
混响问题描述
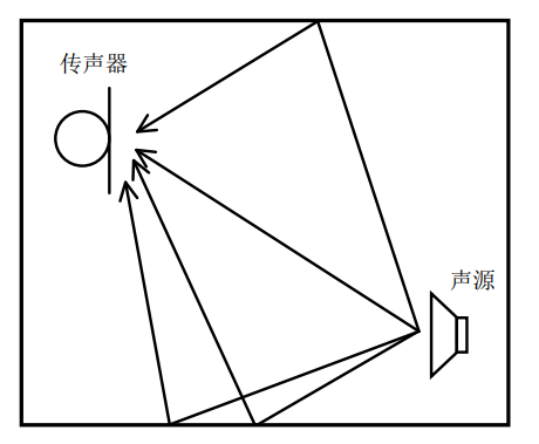
在封闭的空间中,当声源产生的声音经过反射物(墙壁、地面和室内装饰物等)多次反射叠加后会形成混响,如图1所示。在均匀介质声场中,声源到传声器的直达声传播时间最短,人们将在直达声之后 50-100 ms内被传声器接收到的反射声定义为早期混响,在直达声50-100 ms之后被传声器接收到的反射声定义为晚期混响。早期反射声虽然会降低传声器拾取的语音信号质量,但是可以提高语音信号的可懂度[1,2],而晚期混响会模糊和混淆语音信号中的音节,降低语音信号的质量和可懂度。通常采用混响时间(Reverberation Time,T 60)用于衡量房间混响程度。T60指是对放置房间中的宽带声源进行激励并关闭声源,待信号能量衰减 60 dB 时所需的时间,可以由赛宾公式计算得到:
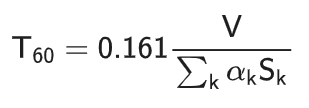
其中,V表示房间体积(单位为 m3 , Sk 表示房间内第k个吸声材料的表面积 (单位为m²), αk 表示房间内第k个吸声材料的吸收系数。
基于房间系统的线性时不变假设,混响语音在时域上可以表示为纯净声源信号与房间脉冲响应的卷积输出:
y(t)=c(t)*s(t)
其中,*表示卷积操作,y(t)为传声器拾取信号,c(t)为声源到传声器的房间脉冲响应,s(t)为纯净的信号。
去混响算法
传统上,对房间脉冲响应进行逆滤波是一种主流的去混响算法,其中以加权预测误差(Weighted Prediction Error,WPE)算法[3]及其改进方法[4,5]为代表。WPE算法假设混响成分可以被线性预测,且期望信号(直达声和早期反射声)在每个时频点上服从均值为零方差为λ的复高斯模型分布:
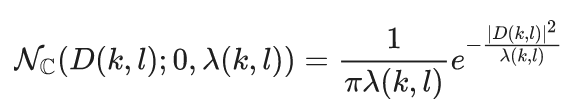
通过最大化模型负对数的似然函数,并利用交替迭代的方式更新方差𝜆和滤波器系数的估计值便可得到期望信号的估计。
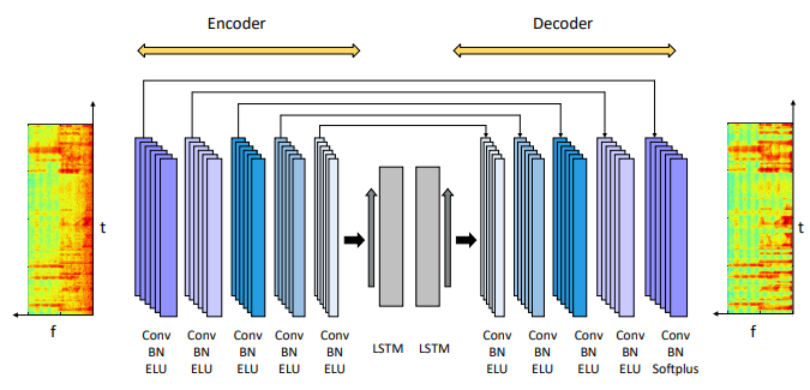
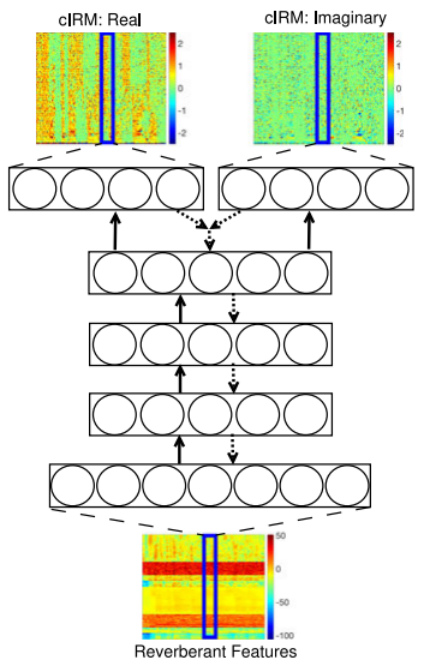
近年来,受到深度神经网络(Deep Neural Networks,DNNs)发展的影响,监督型语音增强开始受到学者的广泛关注和研究。在降噪任务中,通过提供监督性的目标,让DNN学习从带噪语音特征到纯净目标间的非线性映射关系,能够有效地抑制平稳与非平稳噪声。按照输出目标的不同,DNN语音增强算法可以分为基于掩蔽函数(masking-based)的方法和基于谱映的方法。对于前者而言,主要借鉴了计算听觉场景分析(Computational Auditory Scene Analysis,CASA)中声学掩蔽机制,让DNN模型学习听觉滤波器,从而抑制噪声成分。对于后者来说,DNN模型被用来学习谱系数,从而重构出纯净的语音谱。如图2所示是一种典型的端到端谱网络——卷积循环网络(CRN),网络的输入是带噪语谱图,输出是估计的纯净语谱图。受降噪任务的启发,一些用于降噪的DNN方法被用于去混响任务中[6–9]。这些方法使用DNN直接增强信号或者估计掩蔽间接得到纯净语音,与降噪任务的唯一区别是,这些方法的DNN输入信号是带混响信号。如Williamson等[7]提出利用深度神经网络从带噪带混响的语谱中学习复值理想比值掩蔽(Complex Ideal Ratio Mask,cIRM):
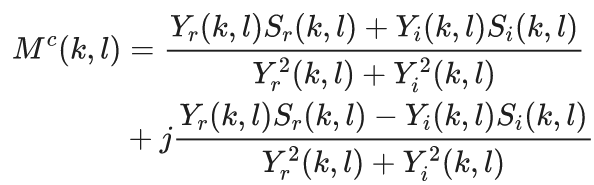
其中,Yr、Yi 和 S𝑟、S𝑖 分别是输入信号和纯净信号复数谱的实数部分和虚数部分。将估计得到的cIRM作用于输入信号,便可得到估计的纯净信号。
此外,一些传统算法和 DNN 结合的方法也被提出。如Taniguchi等[11]先利用复值广义高斯(complex-valued generalized Gaussian,CGG)模型代替了复高斯模型对信号进行建模:
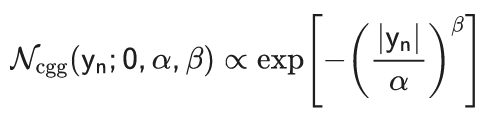
之后作者再利用神经网络对 CGG 模型的α和β等参数进行估计,进而得到混响成分的估计。
混响的应用
此外,混响在许多不同的领域和应用中都有重要的作用。以下是一些混响应用的示例:
音频录音和音乐制作:在录音室中,混响是一个关键的声学效果,可以用来模拟不同的环境,如大教堂、演唱会厅或小型演出场所。通过控制混响的强度和持续时间,音频工程师可以为音乐或声音效果添加特定的空间感。
电影和电视制作:混响也在电影和电视制作中被广泛使用,用来增强场景的真实感。例如,在电影中,通过添加合适的混响可以使观众感受到不同环境中角色的存在,如室内、户外或幽闭空间。
语音增强和通信:在通信系统中,混响可以用来模拟不同的通话环境,从而提高通话的真实感。
音响设计和建筑:在音响设计中,混响是一个重要的考虑因素,可以影响声音在空间中的传播和反射方式。在建筑设计中,混响可以用来改善室内声学,确保声音在建筑内部的分布和质量得到最佳控制。
虚拟现实和游戏开发:在虚拟现实和游戏开发中,混响可以用来增强用户的沉浸感。通过模拟不同的环境声学,如洞穴、森林或城市街道,开发者可以为用户创造更加逼真的体验。
参考文献:
[1]KUTTRUFF H. Room acoustics[M]. Crc Press, 2016.
[2]BRADLEY J S, SATO H, PICARD M. On the importance of early reflections for speech in rooms[J]. The Journal of the Acoustical Society of America, 2003, 113(6): 3233-3244.
[3]NAKATANI T, YOSHIOKA T, KINOSHITA K, 等. Blind speech dereverberation with multi-channel linear prediction based on short time Fourier transform representation[C]//2008 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2008: 85-88.
[4]YOSHIOKA T, NAKATANI T. Generalization of multi-channel linear prediction methods for blind MIMO impulse response shortening[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(10): 2707-2720.
[5]NAKATANI T, YOSHIOKA T, KINOSHITA K, 等. Speech dereverberation based on variance-normalized delayed linear prediction[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2010, 18(7): 1717-1731.
[6]WENINGER F, WATANABE S, TACHIOKA Y, 等. Deep recurrent de-noising auto-encoder and blind de-reverberation for reverberated speech recognition[C]//2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2014: 4623-4627.
[7]WILLIAMSON D S, WANG D. Time-frequency masking in the complex domain for speech dereverberation and denoising[J]. IEEE/ACM transactions on audio, speech, and language processing, 2017, 25(7): 1492-1501.
[8]ZHAO Y, WANG D, XU B, 等. Late Reverberation Suppression Using Recurrent Neural Networks with Long Short-Term Memory[C/OL]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2018: 5434-5438. DOI:10.1109/ICASSP.2018.8462275.
[9]ZHAO Y, WANG D, XU B, 等. Monaural Speech Dereverberation Using Temporal Convolutional Networks With Self Attention[J/OL]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, 28: 1598-1607. DOI:10.1109/TASLP.2020.2995273.
[10]TAN K, WANG D. A convolutional recurrent neural network for real-time speech enhancement.[C]//Interspeech: 卷 2018. 2018: 3229-3233.
[11]TANIGUCHI T, SUBRAMANIAN A S, WANG X, 等. Generalized weighted-prediction-error dereverberation with varying source priors for reverberant speech recognition[C]//2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA). IEEE, 2019: 293-297.
作者:王涛兵
来源:21dB声学人
原文:https://mp.weixin.qq.com/s/2mFs5Tdhs8c8stBVo6J7-Q
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
