
该工作由上海交通大学宋利教授带领的Medialab实验室与悉尼科技大学合作产出,并于近期被ICCV 2023所接收。该工作实现了对人脸图像的身份隐私保护,旨在隐藏面部的真实身份,同时保留其他与身份无关的面部特征。现有的主流的目标通用型(target-generic)人脸图像匿名化方法通常会在潜在空间中将身份特征解纠缠,然后设计混淆方法保护身份特征,最后在一个端到端的网络中通过对抗性的训练来使隐私和实用性达到平衡。然而,这种模式的方法往往导致算法设计人员需要在身份保护结果的隐私性和实用性之间进行很煎熬的权衡。此外,至今尚无很好解释的深度网络潜在空间更是让这些方法的决策显得很不透明,所以这些方法都缺乏对它们在潜在空间进行身份保护的过程的解释能力。为了解决这些问题,我们提出了一种基于神经辐射场和生成性先验的人脸图像身份隐私保护方法,并将其命名为 IDeudemon。
IDeudemon方法采用“分而治之”的策略来逐步地保护身份和保留实用性,可以生成隐私保护程度可调节的高视觉质量的匿名化图像,很好地保持与原图相似的非身份特征的同时,整个方法具有较好的可解释性。得益于强大的 3D 先验和精心调整的生成性设计,IDeudemon可以自然地保护人脸的身份,产生高质量的面部细节并且对不同的姿势和表情具有鲁棒性。大量定性和定量的实验表明,我们所提出的IDeudemon优于以前的SOTA人脸图像去身份(De-identification)方法。
来源:ICCV 2023
论文标题:Divide and Conquer: a Two-Step Method for High Quality Face De-identification with Model Explainability
作者:Yunqian Wen, Bo Liu, Jingyi Cao, Rong Xie and Li Song
内容整理:温云倩
研究背景与总体介绍
海量的人脸图像每天被上传到各种社交网络和共享平台。尽管包含大量的个人信息,这些图像的传播和获取却难以得到有效监管。因此随着计算机视觉技术特别是图像理解应用的快速发展,人们对个人隐私泄露的担忧愈演愈烈。人脸图像身份隐私保护是一个旨在从面部图像中删除人的所有身份识别的信息,同时保留尽可能多的其他与身份无关的信息的过程。理想情况下,身份信息被保护的同时,其他与身份无关的人脸特征并不会被影响,比如表情,姿态和背景。身份保护后的图像仍然保持与原图较高的视觉相似度和与原图可比的视觉质量,并可被用于与身份无关的任务,比如人脸检测,表情分析,姿势识别等。因此,研究者们付出了巨大的努力来获得有效的隐私性-实用性权衡。人脸身份隐私保护可以让个人放心地分享个人肖像,同时消除一些实体和机构发布面部数据时的道德和法律约束。
我们提出的解决方案 IDeudemon 使用了“分而治之”的策略,通过两个连续的步骤分别实现身份隐私保护和图像实用性保存。在第一步中,我们使用一个3D参数化建模方法来估计面部的几何形状并混淆人脸的3D身份表示以隐藏真实的身份。在第二步中,我们专注于以第一步中得到的既不自然也不逼真拟合人脸为基础,生成具有高质量细节的身份与拟合人脸保持一致的面部图像。我们首先设计了视觉相似性辅助,通过使用人脸解析图(face parsing map)来保留与身份弱相关和不相关的软生物特征,以尽可能保持与原始人脸图像的视觉相似性。然后,我们训练通过基于生成性面部先验的GAN来恢复具有真实细节的匿名化人脸。最后,我们可以获得高质量的视觉愉悦的身份保护的结果。
值得注意的是,通过利用已有3D人脸模型研究的大量积累,我们的解决方案在确保了有效的人脸身份保护的同时,具有良好的模型可解释性。模型可解释能力注重该模型的主动行为,这些行为包括模型执行的可提供对该模型内部操作的洞察的操作或程序。以前的人脸身份保护工作依赖于潜在空间人脸特征的解纠缠,其复杂性缺乏清晰度。相比之下,IDeudemon的面部表示是从3D扫描和统计数学面部模型中获得的,该方法在第一步中精确地混淆了身份码。综上所述,IDeudemon在确保身份隐私被保护的同时,具有更强的可解释性。
总体而言,与已有的方法相比,我们的人脸图像身份保护方法具有几个突出的优点:(1)我们的身份保护过程具有较好的可解释性,即我们的人脸身份是基于与面部几何结构相关的成熟的3D先验建模的,是数学统计下可被用于代表身份的参数; 也因此混淆可以准确且直接地添加在身份表示上,为图像保持与原图可比拟的实用性打下了坚实的基础。(2)消除了在一个网络中平衡隐私性和实用性的难题。(3)能与原图保持更一致的姿势和表情。(4)身份保护的结果具有照片级逼真的细节,可实现百万像素的面部身份保护。

研究现状与动机分析
我们调研了现有的人脸视频身份保护技术。我们发现早期的人脸身份隐私保护方法对检测到的人脸区域进行各种混淆操作,比如模糊、遮盖、像素化等。尽管方式简单且处理迅速,它们严重损害了图像的观赏价值,且在面对先进的深度身份验证技术时并不可靠。k-same族方法曾煊赫一时,但因为有生成质量不佳和对使用场景要求很严格的两大缺陷而不适用于真实的人脸数据集,已经逐渐淹没在历史长河。目前主要有两大类方法。一种使用对抗性噪声来生成身份保护的面孔,这些人脸在视觉上与原始人脸几乎无法区分。然而,这类方法高度依赖对所针对的目标身份识别系统的可访问性,因此往往泛化能力不好。另一大类方法倾向于训练DGN在潜在空间解纠缠、操纵并保护身份表示,进而最终保护身份。这些方法通过在一个网络中进行对抗性的训练,以努力在隐私性和实用性之间取得平衡。因此,这些方法往往陷入牺牲一方和寻求折衷的纠结中。
此外,这些方法的效果在很大程度上取决于网络在隐空间的面部解纠缠能力,但是到目前为止对神经网络隐空间依然没有清晰的解释。因此,我们认为有必要将人脸身份保护任务从上述煎熬的隐私性-实用性平衡的寻找中解救出来,并为面部身份提供可靠且可解释的保护。此外,现有人脸身份保护方法多被设计于受限场景,故而大都只适用于具有中性表情的正面面部图像,无法很好地处理多样的姿势和表情,这也需要改进。
与以前的工作不同,我们的目标是使人脸身份保护研究摆脱这种传统的在一个网络内寻找隐私性和实用性之间的平衡,取而代之提供一种可靠且具有良好可解释能力的保护个人身份的方法。我们设计新方法的灵感来自于观察到佩戴人皮面具可以有效地改变一个人的身份这一事实。这种情况明确地表明,令人信服的身份隐私保护应当是对面部五官(即眼睛、鼻子、耳朵、嘴巴)和面部骨骼的整体性几何形状进行实质性改变。由于这类转变几乎不可能通过单纯的化妆甚至是外科手术来实现——这超出了人体的物理极限,因此意味着身份的变化。相比之下,发型、发色、配饰和肤色等与身份弱相关和不相关的软生物特征可以被造型师和化妆师轻松地更改;然而,这些特征却显著地影响人眼对两张面孔之间视觉相似性的感知。因此,我们认为保护身份隐私和保留图像实用性可以被分成两个不同的目标,需要设计不同的策略。通过将人脸图像身份保护的大目标分解成两个小目标,我们可以独立地专注于每个目标以获得更好的结果。
提出的IDeudemon方法
给定一张没有任何保护的输入人脸图像X,人脸身份隐私保护的目标是生成一张隐藏真实身份的图像X’,具有照片级别的真实感。身份保护的人脸 X’ 在视觉上与原始图像X非常相似,但在与X一起比较时,面部识别工具会将这两张图像判断为是不同身份的人。
图2显示了本文提出的 IDeudemon 的整体架构。IDeudemon 在分开的两个步骤中依次地保护隐私和保证实用性,避免了一个网络中胶着的平衡。在第一步中,我们实行了参数化身份保护。我们首先使用一个 3DMM 模型对输入图像 X 的 3D 参数做初始化。然后我们利用训练好的基于 NeRF 的模型计算 X 的精确的 3D 参数并得到输入人脸的真实拟合结果 Xf。通过在真实身份码上添加经由大量实验统计的适宜的保护性扰动后,上述基于NeRF的模型生成身份保护的拟合结果 Xp。尽管具有高保真度,但拟合的输出 Xf 和 Xp 只是X的近似结果,丝毫不像真实的人脸,且不具有视觉上的愉悦性。因此,我们设计了第二步,以恢复与原始图像可比拟的实用性。在第二步中,我们首先设计了视觉相似性辅助,通过使用人脸解析图直接地保留 X 中与身份不相关和弱相关的区域,即背景、头发、配饰、颈部和部分身体。然后,我们设计了符合任务的损失函数,并训练了基于生成性先验的 GAN 模型。以第一步中身份保护的拟合人脸再加上视觉相似性辅助中保留的身份无关的和身份弱相关的区域的混合图像为基础,训练好的 GAN 能够恢复逼真的细节并输出高质量的身份保护的人脸 X’。下面,我们将详细讨论这两个步骤。
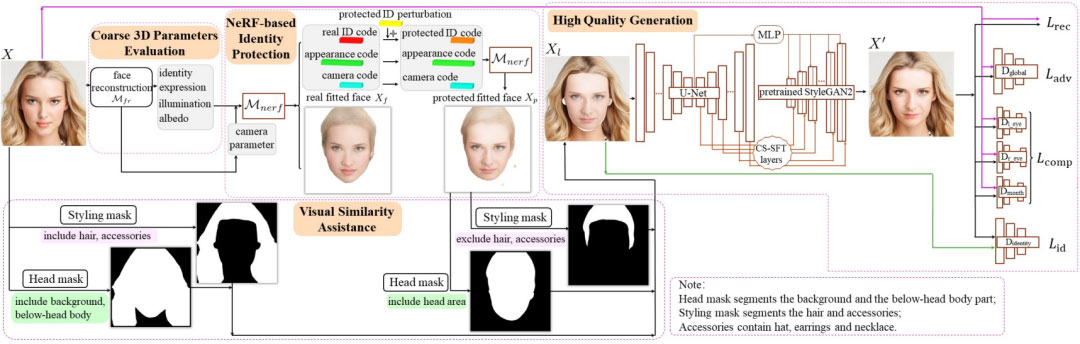
步骤I:参数化的身份保护
参数化的身份保护包含两个子步骤,分别是粗略的3D参数估计和基于 NeRF 的身份保护。我们将在下面分别对两者进行详细的介绍。
粗略的3D参数估计
3DMM模型拟合是 3D 人脸重建的众多方式中的一种,可以从 2D 人脸图像中估计出身份、姿态、光照和反照率相关的参数。为了给基于NeRF的模型的实时拟合提供良好的基础,我们首先使用已有的 3DMM 模型[1],记为 Mfr,来粗略地估计输入人脸图像 X 的 3D 参数以做初始化。该过程可被表示为:
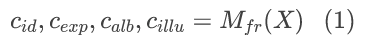
其中c*代表粗略的人脸 3DMM 参数,包含四个解纠缠的面部因子:人脸X的身份 cid,表情 cexp和反照率 calb,以及整张图像场景的光照 cillu 。这些3D参数是通过求解一个基于 3DMM 模型[1]的逆向渲染优化来获得的,作为下一子步的3D参数的初始化。
虽然初始化的3D身份参数只描述了面部区域的粗略的几何形状(不包含头发,牙齿,内嘴部分等),但该参数会通过下一子步中描述的基于NeRF模型进行自适应调整并变得很准确。
基于NeRF的身份保护
有了初始化的面部 3DMM 参数 c*,我们使用预训练的参数化的基于 NeRF 的模型(被表示为 Mnerf)获得原始图像 X 的准确的 3D 参数和拟合的人脸 Xf,该过程被表示如下:
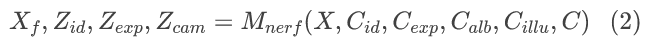
其中 Xf 是拟合的图像。C是用于渲染的相机参数(详细计算方法可见于文献[2])。Z*表示为人脸图像 X 计算的 3D 码,其各因子的维数与前一子步中相应的粗略的 3D 参数的维数相同。特别地,由于本文的身份保护任务希望将身份特征与所有其他面部特征区分开,所以这里我们用 Zid单独表示身份,并将其命名为身份码。然后我们让外观代码 Zapp不仅包含X中人脸的表情和反照率,还包含整个场景的光照。此外,由于来自NeRF的密度场可以隐式地编码场景的 3D 几何形状,我们还可以通过这次拟合过程获得人脸图像X的相机码 Zcam,它可以反映 X 中人脸的姿态。

由于身份保护过程中使用的参数化的基于 NeRF 的模型以 3DMM 模型为参考,即 IDeudemon 的身份表示是在大量人脸扫描中统计建模得到的(而非现有方法中常用的特征空间特征向量),噪声被添加在其上以实现混淆,因此本文的身份保护过程逻辑清楚且具有良好的可解释性。此外,由于扰动是直接添加到解纠缠的身份码上而没有影响其他的 3D 面部参数,因此具有可靠的身份更改的匿名化结果仍然很好地保留了与身份无关的特征,即表情、反照率、光照和姿势。
步骤Ⅱ:实用性保存
尽管参数化的基于NeRF的模型的身份保护的拟合结果 Xp 已经很好地混淆了真实的身份,但 Xp 在具有真实感的外观方面存在缺陷。为了生成视觉上令人愉悦的高质量匿名化人脸,我们设计了负责实用性保存的第二步。第二步中包含视觉相似性辅助和高质量生成两个子步骤,我们将在下面分别进行具体的介绍。
视觉相似性辅助
如前所述,头发、配饰(包括帽子,耳环和项链)、脖颈和背景等都属于与身份不相关或弱相关的软生物特征,但却可能占据相当大的空间,并极大地影响人们对两张人脸之间视觉相似度的感知和后续使用。因此,我们首先使用人脸解析图分别为 X 和 Xp 生成一个头部掩码和一个造型掩码。其中头部掩码分割出背景和头部下的身体部分,造型掩码分割出头发和配饰部分。然后我们将原始图像X中的头发、配饰、背景和头部下的身体部分与受保护的拟合图像 Xp 中除去头发和配饰之外的分割的面部结合起来,获得了混合质量的人脸图像Xl。Xl具有匿名化的身份并保留了大片的与身份无关和弱相关的区域。如图2所示,Xl 具有高质量的逼真的身份无关/弱相关的特征、低质量的面部区域和一些不规则的白色间隙,其图像质量仍然需要改进。
从混合质量的图像 Xl 到所需的高质量身份保护的照片级逼真度的 X’ 的转换其实是一项人脸修复任务,即将部分区域退化的人脸图像转换为整体具有清晰可辨的细节的逼真图像。显而易见这两个图像域之间的域差距非常大,因此这项任务颇具挑战性。幸运的是近年来关于盲脸修复的研究突飞猛进,我们在这里采用了强大的开源 GAN 模型[3],通过利用封装在预训练的大型人脸生成模型 StyleGAN2 中的丰富多样的先验信息来实现高质量的身份保护的人脸生成。
我们使用三元组图像 X、Xl 和 X’ 训练高质量生成子步骤中的GAN模型。我们继承文献[3]中使用的损失函数,并根据本文的身份保护任务的特殊要求对与身份相关的损失函数进行了调整。具体而言,总损失函数包含了下面的四项。
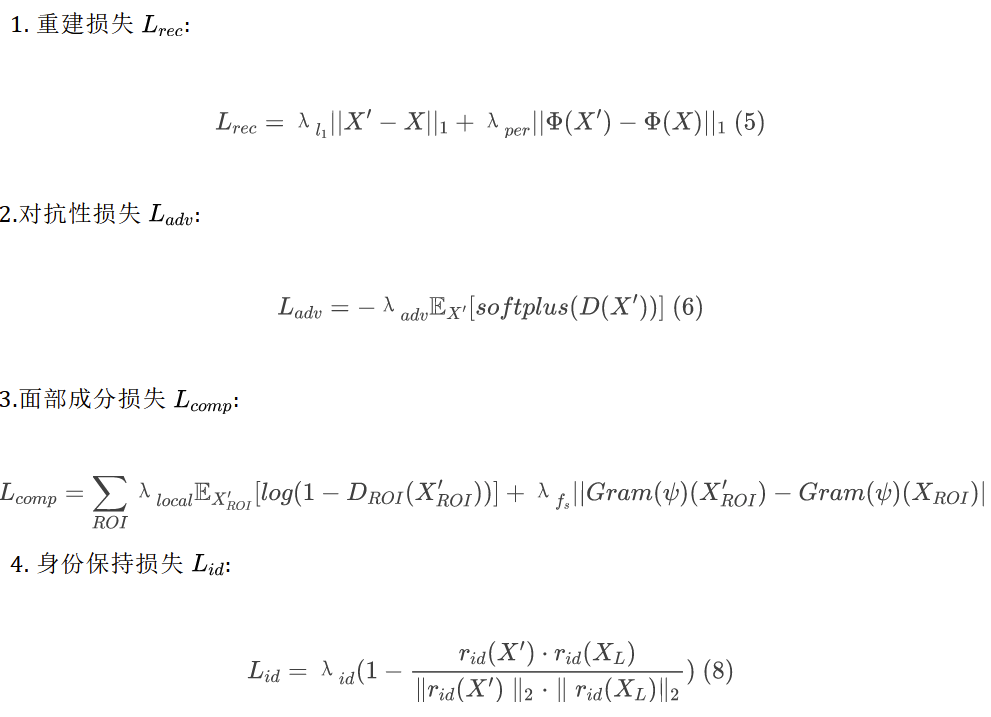
总损失函数:
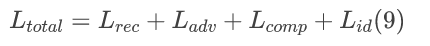
实验分析
我们选择 FFHQ 数据集以训练阶段Ⅱ中高质量生成子步中的 GAN 模型。此外,为了公平地与其他方法进行比较,我们还在 CelebA–HQ 数据集上测试了所提出的 IDeudemon 方法,公平比较的同时展示了 IDeudemon 的良好的泛化能力。所有方法的性能通过隐私指标(身份距离ID_DIS)和实用性指标(PSNR、SSIM、FID、姿势距离POSE和表情距离EXP)进行评估。
具体实验结果
保护性扰动分析我们首先分析 IDeudemon 采取不同级别的扰动时的性能,更具体地说,就是在步骤I中基于 NeRF 的身份保护子步骤里对原始身份码应用不同程度的扰动时 IDeudemon 的性能。这里的加性高斯噪声 n 是从正态分布中采样,参数loc设置为0,参数 scale 属于[0.05, 0.10, 0.15, 0.20, 0.25, 0.30, 0.35, 0.40]。n 的维度与人脸3D身份码 Zid 一致。在每个 scale 值下,我们对每张测试人脸图像生成十张身份保护的人脸图像,然后在每个 scale 值处计算各个评价指标的统计平均结果。


图3显示了定性结果。可以观察到,随着噪声的scale的增加,即噪声量的增加,身份保护的人脸和原始人脸之间的几何差异明显扩大,而大部分与身份无关和弱相关的软生物特征(发型、背景、姿态、表情等)仍然保持不变。值得注意的是IDeudemon匿名化的图像的质量一直很好,几乎可以与原始图像的质量相媲美,且非常逼真。所有生成的图像都有很清晰的细节,例如睫毛、皱纹、牙齿和嘴唇。定量结果如图4所示。可以看到,身份保护的程度是可以调整的,伴随着实用性的变化。值得注意的是,实用性表现保持在良好的水平(例如,FID值始终很低)。特别地,我们注意到当噪声scale小于0.2时,去身份的结果与原始人脸视觉上过于相似并且隐私性指标不够好,保护身份的能力不强;而当噪声的scale值大于0.3时,面部的几何结构开始变得有些夸张(例如夸张的眼睛、鼻子、皱纹和阴影)。
与SOTA方法的比较

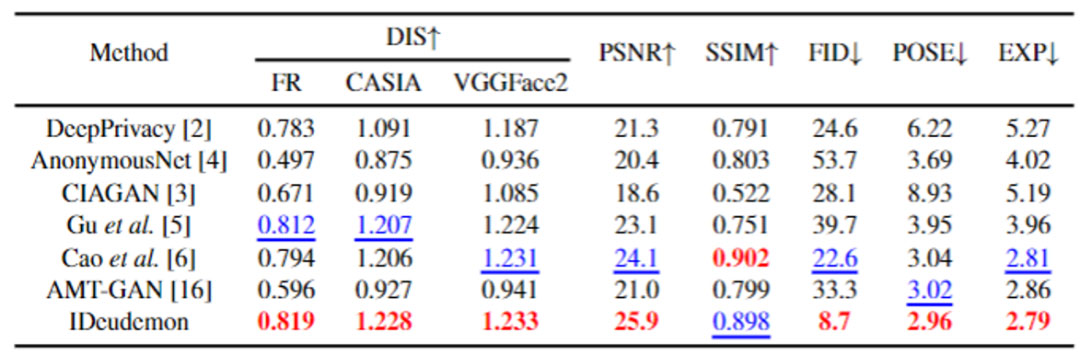
为了验证本文提出的IDeudemon的有效性,我们将其与以下六种SOTA身份保护方法进行了比较:DeepPrivacy [4],AnonymousNet [5],CIAGAN [6],Gu等人 [7],Cao等人 [8]和AMT-GAN [9]。为了公平起见,本节实验的测试数据集是CelebA–HQ数据集,且其中所有人脸图像都对齐并裁剪为256×256的大小。
定性结果如图5中所示。可以看到,对比方法无法生成照片级逼真的人脸,尤其是当原始人脸具有较大的姿势(最后两行)或表情(第二行)时。相比之下,我们的IDeudemon方法以一种感知自然的方式混淆了人脸的真实身份,与此同时,被匿名化的人脸仍然具有与原人脸相似的外观,以及与原始人脸几乎相同的姿势、表情、光照和背景。值得注意的是,IDeudemon的匿名化结果保真度很高,可以保留清晰的嘴唇、牙齿甚至睫毛,这优于其他方法。此外,图1中成对展示的IDeudemon的一些身份保护的结果也能很好地佐证这里得到的结论。
定量结果被展示于表1。我们的方法在所有的隐私性指标上均获得了最好的分数,这清楚地证实了我们最初的动机,即操纵3D人脸参数身份码可以极大地有利于身份隐私保护。可以看出本文的IDeudemon实现了与其他对比方法相当的 PSNR 和 SSIM 指标,且在更好的图像感知质量衡量标准 FID 指标上取得了明显更优秀的结果。此外,我们的IDeudemon方法在保留原始人脸的姿势和表情方面也优于其他方法。这些结果都验证了我们在步骤Ⅱ中的设计在确保实用性方面的有效性,这些设计使IDeudemon对匿名化的图像的后续正常使用影响最小。
模型分析与消融实验

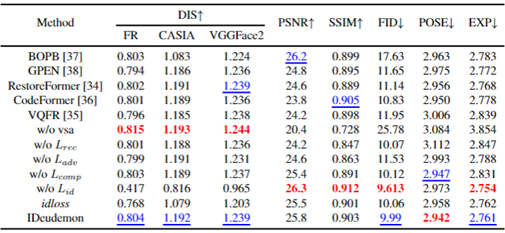
为了验证 IDeudemon 在步骤Ⅱ中各种设计的有效性和必要性,在本小节中,我们通过介绍IDeudemon的一些变体并比较它们的性能来进行消融实验。我们首先挑选并训练五个 SOTA 人脸恢复模型,分别替换高质量生成中的GAN模型[3],并作为IDeudemon的五个变体。此外,还有一个变体,用w/o vsa表示,指的是没有视觉相似辅助子步骤的IDeudemon模型。我们还分析了每项损失函数存在的必要性,以及我们对身份保持损失的修改的必要性。定性和定量实验分别于图6 和表2 中展示。
总结
总结来说,在本文中,我们提出了一种新颖的两步骤的人脸图像身份隐私保护方法 IDeudemon,该方法采用“分而治之”策略在分开的两步中顺次地完成混淆真实身份和保持图像实用性,以此来解决具有挑战性的隐私性-实用性权衡问题。在第一步中,通过引入先进的 3D 参数化面部拟合和混淆解解纠缠的 3D 人脸身份码,我们隐藏了真实身份并赋予整个模型良好的可解释性。此外,3DMM 模型良好的解纠缠的面部表示让我们在改变身份的同时,能够保持其他与身份无关的3D面部特征不变,为第二步恢复图像实用性打下了良好的基础。
在第二步中,视觉相似性辅助子步骤利用人脸解析图将原人脸图像中与身份无关和弱相关的软生物特征直接保存,然后基于生成性先验的GAN模型可以前面提升混合质量人脸的逼真度,最终生成照片般逼真的身份保护的人脸图像。IDeudemon能够在保持良好图像效用的同时通过控制所添加的噪声的参数来调整身份保护的级别。大量实验证明了IDeudemon在人脸身份保护方面的卓越能力(特别是保持原图姿态和表情的能力),显著地优于现有技术。
参考文献
[1] GUO Y, CAI L, ZHANG J. 3D face from X: Learning face shape from diverse sources[J]. IEEE Transactions on Image Processing, 2021, 30: 3815-3827.
[2] HONG Y, PENG B, XIAO H, et al. Headnerf: A real-time nerf-based parametric head model[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 20374-20384.
[3] WANG X, LI Y, ZHANG H, et al. Towards real-world blind face restoration with generative facial prior[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 9168-9178.
[4] HUKKELÅS H, MESTER R, LINDSETH F. Deepprivacy: A generative adversarial network for face anonymization[C]//International Symposium on Visual Computing. 2019: 565-57
[5] LI T, LIN L. Anonymousnet: Natural face de-identification with measurable privacy [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. 201
[6] MAXIMOV M, ELEZI I, LEAL-TAIXÉ L. CIAGAN: Conditional Identity Anonymization Generative Adversarial Networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 5447-5456
[7] GU X, LUO W, RYOO M S, et al. Password-conditioned anonymization and deanonymization with face identity transformers[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIII 16. 2020: 727-743.
[8] CAO J, LIU B, WEN Y, et al. Personalized and invertible face de-identification by disentangled identity information manipulation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 3334-3342.
[9] HU S, LIU X, ZHANG Y, et al. Protecting facial privacy: generating adversarial identity masks via style-robust makeup transfer[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 15014-15023.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
