
视频着色任务最近引起了广泛的关注。近期的方法主要致力于相邻帧或间隔较小的帧的时间一致性。然而,它仍然面临着大间隔帧间不一致的严峻挑战。为了解决这个问题,本文提出了一种新颖的视频上色框架,它将语义对应结合到自动视频上色中以保持远程一致性。大量的实验表明,提出的方法在保持定性和定量的时间一致性方面优于其他方法。在 NTIRE 2023 视频着色挑战赛中,本文方法在颜色分布一致性 (CDC) 优化赛道中排名第三。
来源:CVPR 2023
作者:Yu Zhang, Siqi Chen等
代码链接:https://github.com/bupt-ai-cz/TCVC
内容整理:王寒
引言
视频上色任务可以认为是给定每一帧 L 通道的信息,获得 AB 通道。要求生成的 AB 通道首先要尽可能的与真值相似,其次还要保证帧间一致性,这种一致性不仅体现在相邻帧,远距离帧也要考虑到。最近的自动上色算法使用前面的相邻帧作参考,将视频上色以马尔可夫的方式进行。一些基于参考的上色方法在参考前面的相邻帧的同时还参考输入的参考帧,通过参考帧的监督来实现对上色风格的控制。参考帧的选取无疑是需要大量时间的,因此本文提出了一种两阶段的上色方法,自动生成参考帧并指导上色。
网络
算法的整体框架如图 1 所示。网络主要由三个部分组成:参考上色网络、图像上色网络和语义对应网络。参考上色网络使用视频的第一灰度帧生成彩色参考图像。然后,语义对应网络和图像着色网络利用该参考来监督整个着色过程。
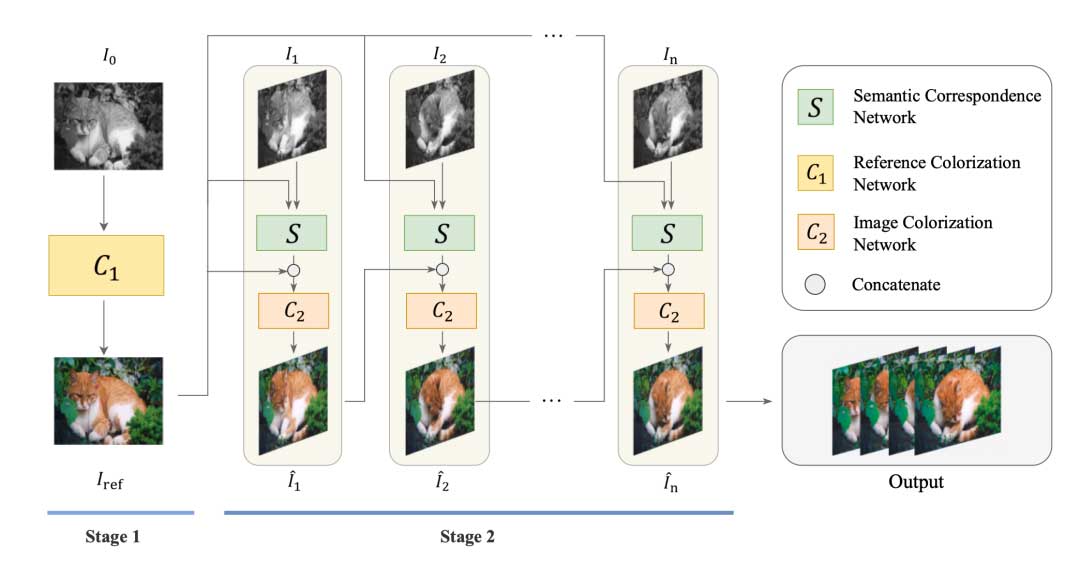
首先,设计参考上色网络来自动对每个视频的第一帧进行上色,获得参考图像来监督接下来的整个过程。这种自动上色的参考图像不仅可以避免费力且耗时的手动选择,还可以增强参考图像与灰度图像之间的相似性。然后,引入语义对应网络和图像上色网络,在参考的帮助下对一系列剩余帧进行上色。每个帧都由参考图像和直接上色的前一帧进行监督,以提高短程和长程时间一致性。
两阶段上色
第一阶段涉及自动参考着色网络,第二阶段包括语义对应网络和图像着色网络。在第一阶段,选择每个视频的第一帧进行自动着色。然后得到的图像被视为第二阶段的参考图像。

其中 S 代表语义对应网络,C2表示第二阶段的上色网络。基于以上设计我们的方法能更好地保留时间一致性。
损失函数
作为一个固有的模糊问题,直接比较真实图像和生成图像之间的色差是不合适的。最近,感知差异已被证明对于两种看似合理的颜色引起的外观差异具有鲁棒性。它比较了预训练 VGG-19 网络提取的特征 reluL_2 之间的差异。在本文中,利用了从粗到细的感知损失:
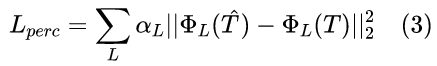
这里 L 取3,4,5对应的 αL取0.02,0.003,0.5作为权重。从粗到细的策略涉及高级和低级特征表示的比较。
此外,我们凭经验发现 L1 损失有助于网络的收敛,而平滑损失有助于减少渗色。此外,还采用 PatchGAN 来提高高频颜色保真度。它将每个 patch 分类为真或假,而不是整个图像。对于第一阶段的网络,总体目标损失可以写为:
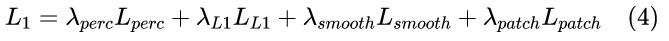
对于第二阶段的网络,进一步采用时间扭曲损失来约束时间一致性。相应的客观损失为:
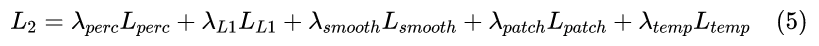
实现
网络结构
参考着色网络是一种具有 skip 连接、组卷积和扩张卷积的编码器-解码器结构。语义对应网络是具有非局部操作的 CNN-Transformer 结构。图像上色网络将第一阶段的编码器-解码器结构与 Transformer 分支相结合。
第二阶段的网络结构与 Exemplar-based video colorization with long-term spatiotemporal dependency 基本相同。
训练细节
两个阶段网络的训练过程是独立的。对于第一阶段的网络,参考上色网络在来自 ImageNet、REDS、DAVIS 、SportMOT 的图像以及 NTIRE 2023 视频着色挑战赛中的官方训练集上进行训练。我们删除颜色模糊、颜色单调、低分辨率或灰度的图像(图2)。训练涉及大约 110 万张图像。对于第二阶段的网络,训练集包括 DAVIS、Videvo 和 FVI 数据集。总共收集了2090个视频。以帧传播的方式训练网络(即每个视频中的第一帧被视为参考图像)。使用预训练模型用于初始化参数,可以参考发布的代码以了解更多实现细节。

算法效果
图3展示了在 Videvo 测试集上与最先进方法的视觉比较,本文方法获得了最丰富多彩且一致的结果。
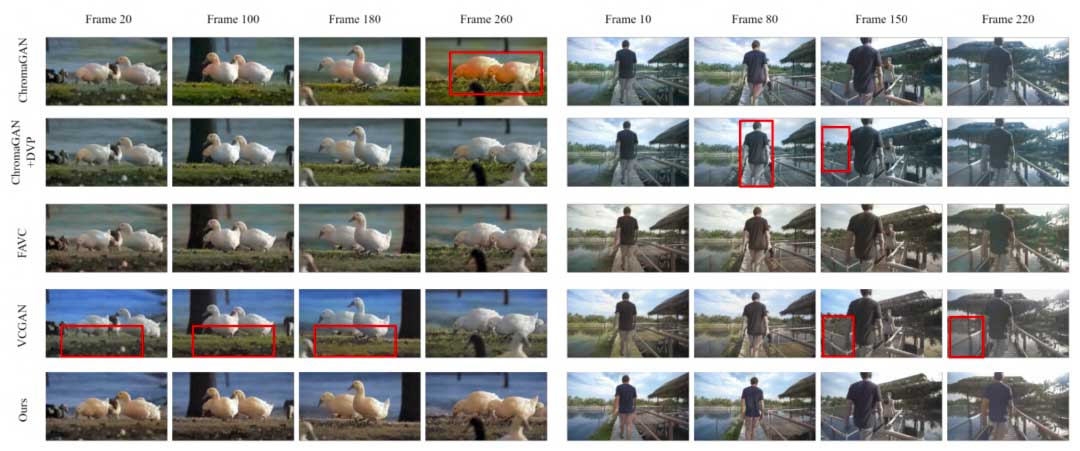
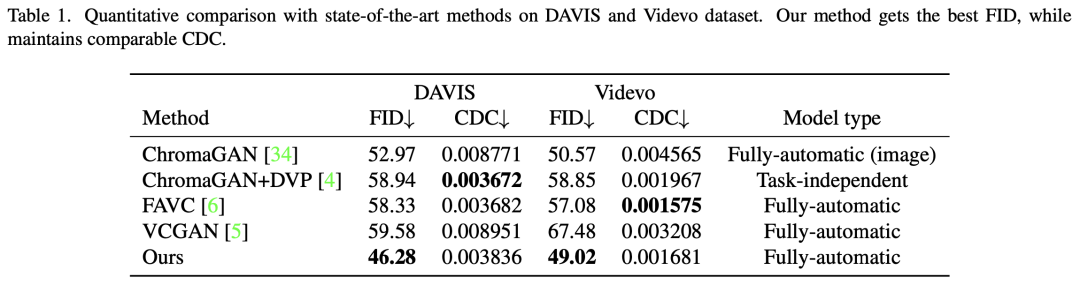
表1展示了在 DAVIS 和 Videvo 数据集上与最先进的方法进行定量比较。我们的方法获得了最佳的 FID,同时保持了可比的 CDC。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
