
简介:该工作由上海交通大学宋利教授带领的Medialab实验室产出,并于近期被ACM MM 2023所接收。360度全景图在计算机图形学及视觉领域应用广泛,相比于手机等移动设备即能拍摄的窄视场图片(Narrow Field of View,NFoV),获取360°×180°的全景图成本较高。先前的全景图生成工作可以从单张NFoV图像生成全景图,但它们在输入模式的多样性、生成图像质量和可控性方面存在不足。针对这些不足,我们提出了PanoDiff,它可以从一张或多张从任意角度拍摄的未标注pose的NFoV图像生成360°全景图。我们方法核心包括:一个两阶段角度预测模块,用于处理各种数量的NFoV输入。一种基于隐式扩散模型的全景生成网络,使用不完整的全景图和文本提示作为控制信号,并利用几种几何增强方案来确保生成图像的全景图几何属性。实验表明PanoDiff实现了SOTA的全景生成质量,并且可控性高,适用于内容编辑等各种应用。
来源:ACM MM 2023
论文标题:360-Degree Panorama Generation from Few Unregistered NFoV Images
论文链接:https://arxiv.org/abs/2308.14686
作者:Jionghao Wang, Ziyu Chen, Jun Ling, Rong Xie and Li Song
内容整理:陈梓煜
介绍
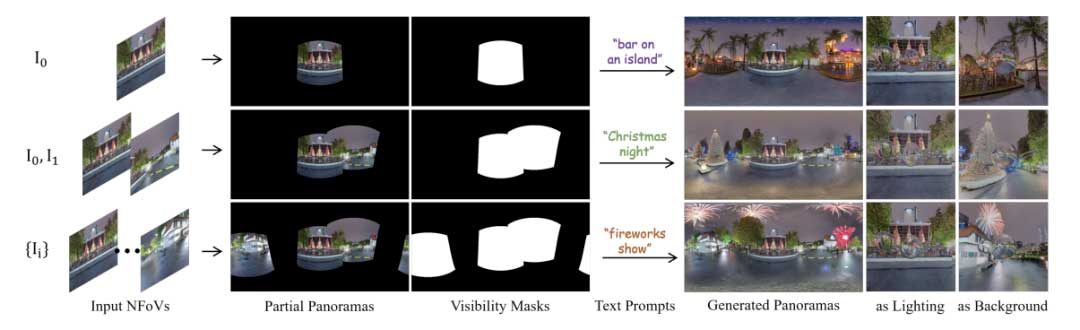
全景图像捕捉的视场广泛,包括360°水平方向和180°垂直方向视场范围。全景图在各种应用中变得越来越重要,例如环境照明、虚拟现实/增强现实和自动驾驶系统。但是获得高质量的全景图像可能既耗时又昂贵,因为通常需要使用专门的全景相机或拼接软件将来自多个角度的图像合并在一起。
我们的方法解决了以前生成方法的两个主要限制,即输入灵活性和生成质量与可控性。
- 输入模式: 大多数以前的工作仅支持将单张NFoV图片作为一个不完整全景图的中心区域。但是仅依赖这一中心区域,要控制所生成场景的特定内容时会限制灵活性。这种灵活性对于需要精确控制生成的内容并确保准确呈现实际场景的应用特别重要。
- 生成质量与可控性:。从NFoV图像生成完整的360度全景图可以被视为一个图像外绘问题,以前的方法通常都依赖于基于生成对抗网络(GAN)的方法。此外,以前的方法将这个问题视为一个图像条件生成任务,使得他们的流程对于生成结果的控制和灵活性都很小。
ImmerseGAN使用额外的文本指导来进行基于GAN的全景图生成。但是基于Diffusion的图像生成方法在很多生成任务上都展现出了更好的效果。此外,GAN的模式覆盖有限,很难扩展到对复杂多模态分布进行建模。与GAN不同,基于Diffusion的模型能够学习自然图像的复杂分布,从而生成高质量的图像。为了克服上述限制,我们的目的是设计一个能够接受不固定数量NFoV图像输入,并生成高保真度全景图的方法。面临两个主要挑战:
- 估计NFoV图像的相对相机姿态并准确地将这些NFoV图像映射到全景图上
- 使用基于隐式diffusion的方法从各种类型的不完整全景图生成完整的全景图。
我们提出了PanoDiff,该方法可以从一张或多张从任意角度拍摄的未标注相机姿态的NFoV图像有效地生成完整的360°全景图。首先,我们提出了一个鲁棒的两阶段相对相机姿态预测模块,该模块对NFoV图片对的重叠情况和相对角度进行预测。其次,我们训练了一个Hypernet,将stable diffusion应用在全景图生成任务上,并在训练和推断采样阶段都使用了几种几何增强方案,以确保生成的图片具有全景图的几何属性。
NFoV图片对的相对相机姿态估计
问题定义
不同于以前的全景图生成流程,我们的方法可以接受单个或多个NFoV图像作为输入。对于在相同位置但不同姿态下拍摄的多个NFoV(窄视场)图像,我们的目标是估计它们之间的相对姿态。在全景图像的设定下,不涉及相机平移,我们将相对相机姿态形式化为旋转角度。具体而言,我们将360°全景图视为一个球面映射,并将旋转角度表示为:1)方向,其中包括经度α、纬度β。2)滚动角γ。
如果是单个图像,我们的流程仅估计β并将其放置在横向中心,即 α = γ = 0。形式上,对于一组N个NFoV图像 I = I 0,I 1,…,I N-1,我们旨在学习一个模型 Rθ,该模型预测它们的相对角度:

二阶段角度估计
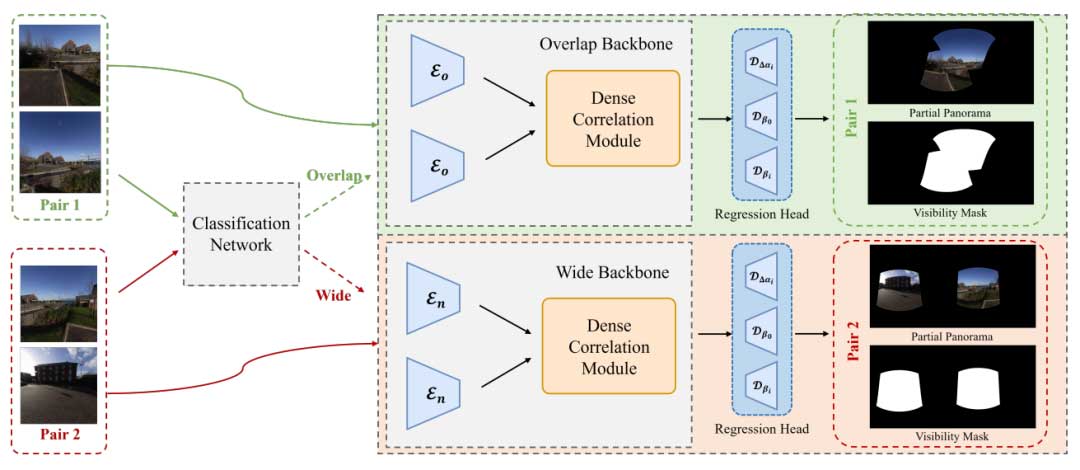
基于同一场景的不同NFoV图像的重叠情况,我们将图像对的关系分为两种不同类型:重叠和不重叠。在重叠场景中(图2中的绿色对),两个NFoV图像共享一部分其FoV,从而在全景图上产生重叠。相反,在不重叠情况下(图2中的红色对),NFoV图像对没有重叠的FoV,导致全景图上有两个独立的区域。
但是单一的回归网络难以区分这两种情况,有时可能会将没有任何重叠的图像预测为有重叠,导致较差的生成结果。此外,单一回归网络的精度表现也不佳。为了解决这些问题,我们提出了一个两阶段角度预测模块,首先进行分类以确定两个图像是否重叠,然后回归精确的角度[△αi->0,β0,βi]。这种方法显著减少了误判不重叠图像为重叠的问题。我们的旋转预测模块的概览如图2所示。
我们采用与ExtremeRotation[1]相同的主干结构,包括特征编码器和4D密集相关模块。在两阶段流程中,总共设计了三条分支,每条分支都有自己的预测头。为了估计图像对之间的相对相机旋转,我们首先将图像对传递给分类器,以确定图像是否重叠或相距较远。随后,根据分类结果,我们将图像对传递给相应的回归器,来进行相对位姿的估计。
全景图生成
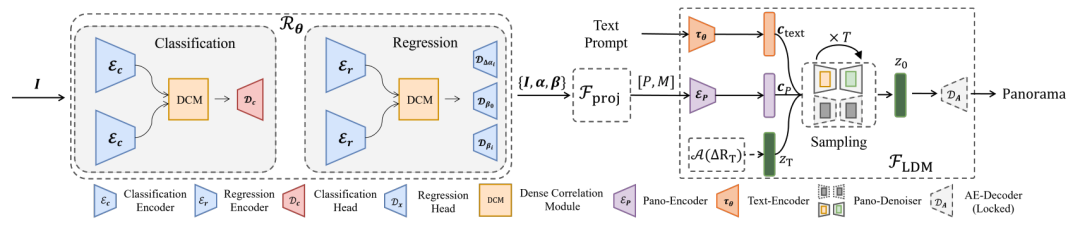
问题定义

使用隐式扩散模型生成全景图
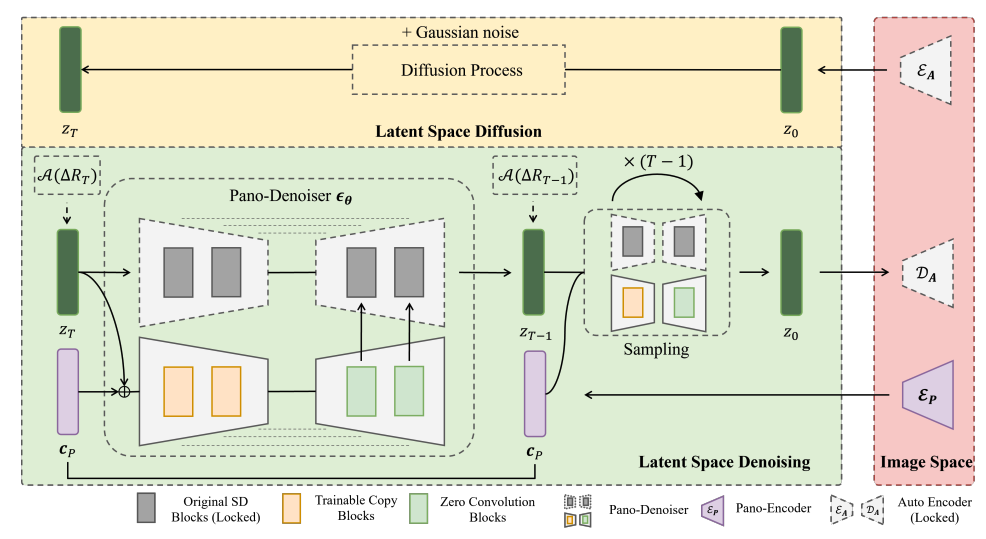

我们使用控制单元将控制信号引入预训练的Stable Diffusion模型中。在实践中,我们遵循ControlNet的方法,将控制单元添加到用于Stable Diffusion的去噪U-Net模型的四个编码器块和一个中间块中,同时在其他四个解码器块中使用零卷积。
除了全景去噪器(Pano-Denoiser),我们还加入了一个浅层的全景编码器(Pano-Encoder)Ep 来构建我们的控制条件。为了将图像空间信号作为控制信号传递到隐式空间,我们使用 Ep 将它们编码为与原始SD U-Net兼容的隐式特征,从而与我们的控制单元相匹配。然后,这些隐式特征传递到我们的可学习编码器和连接到原始SD U-Net的中间和解码器部分的零卷积中。
正如图4所示,在扩散过程中(图的上半部分),自编码器EA 将图像转化为特征空间,然后高斯噪声被迭代地添加到隐式特征中。在去噪过程中,我们的全景去噪器利用部分全景图 P 和Mask M作为控制信号,中对输入的噪声潜在 zr进行迭代去噪,直到生成 z0。最后, z0 通过自编码器的解码器 ED进行解码,生成最终的全景图。
保持360度全景图的特性
旋转等变性损失
在隐式空间中,全景图具有旋转等变性,即它们在旋转变换(限制为2个自由度,对应经度和纬度旋转的旋转)SO(3)下仍然能够表示相同的场景。我们的方法在隐式空间内运行,对于我们的去噪器,约束可以表达为:

旋转规划
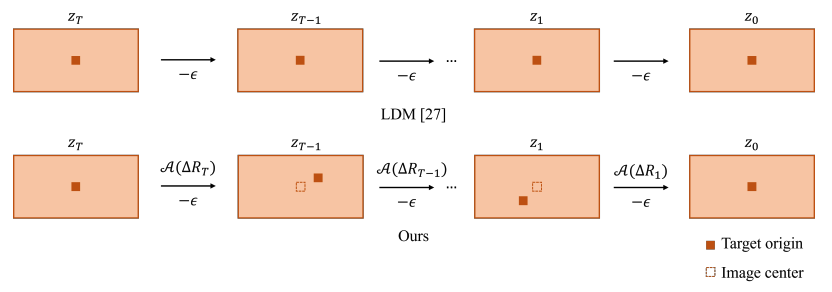
在推理过程中,我们采用如图5所示的旋转规划。去噪步骤在隐式特征 zi 逐步经历计划的变换A(△Ri)的情况下执行。需要注意的是,这个计划与训练阶段中的旋转约束一致,因为两者都涉及隐式空间中的相同类型的变换。旋转计划增强了我们方法的鲁棒性,并促进了具有改善几何完整性的全景图的生成。
连续性Padding
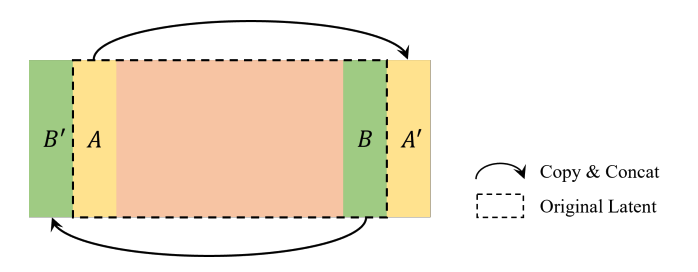
在隐式空间中运行的生成方法可能由于卷积操作的边缘效应而生成的全景图左右不连续。因此在推理时我们使用连续性Padding以减轻边缘效应。即将隐式特征的右侧部分连接到左侧,同时将原始隐式特征的左侧部分连接到右侧。该过程如图6所示。在采样过程之后,解码器生成的图像的形状为 (w + 2wp) x h,其中 wp 是来自填充特征的额外宽度。为了生成标准的全景图,从最终图像中去掉额外的宽度。
实验
定量评估
我们从相机相对位姿估计的准确性和全景图生成的质量两个方面来考察我们的方法的性能。
相对位姿估计
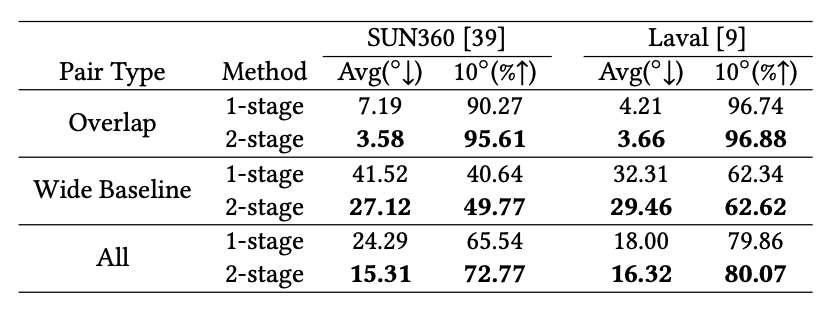
我们在SUN360和Laval Indoor数据集上评估了相对位姿估计的性能。为了清晰起见,我们根据输入的图片对是否重叠将输入图片对分为两类。我们比较我们提出的两阶段模型和一个与[1]相同设计的单阶段模型。表1表明在’重叠’和’不重叠’两方面,两阶段的相对位姿估计方法在平均相对姿态估计误差方面明显优于单阶段方法。
全景图生成
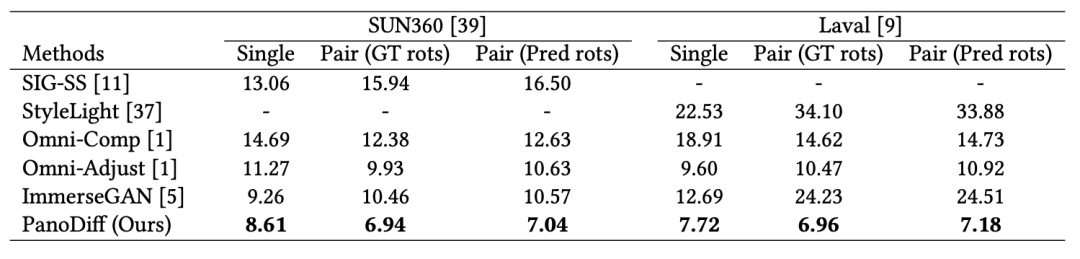
如表2中所示,我们的方法在两个数据集上的所有三种输入类型下都取得了SOTA的FID指标。其中“GT rots”和“Pred rots”分别表示使用了真实相对角度和我们的网络预测的角度。我们方法显著超越了其他方法,证实了其整体有效性。值得注意的是,我们的模型没有在Laval Indoor数据集上进行训练,但仍然在这个数据集上超越了之前专门在该数据集上训练的方法的性能。
定性比较
可视化结果如图7所示。为了说明我们方法的生成质量,我们分别使用了三种输入类型:单个NFoV输入(前两行),带GT rots的成对NFoV输入(中间两行),以及带Pred rots的成对NFoV输入(底部两行)。 从结果中可以看出,SIG-SS和Omni-Adjust在生成边界上表现出不一致等问题。虽然Omni-Comp生成的图像在边界问题上有所改善,但它们为了获得平滑的输出边界而牺牲了生成内容的质量和真实性。Omni-Adjust生成的内容相对更真实,但有时会生成错误的内容。例如,在第二行中,Omni-Adjust在输入区域指示草地场景时,错误地生成了一个海滩。ImmerseGAN在单个NFoV输入方面表现出色,但在处理多个NFoV时因缺乏特定的训练而效果不佳。PanoDiff在内容一致性、真实性和纹理连续性方面优于先前的方法,保持了生成内容的质量和真实性。

我们继续观察方法在Laval Indoor数据集上的泛化性能,如图8所展示。

应用
文本编辑
我们方法还具备良好的文本编辑能力。如图9所示,我们的方法不仅继承了Stable Diffusion的强大生成能力,还保留了全景图的良好几何特性。

背景贴图
全景图像可以用作3D计算机图形软件中的背景贴图,为3D模型提供背景光照。图10展示了我们生成的全景图作为背景贴图的示例。从中可以看出,我们的方法产生了多样的全景图,不仅可作为合理的渲染背景,还可以提供环境光照。

多NFoV作为输入
我们的框架包括一个两阶段的相对姿态估计模块,使其能够处理同一场景的多个NFoV图像(对于两张)作为输入。如图1和11所示,我们的流程能够鲁棒地使用多个NFoV图像生成高质量的全景图。

结论
我们提出了一个全新的全景图生成方法PanoDiff,可以从一张或多张NFoV图像生成360°全景图。该流程包含两个主要模块,即相对姿态估计和全景图生成。我们的两阶段相对姿态估计网络首先将输入图像对分类为重叠和不重叠情况,然后进行相对角度预测。在全景图生成中,我们使用不完整的部分全景图以及文本提示作为信号来生成多样的全景图。我们希望我们的工作能够激发关于全景图生成的进一步研究,包括风格控制、高动态范围全景图生成以及相关领域的应用。
[1]Cai, Ruojin, et al. “Extreme rotation estimation using dense correlation volumes.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
