编码模块,在四个不同放大倍数的数据集上实现了最佳效果。由于具备连续放大功能,我们的方法使用户能够在各种不同尺寸的屏幕上显示接收到的屏幕内容。此外,本文构建了第一个屏幕内容图像 SR 数据集,将有助于更多关于这一主题的研究。另外,本文使用双三次插值和 JPEG 压缩来模拟降级过程,这可能与传输和采集中的实际降级不同。因此,在实际应用中存在一定限制。未来,可以开发基于盲失真的 SCI SR,以使模型更好地适应实际情况。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
