
在提到人工智能时,我们会很容易的联想到AlphaGo、ChatGPT4等模型。人工智能在智力测试或下棋时表现出了达到甚至超过成年人的水平。然而在感知和行动方面,让它们具备一岁孩子的水平都很难实现。比如在厨房中的各种活动,像用勺子搅拌、切洋葱等动作,这些都是一个12岁的孩子能做的,今天没有机器人能做。Jitendra教授的工作就是研究机器人的感知与运动。在这个讲座中,他将向我们分享他的研究经验与成果,向大家展示如何通过机器学习控制机器人的运动。
题目:The Sensorimotor Road to Artificial Intelligence
主讲人:Jitendra Malik
来源:Berkeley Talks episode
视频链接:https://www.youtube.com/watch?v=f6fDpKDxpL0
内容整理:李江川
自然界的感知运动
可以说智力始于大约5.5亿年前的寒武纪,当时有了第一只可以移动的多细胞生物。移动给它带来了优势,因为它可以在不同的地方找到食物。但如果你想在不同的地方移动和寻找食物,你需要感知,你需要知道去哪里,这意味着你需要有某种视觉系统或感知系统。就像Gibson所说的:“We see in order to move and we move in order to see.”
这引发了一场进化军备竞赛,捕食者必须在视觉上变得格外高效,或者移动得更快,这种移动能力和感知能力是动物大脑中最重要的组成部分。让我们更接近现代,比如说原始人,在过去的500万年里,两足动物的进化,解放了制造工具和使用工具的双手,这实际上是大脑的发育跟随着手的发育。最后,我们来到最近的时代,过去5万年左右,我们有了来自非洲的现代人,有了语言、抽象思维、象征行为,所有这些都是一般大众认为的智慧。如果把过去的24小时看作是智力的历史,那么在最后三分钟里,才有了这些语言,象征性的行为,我们很自豪地把它们称为智力的象征。
人工智能的局限
现在让我们转向人工智能,无论是取得成功的大语言模型ChatGPT,还是仍在研究进程中的无人驾驶,最终的结果都是训练带来的。现在我们有一些计算技术,使我们能够训练这些非常大的模型。对于语言模型来说,网络上的数据就像万亿计的符号一样,这些都被使用了。我们在这些模型中看到了涌现的语法和语言能力,它们就像网络的联想记忆。

我们所有人都要意识到,在人工智能中,我们遭受着所谓的Moravec悖论。Steve Pinker后来对这个悖论做了简洁的总结:“35年以来人工智能研究的主要教训就是,难题很容易而简单的问题很困难”。普通人认为很容易的事情对人工智能来说其实很难。然而,我们认为困难的事情,需要通过多年的教育来掌握,实际上对人工智能并没有那么困难,或者我们已经在这方面取得了进展。

今天的演讲题目是”感知运动智能”,它涉及到进化早期的概念。感知和运动等问题在生物进化的早期阶段就已经存在。那么,我们在这些问题上要怎样取得进展呢?为什么后来的更先进的知识文化问题没有那么困难呢?Moravec 给出了一个原因,我认为这不是完全正确的,但让我陈述一下他的直觉:我们在逆向工程技能方面会有更多的困难,而这些技能是数亿年进化的结果。感知和行动是这个过程的早期阶段,这很难。我认为一个更好的论点是:当我们的大多数先进模型都基于机器学习时,我们缺乏网络上用于训练机器学习模型的数字化数据。
所以对网络上的文本,每本书都被数字化了,维基百科存在,还有所有这些博客的存在。这是ChatGPT4这样的系统可以利用的知识,而这些知识在你上学读书后也可以接触到。但对于学习感觉运动这种挑战,小孩会在五岁之前有所经历,这些经历都是非常个人化和具体化的,它们还不存在数字化的数据。因此,在接下来的演讲中,我将稍微谈谈我们对这一挑战的尝试,我将向你展示有关机器人的工作,主要是关于腿部的运动和视觉感知等。
机器人的感知运动控制系统
控制系统的主要挑战

在电机控制中,除了面对泛化的问题,我们还有一个额外的挑战,那就是我们需要对扰动的鲁棒性。这是控制的一个核心方面。你稍微敲一下系统,它应该还能正常工作。再然后是适应性的问题,能应对不同的物理环境。我想强调的是,我在这里使用了两个不同的术语。鲁棒性通常用于处理噪声,适应意味着面对不同的地形,系统必须在任何条件下都能很好地工作。
学习在模拟环境中行走
机器人必须学习如何移动每个关节。传统的控制理论家会写下方程,运用数学理论来推导方程。而我们会学习它,这个学习的方式基本上是通过试错。我们的机器人必须做大量的尝试和错误。真正的硬件会损坏,所以你可以在模拟的环境中进行。学习过程中,我们只是设定了一些目标,你必须试着走路不摔倒,你试着有一个想要的速度,你试着使用最小的能量,诸如此类的合理的东西。
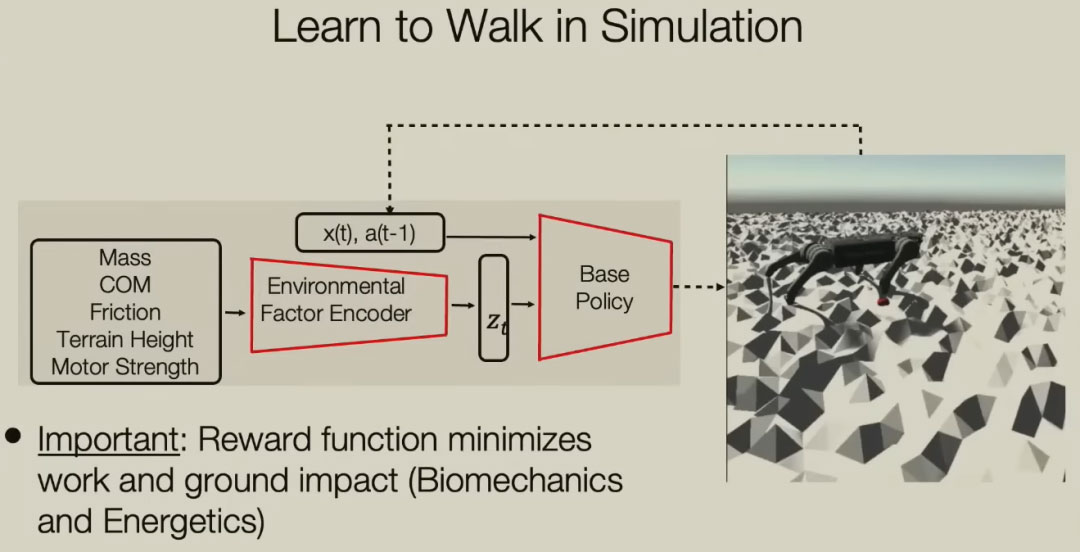
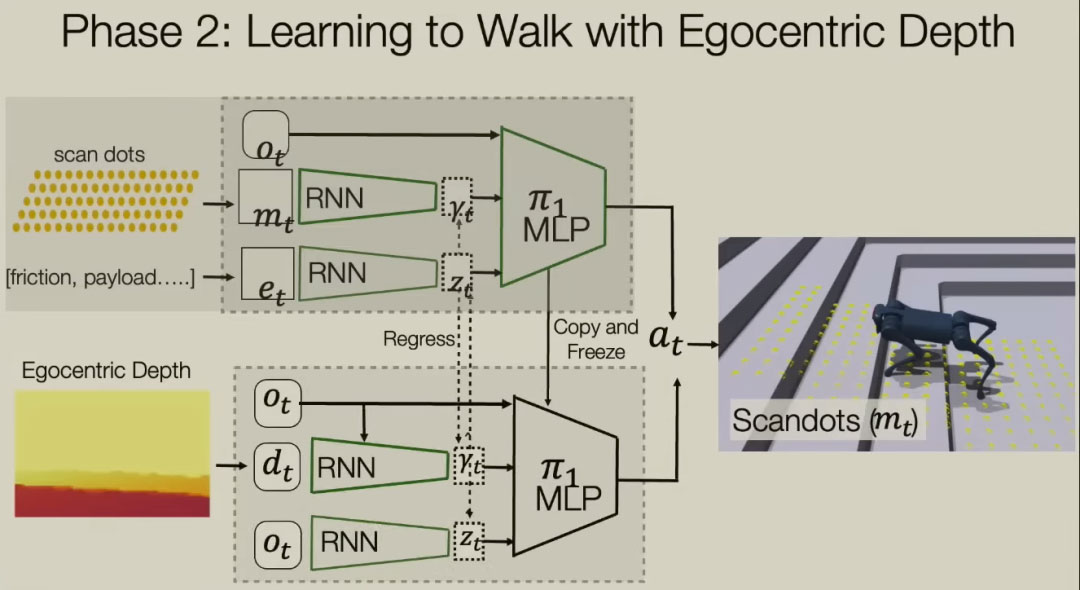
最初的控制策略没有考虑环境信息,只输入机器人当前的状态和前一个动作。事实证明,这样做很困难,因为我们可能会在不同的环境中行走。适用于在坚硬地面上行走的策略与适用于沙子或湿滑表面上行走、上下楼等的策略是不同。那么我们该怎么办呢?在模拟器中,我们事先知道这一点。我们知道质量是多少,我们知道摩擦力,我们知道一切相关的物理参数。这些参数被编码到这个环境因素编码器中,并通过变量Z进行潜在表示。在这个学习过程中,重要的是你要移动,但不要摔倒,而且你要消耗最少的能量,这也是整个模型优化的方向。
通过快速运动适应在现实世界中行走
通过之前的训练,我们的机器人已经能够在模拟的环境中行走。但如果我们试图把它带到现实世界,就面临着一个问题,问题是这些环境因素是未知的。在模拟环境中,我能捕捉物理参数,在不同的条件下训练。在现实世界中,我怎么知道我属于哪种情况?于是我提出了元学习(meta learning)。这里的元学习是观察你自己的行为,并从中推断出你所处的条件。我在不同条件下应用的相同操作会产生不同的输出,我可以意识到这一点。这对我来说是一个信号,表明我处于不同的状态。因此,同样的行为会产生不同的后果,这些可以是我对自己状况的解读。
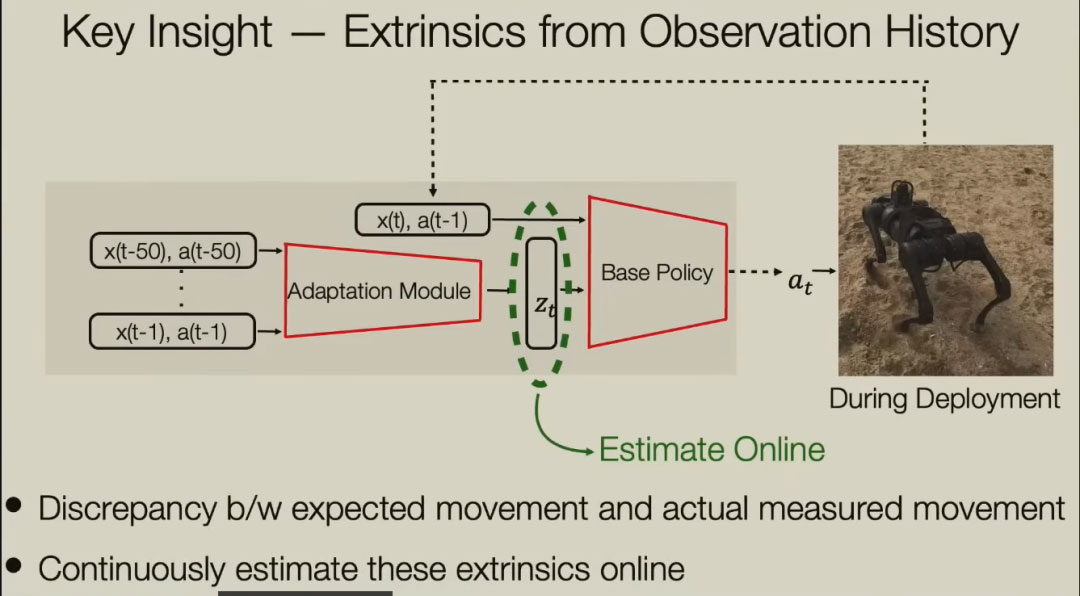
元学习也在模拟环境中得到了训练,因为在模拟环境中,我可以改变条件,然后我可以训练这个估计器,它估计我所处的条件。最终我得到了一个稳健的控制系统,它是适应性的,以不同的方式在不同的环境中行走。
下图展示了机器人面临环境变化时,自适应调整运动状态的能力。最上面四行代表机器人四肢是否与地面接触,第一条曲线是施加在膝盖上的力和扭矩,接下来两条曲线是环境因素的潜在表示Z。当机器人从摩擦较大的地面走到表面涂油的塑料膜上时,元学习模型快速调整了估计的环境条件,最终指导机器人改变了行动模式。

在现实世界中以不同的速度行走
我们要做的是给机器人分配任务,以每秒0.375米、每秒0.9米、每秒1.5米的速度前进,其他一切条件都是一样的。

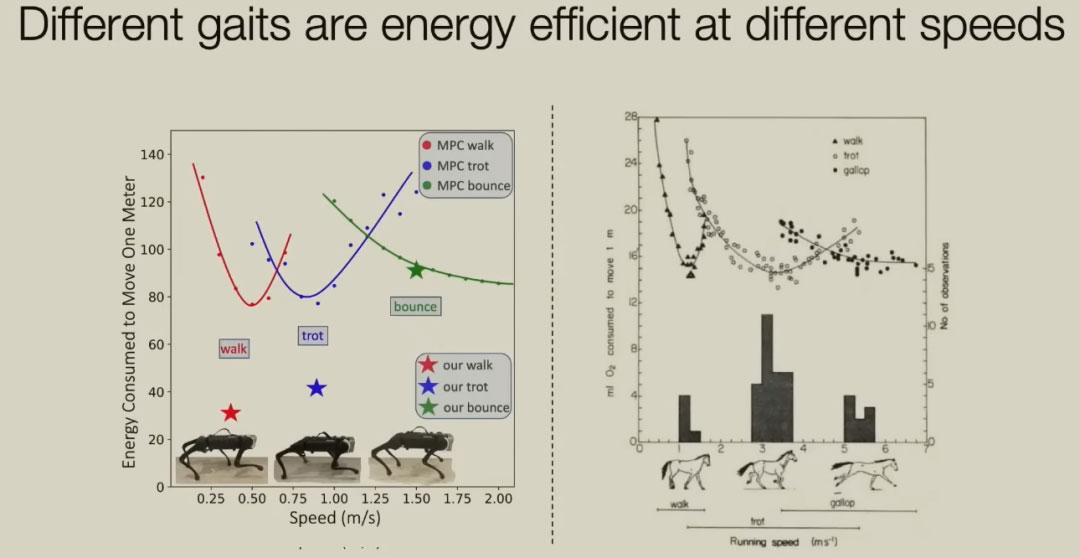
在不同的速度下,机器人产升了不同的步态。当它被要求以每秒0.375米的速度行走时,你会看到一种步态,就像这种缓慢的行走。如果你要求它以每秒0.9米的速度行走,那么你得到的是小跑。如果你设定了一个非常高的速度,现在你当然会注意到,有时四只脚都离地了。而这些步态并没有被编程,它们自然而然的出现了。这一点可以在生物学中找到相应的解释,与之相近的就是马的行走状态。马匹在不同速度下,会选择能量消耗最小的运动状态。我们的机器人已经自发的学习到了这一点。
视觉辅助的感觉运动控制系统
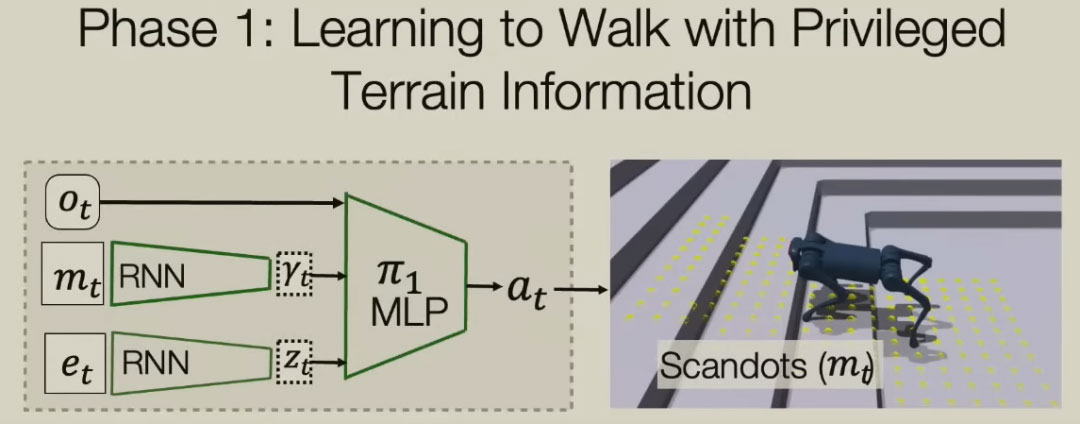
前面所讲到的机器人的行走控制,都是没有视觉信息的。我们的理论是盲人会走路,所以盲人机器人当然应该会走路。那你为什么需要视力呢?在这种情况下,你需要视力,比如上下楼梯等等。这方面有一种传统的技术,即通过组合来自多个视图的信息来构建地图。事实证明,视图会受到噪声的影响,所以生成的地图含有太多噪声了。我们所做的是直接生成控制策略,这意味着当你有了视觉数据,你试图直接控制运动策略。这就像你试图把它变成一种反射,而不是一个非常有意识的过程,比如绘制地图、规划你的足迹等等。这同样可以现在模拟环境中进行训练,这样,机器人学会了在不同地形上移动的方法。之后,我们在机器人头上放置一个摄像机。机器人通过摄像机来估计环境参数,估计地形的几何形状。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
