
在实际计算机视觉应用中,由于图像通常很大,它们必须被降采样到神经网络的预定输入尺寸。传统的空间降采样方法会导致网络准确性下降,本文提出通过在频域学习并选择适当的频率分量,可以提高网络准确性,并减少输入数据大小、降低带宽压力。
论文标题:Learning in the Frequency Domain
论文来源:CVPR 2020
作者:Kai Xu, Minghai Qin, Fei Sun, etc. DAMO Academy, Arizona State University.
论文链接:https://openaccess.thecvf.com/content_CVPR_2020/papers/Xu_Learning_in_the_Frequency_Domain_CVPR_2020_paper.pdf
内容整理:陈予诺
引言
深度神经网络在计算机视觉任务中取得了显著的成功。对于输入图片,现有的神经网络主要在空间域中操作,具有固定的输入尺寸。然而在实际应用中,图像通常很大,必须被降采样到神经网络的预定输入尺寸。尽管降采样操作可以减少计算量和所需的通信带宽,但它会无意识地移除冗余和非冗余信息,导致准确性下降。受数字信号处理理论的启发,我们从频率的角度分析了频谱偏差,并提出了一种可学习的频率选择方法,可以在不损失准确性的情况下移除次相关的频率分量。在下游任务中,我们的模型采用与经典神经网络(如ResNet-50、MobileNetV2和Mask R-CNN)相同的结构,但接受频域信息作为输入。实验结果表明,与传统的空间降采样方法相比,基于静态通道选择的频域学习方法可以实现更高的准确性,同时能够减少输入数据的大小。具体而言,在相同的输入尺寸下,所提出的方法在ResNet-50和MobileNetV2上分别实现了1.60%和0.63%的top-1准确率提升。当输入尺寸减半时,所提出的方法仍然将ResNet-50的top-1准确率提高了1.42%。此外,我们观察到在COCO数据集上的分割任务中,Mask R-CNN的平均精度提高了0.8%。
方法
整体框架
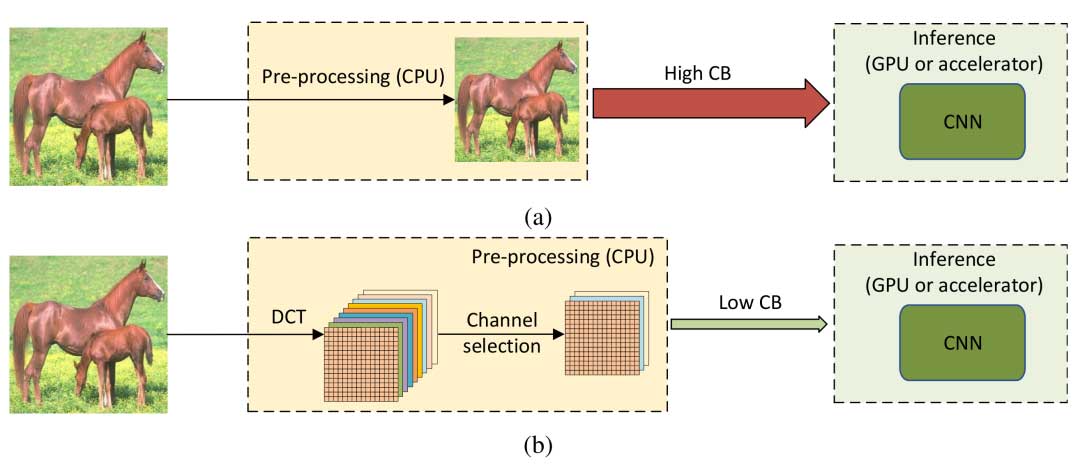
整体流程上,(a) 所示为使用RGB图像作为输入的基于CNN的方法的工作流程。(b) 所示为使用DCT系数作为输入的方法的工作流程。CB表示CPU和GPU之间所需的通信带宽。
由于RGB格式的未压缩图像通常很大,CPU和GPU之间的通信带宽要求通常很高。这样的通信带宽可能成为系统性能的瓶颈,如(a)所示。为了减少计算成本和通信带宽的需求,高分辨率的RGB图像被降采样为较小的图像,而这往往会导致信息丢失和推理准确性降低。
在本文方法中,高分辨率的RGB图像仍然在CPU上进行预处理。然而,它们首先被转换到YCbCr颜色空间,然后转换到频域。这与最常用的图像压缩标准(如JPEG)相吻合。相同频率的所有分量被分组到一个通道中,经过通道筛选后降低数据量,此时CPU和GPU之间的通信带宽压力减小。
频域通道选择
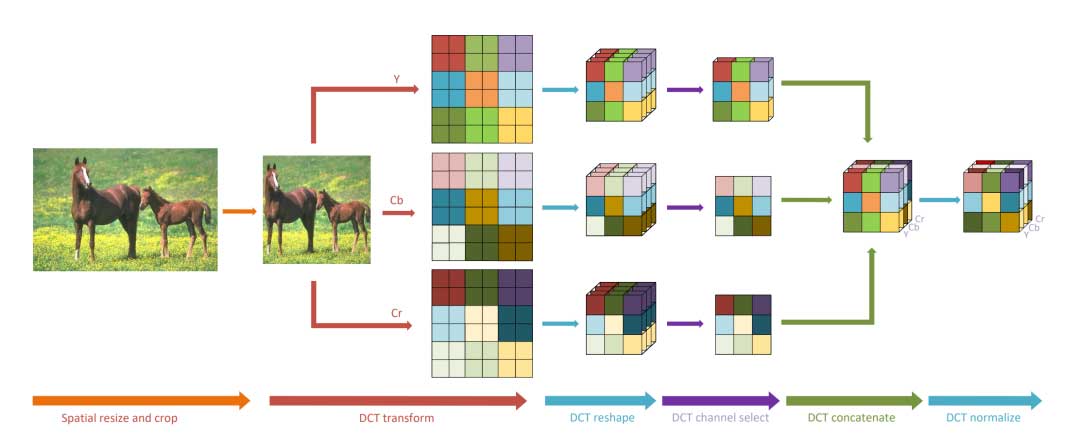
本文遵循空间域中的预处理和增强流程,包括图像的大小调整、裁剪和翻转。然后,图像被转换为YCbCr颜色空间并转换为频域。相同频率的二维DCT系数被分组到一个通道中,形成三维DCT立方体(上图中的DCT reshape)。本文通过特定的方法,选择一部分具有影响力的频率通道。在YCbCr颜色空间中选择的通道被连接在一起形成一个张量。最后,每个频率通道都通过从训练数据集计算的均值和方差进行归一化。
在 DCT reshape 操作中,类似于JPEG压缩标准在YCbCr颜色空间上使用8×8的DCT变换,我们将所有8×8块中相同频率的分量分组到一个通道中,保持它们在每个频率上的空间关系。因此,每个Y、Cb和Cr分量提供了8×8=64个通道,总共192个通道。假设原始RGB输入图像的形状为H×W×C,其中C = 3,图像的高度和宽度分别表示为H和W。转换为频域后,输入特征的形状变为H/8×W/8×64C,保持相同的输入数据大小。
由于频域中的输入特征图在H和W维度上较小,但在C维度上较大,我们跳过传统CNN模型的输入层。如果紧接着输入卷积层之后是一个最大池化操作(例如ResNet-50),我们也会跳过最大池化操作。然后,我们调整下一层的通道大小,以匹配频域中的通道数。如下图所示。通过这种方式,我们最小限度地调整现有的CNN模型,使其能够接受频域特征作为输入。
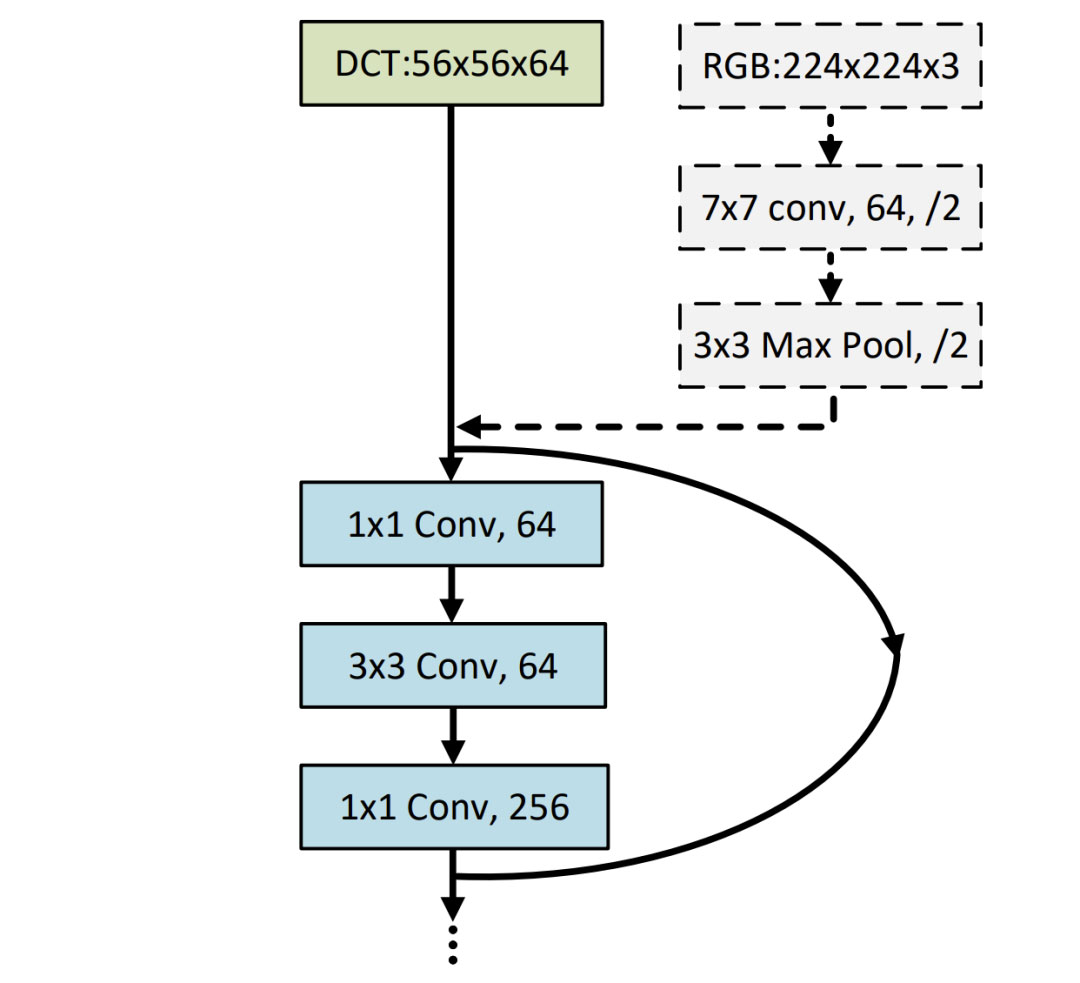
在图像分类任务中,CNN模型通常接受形状为224×224×3的输入特征,这通常是从分辨率更高的图像进行下采样得到的。当在频域中进行分类时,可以将更大的图像作为输入。以ResNet-50为例,频域中的输入特征与第一个残差块连接,通道数调整为192,形成形状为56×56×192的输入特征。这是从大小为448×448×3的输入图像经过DCT变换得到的,相比空间域中的224×224×3对应物,保留了四倍的信息,但输入特征大小增加了4倍。类似地,对于MobileNetV2模型,输入特征的形状为112×112×192。
动态通道选择
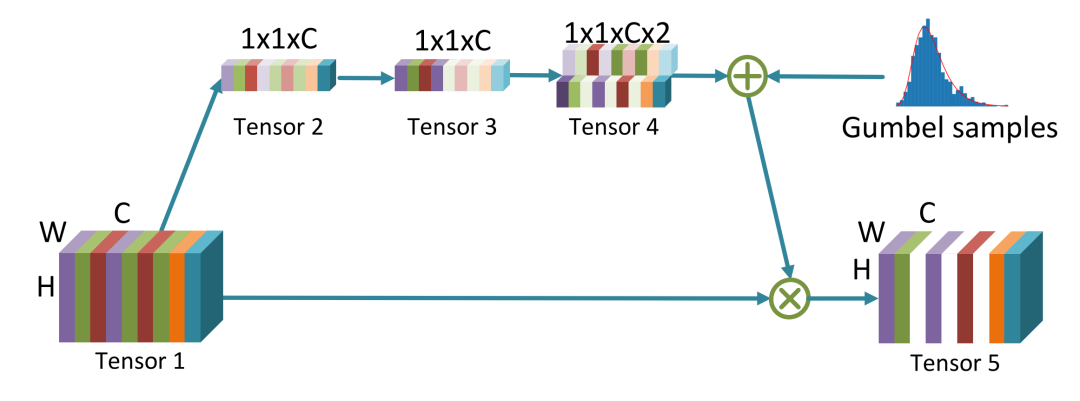
上图详细描述了本文提出的通道筛选模块。输入的形状为W×H×C(本文中C=192),具有C个频率通道。首先,通过平均池化将其转换为形状为1×1×C的张量2。然后,通过一个1×1卷积层将其转换为形状为1×1×C的张量3。从张量1到张量3的转换与两层Squeeze-and-Excitation块(SE-Block)完全相同,它利用通道信息来强调有信息的特征并抑制无关的特征。然后,通过将张量3中的每个元素与两个可训练参数相乘,将张量3转换为图中形状为1×1×C×2的张量4。在推断过程中,张量4中每个频率通道的两个数字被归一化,并作为被采样为0或1的概率,然后逐点地与输入频率通道相乘,得到图4中的张量5。例如,如果张量4中第i个通道的两个数字是7.5和2.5,则第i个门关闭的概率为75%。换句话说,张量5中的第i个频率通道在75%的时间内都变为零,这有效地阻止了该频率通道在推断过程中的使用。
我们的门控模块与传统的SE-Block有两个不同之处。首先,提出的门控模块输出一个维度为1×1×C×2的张量,其中最后一个维度中的两个数字分别描述了每个频率通道打开和关闭的概率。因此,我们添加了另一个1×1卷积层进行转换。其次,乘以每个频率通道的数字要么是0,要么是1,即使用或不使用的二进制决策。该决策是通过对 Bernoulli 分布 Bern(p) 进行采样得到的,其中p由上述1×1×C×2张量中的2个数字计算得到。
由于Bernoulli采样过程是不可微的,我们采用了一种 reparameterization 方法,称为 Gumbel Softmax 技巧,它允许梯度通过离散采样过程进行反向传播。
动态通道选择实验
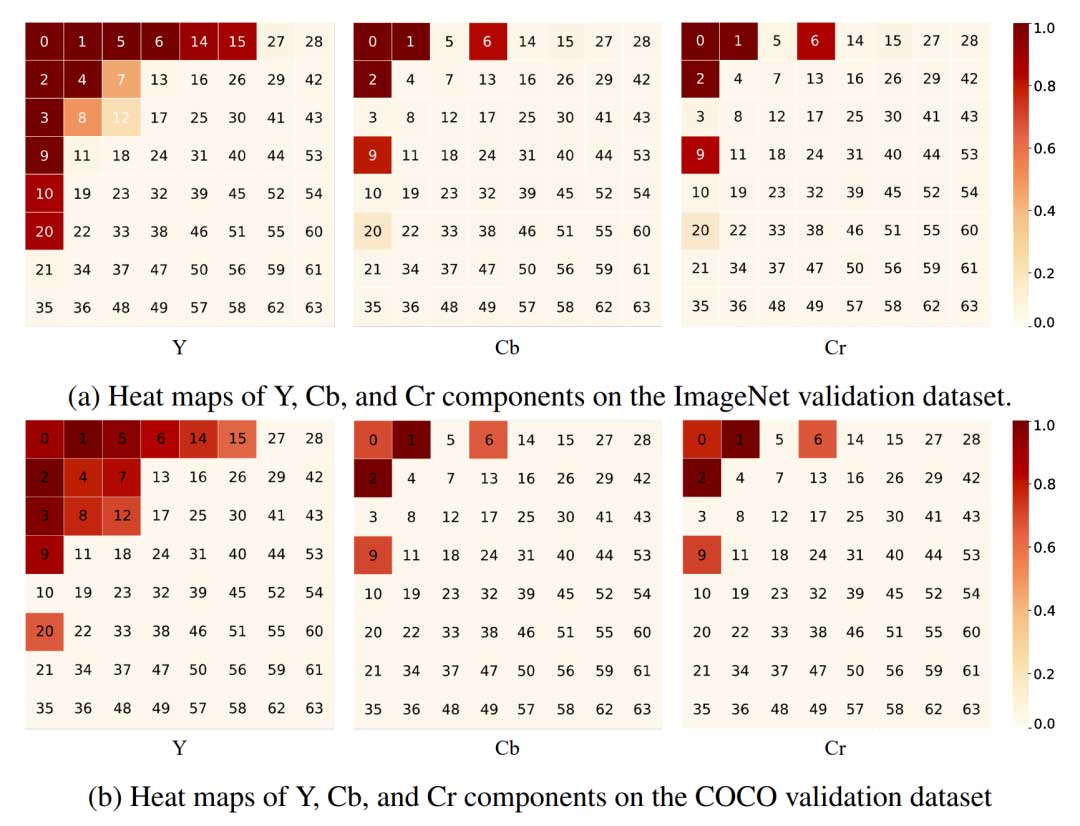
基于学习的通道选择提供了每个频率通道重要性的动态估计,即不同的输入图像可以激活不同的频率子集。为了理解频率通道激活的模式,我们绘制了两个热力图,一个用于分类任务(a),一个用于分割任务(b)。
每个方框中的数字表示频率通道的频率索引,较低和较高的索引分别表示较低和较高的频率。热力图的值表示在所有验证图像中选择该频率通道进行推断的可能性。
根据上图中热力图中的模式,我们得出以下几点观察结果:• 低频率通道(具有较小索引的方框)比高频率通道(具有较大索引的方框)更常被选择。这表明低频率通道在视觉推断任务中比高频率通道更具信息量。• 亮度分量Y中的频率通道比色度分量Cb和Cr中的频率通道更常被选择。这表明亮度分量对视觉推断任务更具信息量。• 热力图在分类和分割任务之间共享一种共同模式。这表明上述两点观察结果不仅适用于一个任务,而且很可能适用于更多高级视觉任务。• 有趣的是,一些较低频率的频率通道被选择的概率比稍高频率的频率通道低。例如,在Cb和Cr分量中,两个任务都更喜欢频率通道6和9,而不是频率通道5和3。
实验
分类任务
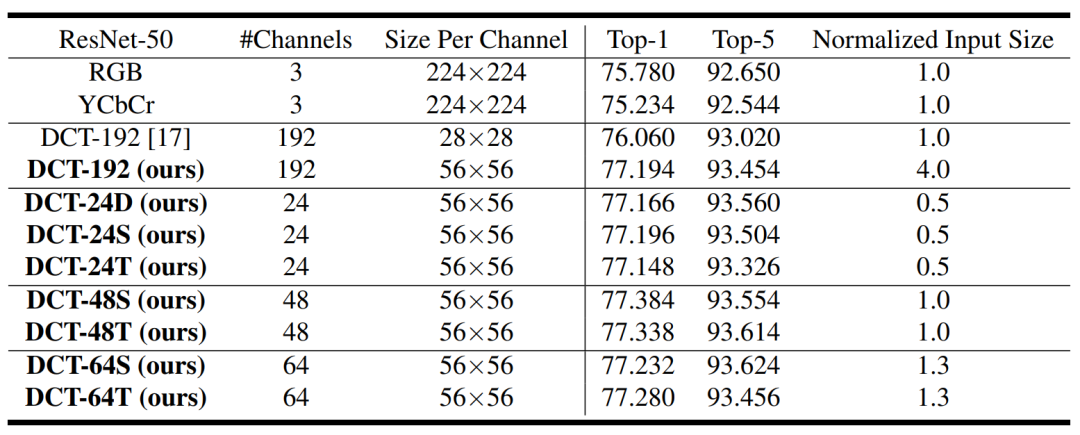
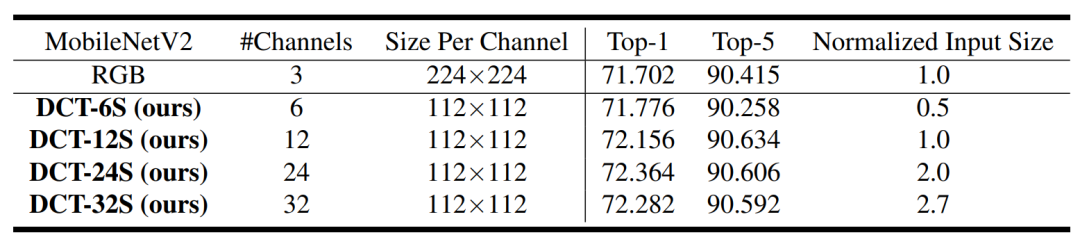
在分类任务中,由于观察到热力图中低频信息的重要性更高,我们探索了所选频率的精确形状。在表1中,DCT-24D显示了基于动态选择结果的精确选择了24个(14+5+5)频率通道时的准确性。相比之下,DCT-24T和DCT-24S显示了Y、Cb、Cr分量总共选择的24个频率为左上三角形和方形时的准确性。这三者之间 top1 准确性的变化几乎可以忽略不计,而且它们的性能都比基准的ResNet-50高出大约1.4%。这表明,只要选择了大多数低频率通道,所提出的频域学习就可以应用于许多任务。请注意,输入数据的大小只有基准ResNet-50的一半。
类似地,我们的DCT-48S/T选择了前(32,8,8)个频率通道,DCT-64S/T选择了前(44,10,10)个频率通道。与基准ResNet-50相比,使用所有频率通道的 top1 准确性提高了1.4%。还应注意到,当输入只是从RGB转换为YCbCr颜色空间时,准确性会下降。
分割任务


分割任务中,我们使用频域中的192个频率通道输入来训练我们的Mask R-CNN模型。动态频率通道选择的模块与整个Mask R-CNN一起进行训练。我们进一步使用仅前24、48和64个高概率频率通道来训练我们的模型。分别在上面两表中报告了不同情况下我们方法的准确度。实验结果表明,与基于RGB的Mask R-CNN基准相比,我们的方法在相等(DCT-48S)或更小(DCT-24S)的输入数据大小下表现更好。具体而言,选择24个频率通道的模型(DCT-24S)在输入数据大小减少一半的情况下,bbox AP and mask AP上相较于基于RGB的Mask R-CNN基准分别提高了0.4。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
