
最近一段时间做了点和说话人日志(speaker diarization)相关的工作,所以在这里对说话人日志做一个简单的整理。说话人日志也叫说话人分离,是从一个连续的多人说话的语音中切分出不同说话人的片段,并且判断出哪个片段是哪个说话人的过程。它主要解决是两个方面的问题:
- 谁在说话。
- 在什么时候说话。
针对于问题1,通常使用说话人识别方法来解决。而对于问题2,可以通过说话人分割和说话人聚类来解决。现有的说话人日志框架大致分为两种,一种是基于分割-声纹-聚类的分步联合框架,另外一类是端到端的解决方案。在本文中主要聚焦于分割-声纹-聚类的处理框架,其大致的框架流程图如下所示。

基本模块介绍
语音活性检测
语音活性检测模块主要用于去除静音段,以静音段作为分割点,将语音切分成不同的片段。在不同的说话人语音间的间隔较大的情况下,语音活性检测可以将不同的说话人语音分割开来。每个片段只包含一个说话人语音,但是在很多情况下,同一个片段会包含不同的说话人,因此需要对这类片段做进一步的处理。使用特定窗长和窗移对片段进行加窗处理来达到对该片段进一步切分的目的,然后再从每个窗内提取相应的说话人特征。而实现一个语音活性检测方式有很多,可以自己训练一个二分类网络,也可以使用开源的语音活性检测模型,比如webrtc中的vad,以及nvidia的marblenet。本文中使用的是modelscope中开源vad模型–fsmn-vad。有关该方法的介绍以及相应的后处理策略会在后续文章中介绍。本文中直接使用fsmn-vad的离线模式得到相应的语音时间戳。
def get_vad_result(audio_path='./sd_test.wav'):
vad = fsmn_vad.FSMNVad()
#vad = fsmn_vad.FSMNVadOnline()
segments = vad.segments_offline(audio_path)
vad_result = ""
utt = audio_path.split('/')[-1][:-4]
for item in segments:
vad_result += "{}-{:08d}-{:08d} {} {:.3f} {:.3f}\n".format(utt, int(item[0]), int(item[1]), utt, int(item[0]) / 1000, int(item[1]) / 1000)
return vad_result说话人特征提取
说话人特征提取部分主要利用说话人识别网络,现有的说话人识别网络有很多种,比如x-vector, d-vector等,经典的如ECAPA-TDNN, ResNet等等。本文采取阿里提出的CAMPPLUS网络结构,一个能够同时提取局部特征和全局特征用作说话人识别embedding。无论是计算复杂度还是识别效果,在现有的一些开源数据集上(CN-Celeb,VoxCeleb)都算是不错的。其网络架构图如下所示:
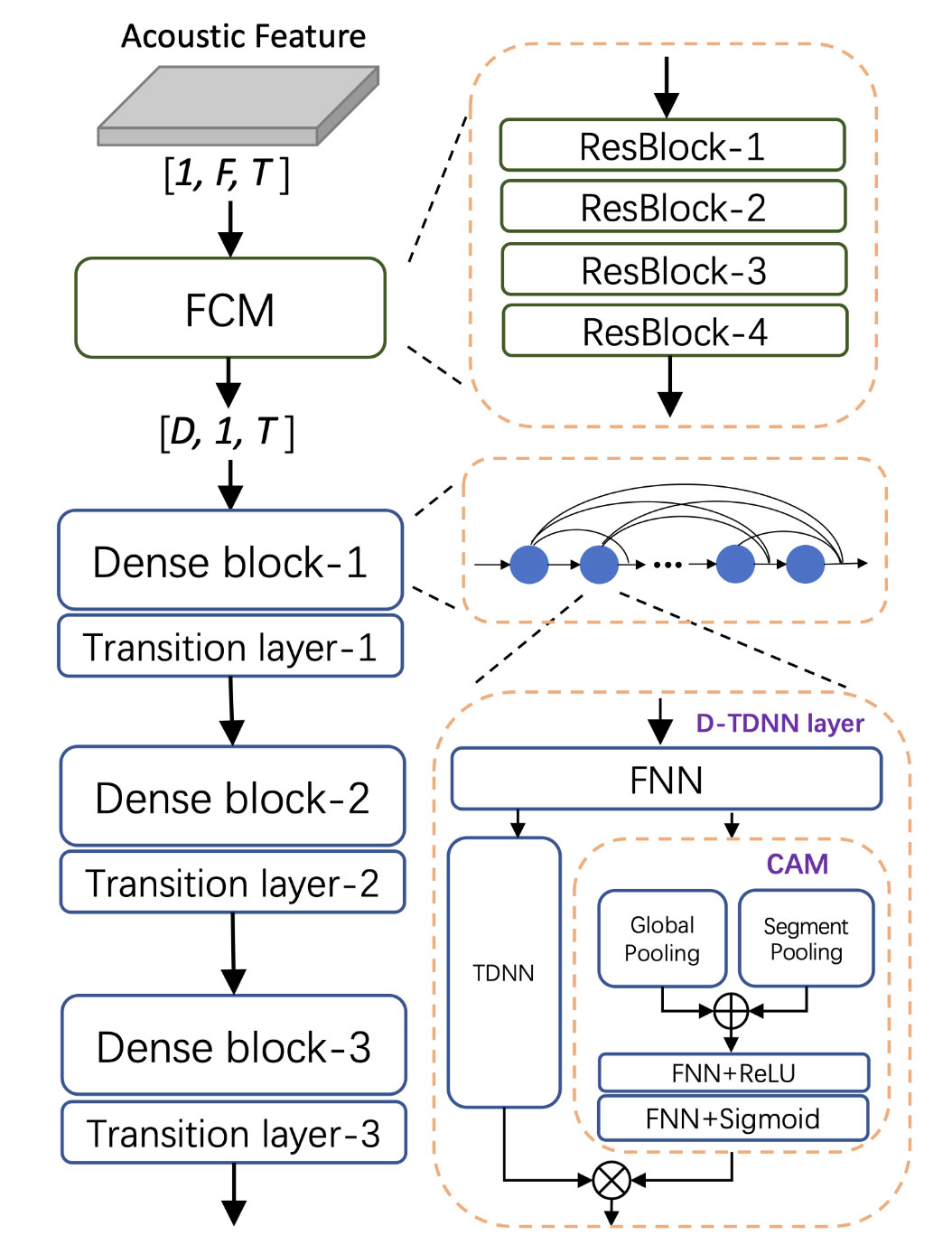
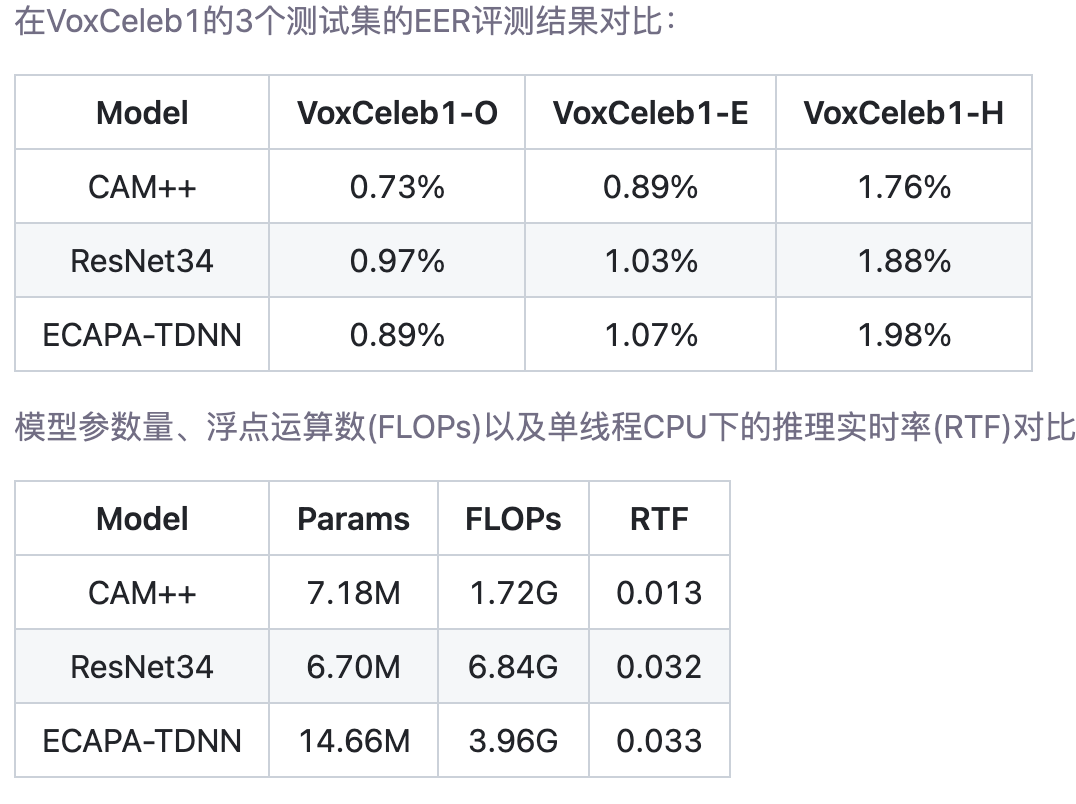
该网络能够同时学习局部信息和全局信息,因此带来了性能的提升。相关的参数量以及性能指标如下图所示:
本文中直接调用CAMPPLUS进行说话人特征的提取:
def get_embedding(fbank_feature):
'''
根据活性检测的结果,对每个音频段计算embedding
'''
# model
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
embedding_model = get_asvmodel()
embedding_model = embedding_model.to(device)
fbank_feature = fbank_feature.to(device)
embedding = embedding_model(fbank_feature)
return embedding聚类模块
再使用Campplus计算完说话人特征后,此时得到的是一个包含说话人信息的特征矩阵。然后在特征矩阵的基础上进行聚类,聚类的方法也有很多,在本文中聚焦于谱聚类。其具体的流程如下:


经过步骤1和2后,亲和矩阵所发生的变化如下,可以看到亲和矩阵受到的噪声干扰得到了很大程度上的去除。有利于后续特征值分解以及聚类过程。

在步骤3和4中,通过对亲和矩阵进行特征值分解,得到相应的特征值,特征值排序后,可以根据预先设置的说话人个数选择想要聚类的类别数,也可以根据特征值之间的大小关系,自动选择聚类的类别数。然后最后在使用K-means对这些特征值对应的特征向量进行聚类,得到最后的说话人标签。后续会介绍一下如何使用armadillo c++矩阵计算库来实现这个谱聚类算法。
def cluster(embeddings, p=.01, num_spks=None, min_num_spks=1, max_num_spks=20):
# Define utility functions
def cosine_similarity(M):
M = M / np.linalg.norm(M, axis=1, keepdims=True)
return 0.5 * (1.0 + np.dot(M, M.T))
def prune(M, p):
m = M.shape[0]
if m < 1000:
n = max(m - 10, 2)
else:
n = int((1.0 - p) * m)
for i in range(m):
indexes = np.argsort(M[i, :])
low_indexes, high_indexes = indexes[0:n], indexes[n:m]
M[i, low_indexes] = 0.0
M[i, high_indexes] = 1.0
return 0.5 * (M + M.T)
def laplacian(M):
M[np.diag_indices(M.shape[0])] = 0.0
D = np.diag(np.sum(np.abs(M), axis=1))
return D - M
def spectral(M, num_spks, min_num_spks, max_num_spks):
eig_values, eig_vectors = scipy.linalg.eigh(M)
num_spks = num_spks if num_spks is not None \
else np.argmax(np.diff(eig_values[:max_num_spks + 1])) + 1
num_spks = max(num_spks, min_num_spks)
return eig_vectors[:, :num_spks]
def kmeans(data):
k = data.shape[1]
# centroids, labels = scipy.cluster.vq.kmeans2(data, k, minit='++')
centers, labels, _ = k_means(data, k, random_state=None, n_init=10)
return labels
# Fallback for trivial cases
if len(embeddings) <= 2:
return [0] * len(embeddings)
# Compute similarity matrix
similarity_matrix = cosine_similarity(np.array(embeddings))
# Prune matrix with p interval
pruned_similarity_matrix = prune(similarity_matrix, p)
# Compute Laplacian
laplacian_matrix = laplacian(pruned_similarity_matrix)
# Compute spectral embeddings
spectral_embeddings = spectral(laplacian_matrix, num_spks,
min_num_spks, max_num_spks)
# Assign class labels
labels = kmeans(spectral_embeddings)
return labels后处理
本文中的后处理阶段主要目标就是将聚类得到的说话人标签和相应的时间戳对应起来,完成”who spoke when”的目标。整体的代码逻辑如下:
for utt, subseg_to_labels in utt_subseg_labels.items():
if len(subseg_to_labels) == 0:
continue
(begin, end, label) = subseg_to_labels[0]
e = end
for (b, e, la) in subseg_to_labels[1:]:
if b <= end and la == label:
end = e
elif b > end:
merged_segment_to_labels.append((utt, begin, end, label))
begin, end, label = b, e, la
elif b <= end and la != label:
pivot = (b + end) / 2.0
merged_segment_to_labels.append((utt, begin, pivot, label))
begin, end, label = pivot, e, la
else:
raise ValueError
merged_segment_to_labels.append((utt, begin, e, label))仿真结果
针对如下的两人说话的测试音频
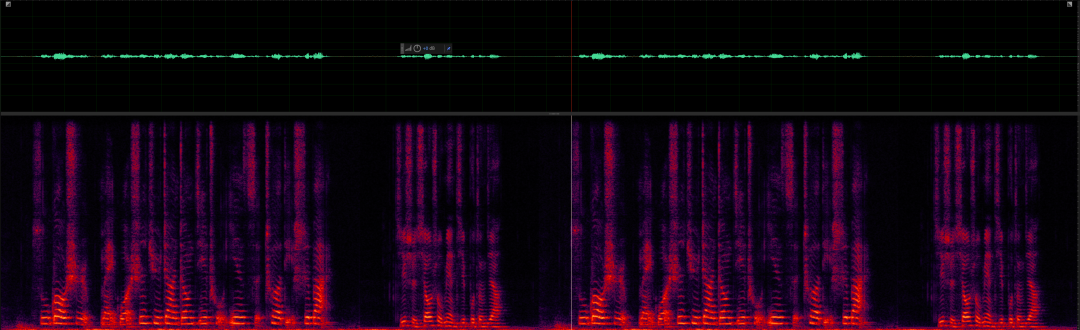
vad得到的时间戳如下,针对于这条简单的测试音频,vad时间戳的计算还是很准确的。
sd_test-00000200-00005430 sd_test 0.200 5.430
sd_test-00005880-00008190 sd_test 5.880 8.190
sd_test-00008590-00013820 sd_test 8.590 13.820
sd_test-00014260-00016950 sd_test 14.260 16.950经过后续的说话人特征提取以及谱聚类后,得到最后的说话人日志结果如下(结果以RTTM格式展示):
# 说话人0的发言时间段是 0.2s ~ 5.23s+0.2s
SPEAKER sd_test 1 0.200 5.230 <NA> <NA> 0 <NA> <NA>
# 说话人1的发言时间段是 5.88s ~ 5.88s+2.31s
SPEAKER sd_test 1 5.880 2.310 <NA> <NA> 1 <NA> <NA>
# 说话人0的发言时间段是 8.59s ~ 8.59s + 5.23s
SPEAKER sd_test 1 8.590 5.230 <NA> <NA> 0 <NA> <NA>
# 说话人1的发言时间段是 14.26s ~ 14.26 + 2.69s
SPEAKER sd_test 1 14.260 2.690 <NA> <NA> 1 <NA> <NA>总结
说话人日志是一个很复杂的任务,上面介绍的只是一个简单的说话人日志实现。实际中的说话人日志功能的实现还需考虑说话人重叠,说话人个数等等一系列问题,都需要慢慢去解决。本文的代码地址如下:https://gitee.com/Wilder_ting/speaker_diarization
作者:ctwgL
来源:音频探险记
原文:https://mp.weixin.qq.com/s/bsQDIfGLw2C9gT1aDLLOvQ
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
