
导读:Interspeech 是国际语音通信协会(ISCA)举办的年度会议,也是全球最大、最全面的专注于语音通信领域的学术盛会。2023 届 Interspeech 会议于 2023 年 8 月 20 日至 8 月 24 日于爱尔兰都柏林举办。网易易盾有 2 篇关于语音识别方向的学术论文成功被会议录用,网易智企技术+将就这两篇论文推出相关解读文章,本文为第一篇。
文 | 网易易盾 AI 实验室
来源:网易智企技术+
原文:https://mp.weixin.qq.com/s/DUZMPnf-MhkdzplfKItkrw
背景 · 多语言语音识别
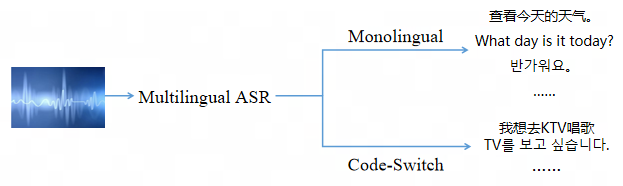
对于一个多语言语音识别(Multilingual ASR)系统来说,主要需要支持两个场景的语音识别。
- 一个是多种不同语言的单语识别。
- 第二个是 Code-Switch 语音的识别。Code-Switch 一般指句内的语码转换,比如说中文夹杂着英文。
这两个任务有各自的难点,因此兼顾单语和语码转换的多语言语音识别是一项具有挑战性的任务。
相关工作 · 专家混合模型
近年来,学术界和工业界有很多工作在这个问题上取得了不错的进展。比较有代表性的是基于专家混合模型(MoE)的方法。MoE 在很多领域有广泛的应用。简单来说就是一个任务直接建模可能有难度,就把任务分解成多个子任务,然后用专家模型分别对子任务建模,最后将每个子任务的结果集成在一起。这对于多语言语音识别任务可以说是天然适配的。下面我们简单介绍一下基于 MoE 的两种方法。
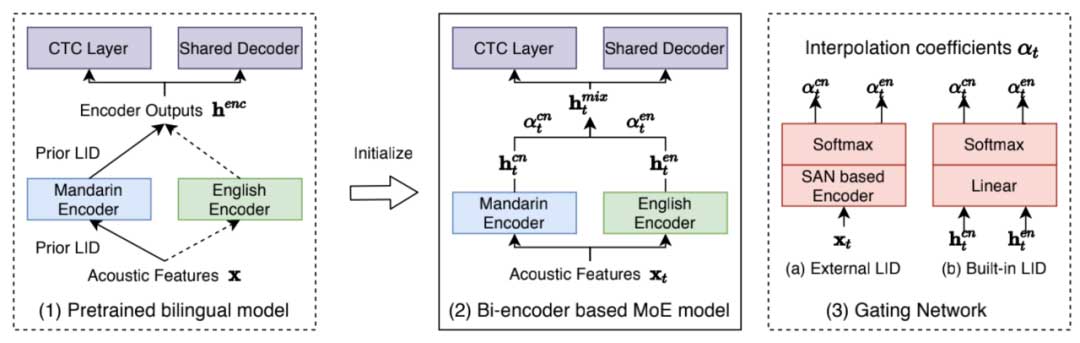
Bi-Encoder
Bi-Encoder[1]方法是针对一个中英混合 ASR 任务,分别用两个独立的编码器对中英文分别建模,然后利用门控网络计算两个编码器输出的插值系数,加权在一起。这个门控网络本质就是一个语种分类器,插值系数就是各个语种的预测概率。在训练的时候为了保证每个解码器往特定的语言空间去学习,需要对他们用各自的单语数据做一个预训练来初始化。
LAE
LAE[2]方法与 Bi-Encoder 相比,主要区别在于:
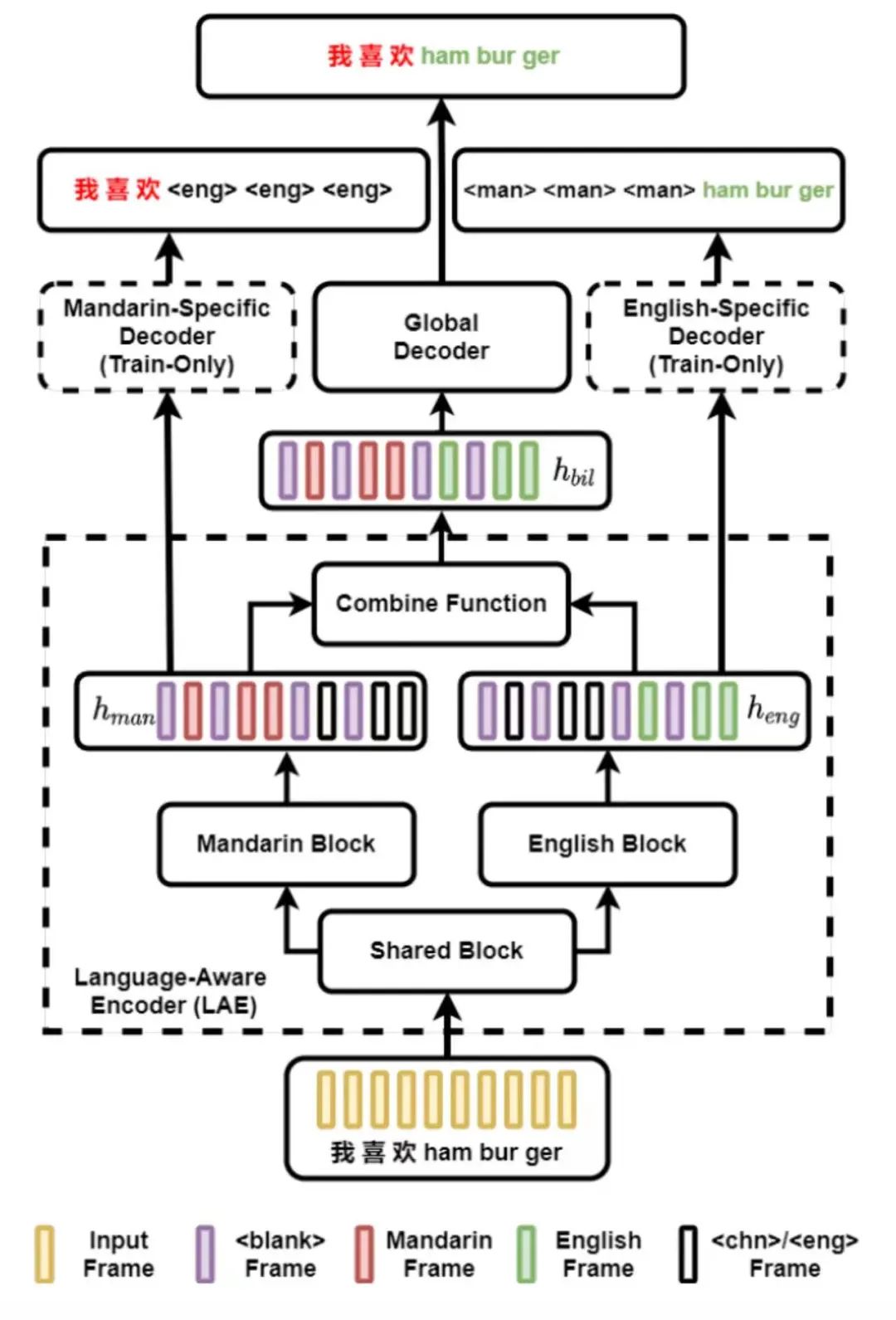
- 考虑了语言在时间维度是不混叠的,融合专家网络输出的方式是直接使用线性求和.
- 引入语言感知训练,也就是在训练时对每个语言专家加上掩蔽非目标语言标签的损失函数,保证每个语言专家只能学到特定语言的语义表征。因此整个过程不需要通过单语预训练来引导。
不过上述方法仍存在以下几个问题:
- 之前的方法需要计算所有特定语言专家模块。然而,实际上一个时间段往往只有一个语言的块是起作用的。这意味着大量的冗余计算开销。并且在向多语言扩展的过程中,支持的语言越多,冗余的计算开销就越多。
- 特定语言专家彼此隔离且缺乏交互。因此 Code-Switch 场景的跨语言上下文信息很容易丢失。
LR-MoE
针对之前工作存在的问题,本文引入基于帧级语种分类(LID)的稀疏路由,提出了一种计算高效的语种路由专家混合模型(LR-MoE)来同时建模单语和语码转换的多语言语音识别任务。
方法介绍
- 模型架构
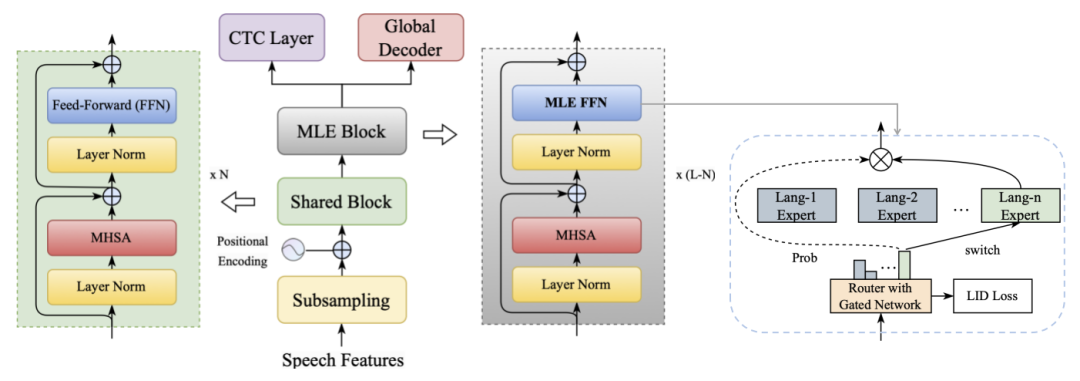
上图是基于 Transfomer 的 LR-MoE 架构。LR-MoE 主要由共享模块和混合专家模块两部分组成。这里,共享模块使用标准的 Transformer 结构,提取语音的通用表征。混合专家模块使用 MLE-FFN 模块替换 Transformer 中的 FFN 模块,以提取特定语言的特征表征;同时保留注意力模块与 MLE 层交互堆叠,以实现跨语言信息的交互。在训练时,基于门控网络的帧级 LID 任务与 ASR 任务联合训练。
- 门控网络
模型中间层的瓶颈特征已经包含了丰富的高维语言信息,故帧级 LID 任务使用一层简单的线性层建模。LID 辅助任务的 token 级标签通过 ASR 标签映射得到(示例如下)。

基于帧级语种路由(FLR)的门控网络使用 CTC Loss,以类似 ASR 的训练方式训练,其损失函数如下:
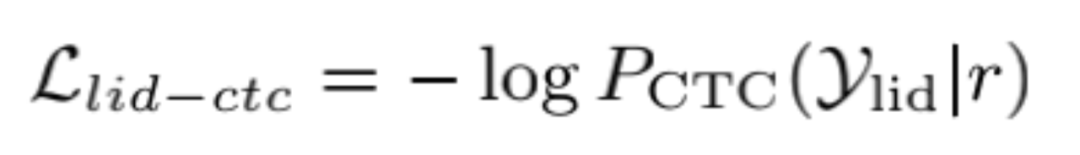
由于 CTC 输出的稀疏尖峰特性,对于 blank 帧使用前向平滑的对齐策略得到稠密的对齐分布。作为对比,本文设计了话语级语言路由(ULR)Loss,对门控网络输出的平均池化做交叉墒得到。最终损失函数为两个任务的加权和:
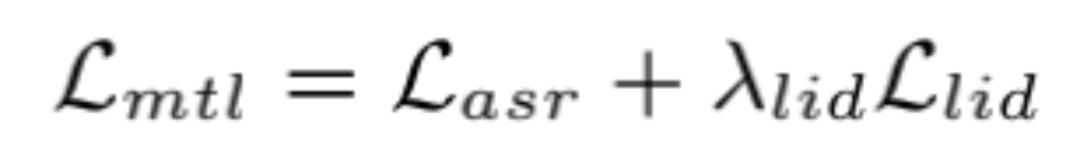
实验
本文主要在两个数据集上展开了实验,一个是基于 ASRU 中英 Code-Switch 挑战赛的双语 ASR 实验,一个是基于中英日韩四种语言以及中英混的多语种 ASR 实验。
实验配置上,我们以标准 Transfomer 结构作为基线模型(Vallina),同时对比了 LR-MoE 和其他基于 MoE 的方法,包括 Bi-Encoder[1]、LAE[2]和 sMoE[3]。
- 中英双语实验结果
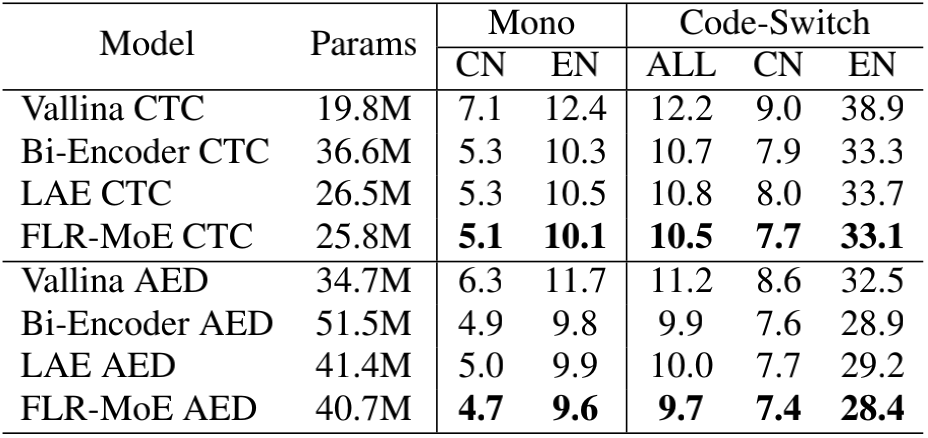
上表展示了基于 CTC 和 AED 的中英 ASR 系统,不同模型架构的性能。相比其他 MoE 方法,基于 LR-MoE 的方法使用更少的模型参数量,取得了更好的识别效果。其相对于基线模型也取得了显著的识别性能改善。
- 多语种实验

上表展示了多语言 ASR 系统各模型架构的结果。与以往 MoE 方法相比,本文提出的方法在两种单语和 Code-Switch 场景都取得了显著的性能改善。对于 FLOPs,该架构随着语言数量的增加,计算复杂度几乎不变,显示了在多语言 ASR 中的可扩展性。相对基线模型,在单语和 CS 评估集的相对平均改进分别达到了 28.4% 和 26.8%。
总结
对于兼顾单语和语码转换的多语言语音识别任务,本文回顾了之前有代表性的工作,并介绍了网易易盾近期提出的一种计算高效的网络架构 LR-MoE。该方法适用于扩展到更多的语言,并且几乎不会带来额外的计算开销。在中英和多语言 ASR 实验上,相对之前的一系列方法,LR-MoE 无论是在计算开销还是识别效果上都显示了优势。未来网易易盾也将继续在多语言语音识别领域做进一步的探索,助力智能语音内容安全风控。
参考文献
[1] Y. Lu, M. Huang, H. Li, J. Guo, and Y. Qian, “Bi-encoder transformer network for mandarin-english code-switching speech recognition using mixture of experts,” in Interspeech, 2020.
[2] J. Tian, J. Yu, C. Zhang, Y. Zou, and D. Yu, “LAE: Language-Aware Encoder for Monolingual and Multilingual ASR,” in Proc. Interspeech 2022, 2022, pp. 3178–3182.
[3] W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
