
4K/8K超高清时代的来临对于原有系统带来很多新的挑战,存储、带宽、算力成本的大幅增长也是阻碍超高清推广普及的重要原因。LiveVideoStackCon 2023上海站邀请到了腾讯云音视频的刘兆瑞分享在4K/8K超高清视频在实时编码的过程中遇到的困难以及解决方案。
文/刘兆瑞
编辑/LiveVideoStack
原文/ https://mp.weixin.qq.com/s/ccZ6fY4XnH7-4ULf0ntbdg
大家好,今天跟大家分享下在支持4K/8K超高清视频的实时编码、媒体处理、系统架构、专有云流量分发所遇到的困难和挑战,希望能给大家带来帮助。
分享内容分为六个部分:
01 4K/8K超高清视频的背景


随着央视冬奥会和央视8K频道的播出,超高清视频已经走进了人们的生活,需求也逐步上升。然而,8K视频的普及度仍然不够,原因如下:
1、对原有的直播系统架构带来极大冲击。比如,8K直播的码率普遍高于100M。其次,通常直播流的分发要通过媒体处理的手段将8K的原始流转成不同的分辨率、码率、帧率之后再进行分发。对系统的算力消耗、处理速度、处理成本带来了新的难点。
除此之外,真8K的视频制作流程也需要高昂的制作成本,导致8K的片源还比较稀少。但也许AI手段能提供一些帮助,例如将原本4K视频超分至8K以达到8K的清晰度,来弥补高清片源稀少的问题。一套成本低廉、压缩率高且有一定增强能力的实时直播媒体处理平台,以上问题和痛点都可以解决。
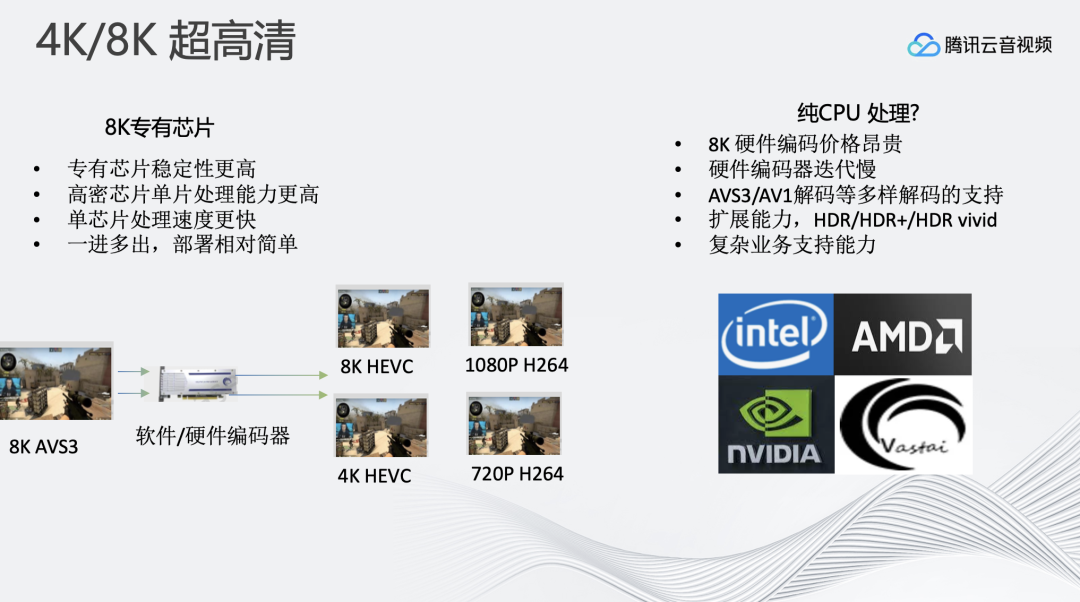
基于这样的背景,开始投入超高清直播媒体处理平台。首先遇到的问题是技术选型,通过CPU的方式支持还是专有芯片的方式来支持。硬件方案的优点是极高的编码出帧稳定性,低廉的计算成本。软件方案的优点是算法设计能更加灵活,纯CPU编码器可以通过算法设计达到比硬件方案更高的压缩率。同时软件方案的升级更加方便。如:原硬件芯片支持8K265编码,后续若想要升级支持266编码,对于硬件来说需要重新设计,软件则只需要进行代码升级即可,系统可以持续迭代支持最新的能力。
综上考虑,最终的选型还是偏向纯CPU的实时编码方案。优点是:压缩率更高、能够自由地扩展编码器和解码器、更容易支持复杂的逻辑和业务。另外,纯CPU方案使用的是通用算力,当不进行8K转码的时候,可以很方便的释放这部分资源进行通用CPU算力利用。

目前我们达成的成果:
1、从8K的实时编码来说,8K单机能达到60FPS的实时编码,分布式集群转码能达120FPS的实时编码;
2、因为软件的灵活性,8K实时转码系统能够支持所有主流视频编解码标准;
3、在2022 MSU最新编码器评测报告,获得全项最佳;
4、拥有100+项H.266/VCC编解码专利技术。
02 编解码加速
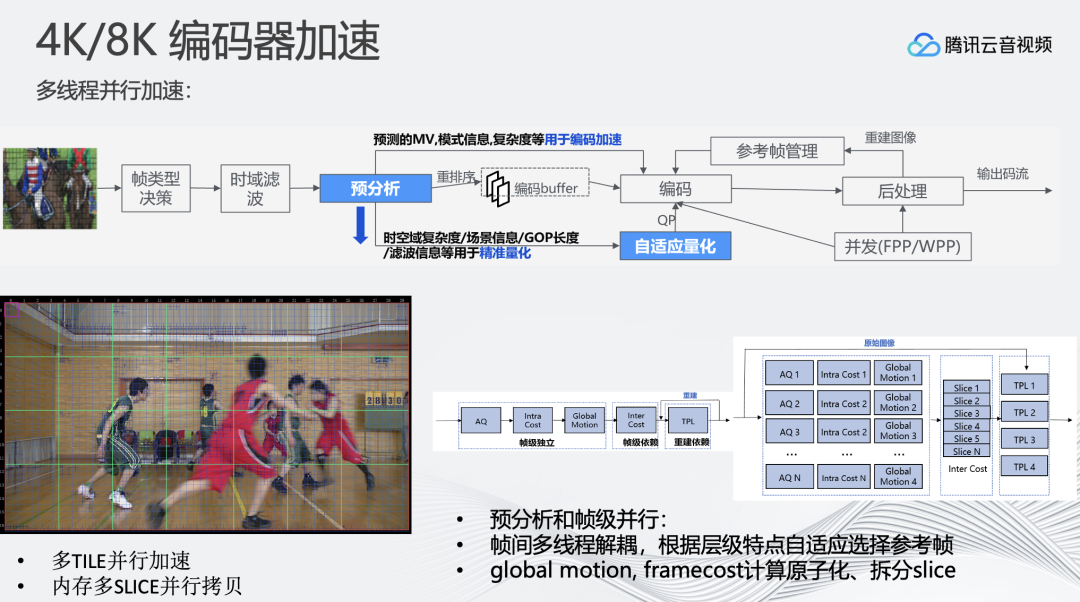
在对8K编码器优化时,主要分为两个方向:
1、优化编码器的并行度,让编码器同时编码更多帧,提高CPU资源利用率。目前我们支持多TILE并行编码。在8K场景下,8K视频帧的拷贝会成为耗时的操作,而编码过程中避免不了将YUV标准排列格式转为编码器内部优化后的YUV排列格式,这一过程需要进行访问拷贝操作,为此我们支持了将8K视频帧分为多个SLICE区间,每个SLICE一个线程来并行加速视频帧拷贝过程。此外还支持预分析和帧级并行、帧间多线程解耦,根据层级特点自适应选择参考帧,提高整体编码的并行度。
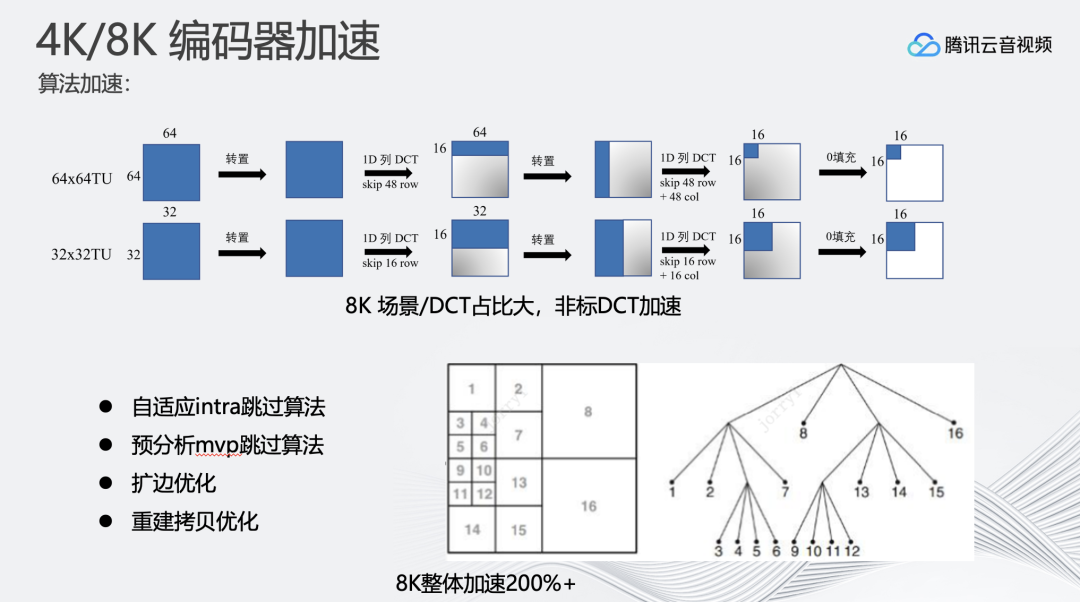
2、另一个方向是直接对编码器算法进行优化。针对8K超高分辨率的编码特性,可以通过预分析mvp跳过原先编码器中的搜索过程;进行帧内帧间分析时,可以自适应选择先做帧内还是帧间,进行快速搜索。
在对编码算法进行加速优化后,会发现8K场景/DCT耗时占比较大。为此支持了非标DCT加速来提升整体速度。
对编码器优化后,纯编码的速度可以达到60甚至70FPS。但一旦将解码加入处理流程中,整个系统的转码速度和效率发生极大的下降。
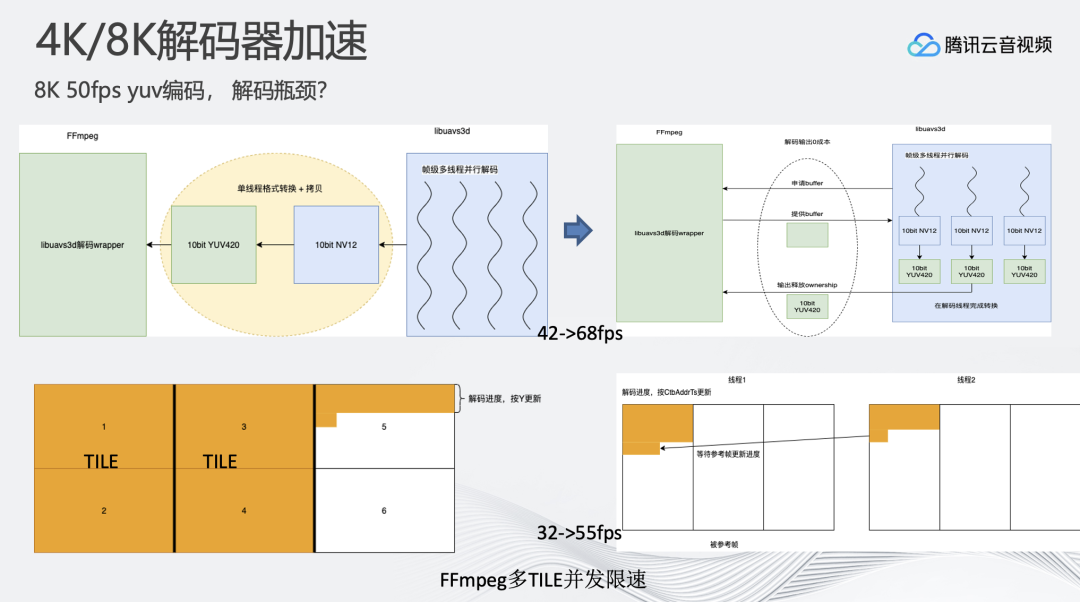
通常4K/1080P解码并不需要耗费很多资源,瓶颈往往都在编码。但在8K场景,解码成为了新的瓶颈。
比如:AVS3格式的解码器,原生输出的是NV12的格式,FFmpeg中间有单线程进行NV12到YUV的转换,最终输出YUV进行后续的操作。这样的做法在4K/1080P分辨率下是没问题的,因为NV12到YUV的转换是一个快速的操作,但8K场景下,NV12到YUV的转换速率很难满足50FPS的要求,我们将NV12到YUV的转换移到了解码器内部。解码之后会在多线程上进行NV12到YUV的转换,来提升整体解码速度。
8K分辨率多TILE的H.265码流则是不同的方案。FFmpeg中H.265的特点是先把第一行完整地解码完毕后,才会进行解码进度更新,若遇到多TILE的情况解码速度会大幅下降。如上图所示,多TILE场景解码完成前两个TILE,并完成第三个TILE第一行时,才会更新解码进度,严重拖慢解码器并行。我们基于多TILE场景对H.265解码器进行优化,将二者结合,单TILE解码完成行解码后,就进行进度通知,优化之后能够达到单机50FPS以上的速度。
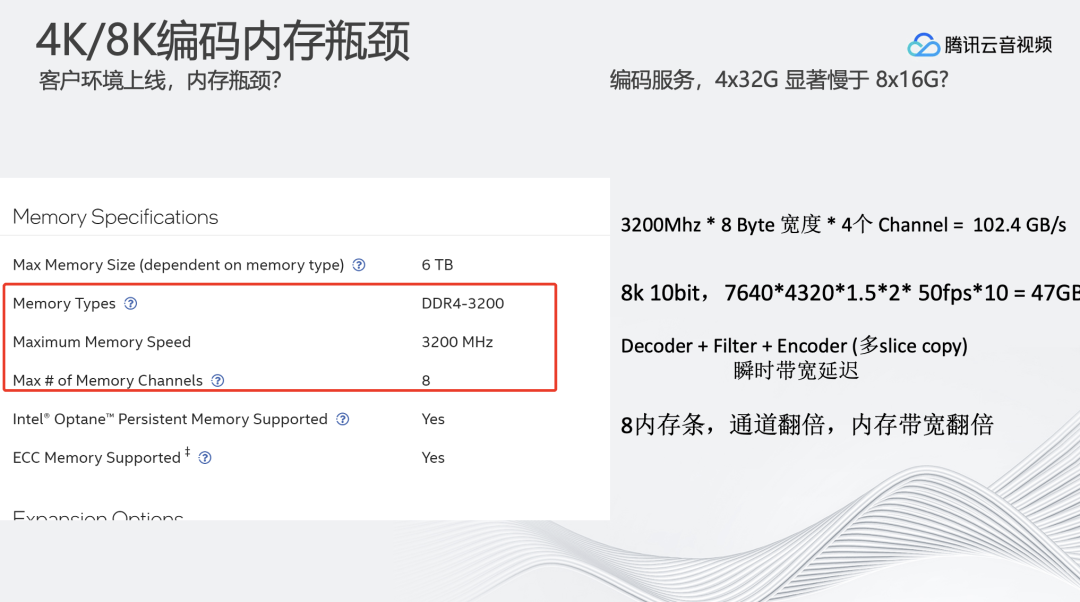
在优化完编码和解码速率之后,我们发现线上同样型号的两台128G内存设备,处理速度相差较大。处理速度快的设备是8×16G的内存,处理慢的设备是4×32G的内存。
内存带宽限制在低分辨率的情况下表现正常,但对于8K高分辨率会造成很大的影响。例如,一个3.2GHz的CPU插了4个32G的内存条,其内存的瓶颈带宽大概在102G,但如果要进行8K50FPS10bit的实时编码,也就是说一秒需要传输的数据带宽大概在4.7G。在实际操作中,内存搬运的过程只能占用编码整体非常小的部分,大部分的时间还是留在编码的运算上。瞬时带宽可能是4.7G的几十倍,尤其是系统内部还支持多线程并行视频帧拷贝,导致瞬时带宽增高,从而导致8K编码的限速。
8K视频编解码对内存带宽的消耗极大,配置设备硬件时,需要注意根据CPU的Memory Channels来配置内存,尽可能增加内存带宽。
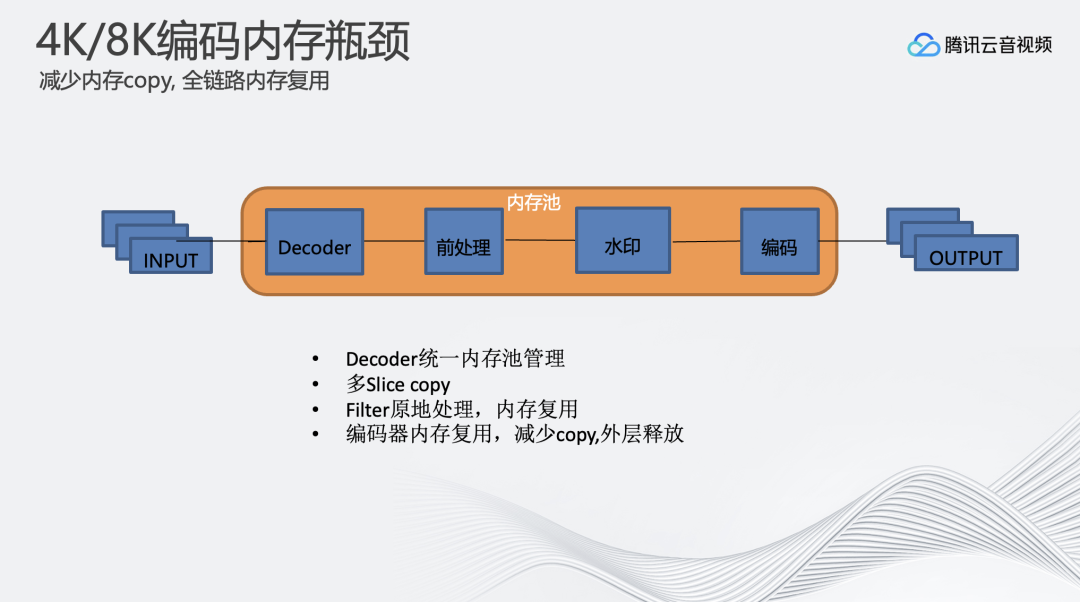
以上这些出现的问题说明在8K场景下,每个操作都需要多加思考,可能仅仅多加了一个拷贝,就会导致系统的慢速导致达不到实时性。在这里对整个内存池进行了重构,在解码、前处理操作、打水印的时候不申请新的内存,将所有操作原地处理,尽量将内存数据拷贝只进行一次。降低内存使用的带宽。
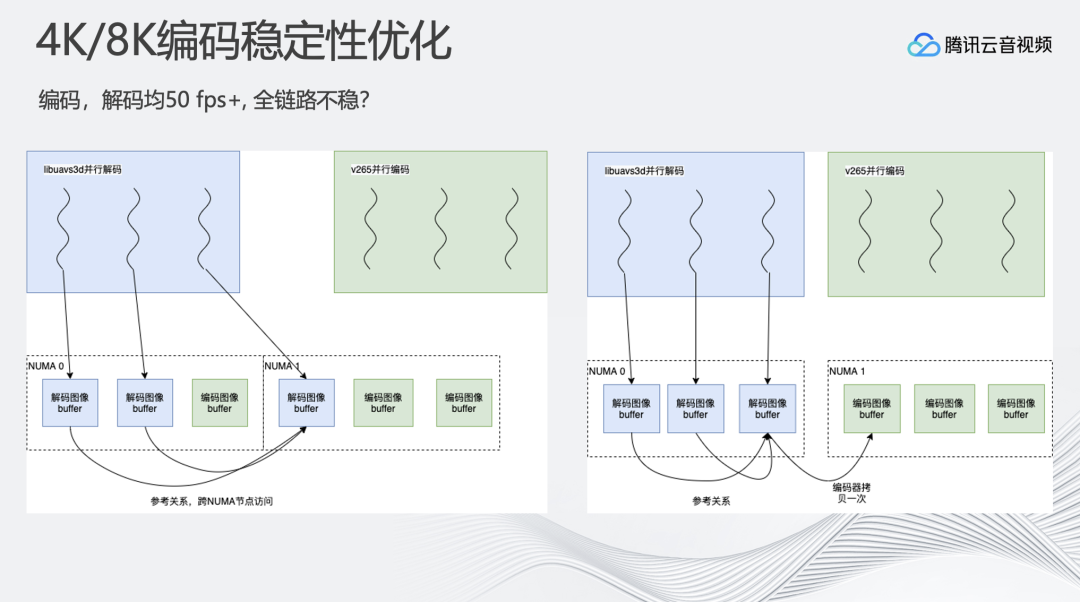
在优化完编解码速度、内存之后,系统在大部分情况下可以稳定运行,但是稳定性不高。对同一个视频流进行反复的编码,但其速度忽高忽低。有的时候完全满足实时要求,甚至更高达到60、70FPS,但有时降速严重只有40FPS。
现代操作系统通常支持NUMA架构来提升多核心内存访问效率。在NUMA架构中,处理器被划分为多个Node节点,并且每个Node节点都有属于自己的独立内存和内存访问控制器。CPU可以通过Node内集成的内存访问控制器访问同Node节点内存,通过QPI总线访问其他Node节点的内存,所以对于同一个Node里的CPU和内存之间访问速度会快于跨Node访问。
在编解码过程中,每颗CPU既进行编码也进行解码,会导致CPU的对应Node节点内存中同时存在解码帧和编码帧, 当编码过程中进行参考时,会产生大量的跨Nde节点访问内存。在8K场景下,跨Node节点访问带来的内存带宽和速度压力会快速放大,导致IO阻塞,并发能力下降。
这个问题的解决方案是:对CPU做核心绑定,将整体转码流程精细化控制。比如,解码、添加水印、转分辨率、编码等等操作都分配到指定CPU上进行,尽量保证相互依赖的操作都在同一个CPU,同一个Node节点内完成,尽可能降低跨Node内存访问。
03 分布式编码

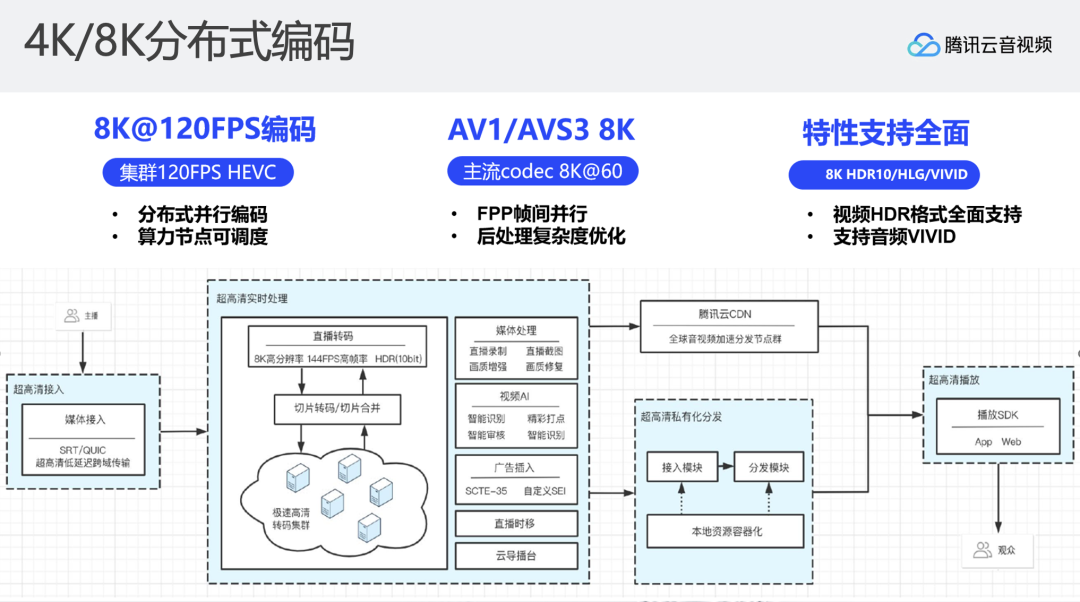
在优化以上问题之后,单机直播系统在线上能够达到稳定8K 50FPS的实时编码。但我们面临的挑战可能是需要达到120FPS的编码速度。我们提出了将直播系统支持分布式转码。点播分布式转码应该比较熟悉,拿到一个文件之后,将文件切成一个个非常小的碎片,将碎片发到多台机器上进行处理,每个机器只处理一个非常短的碎片,最终将转码后的碎片形成一个完整文件。
直播分布式转码其实参考了点播的方式。通常直播转码在一台机器上完成解码、加水印、filter、编码等所有操作,但我们对直播流程进行了改造,它不进行实际的编码,而是拉取一个直播流按照GOP的维度在直播的场景下实时切成一个个的小片,将其发送到现有的点播算力节点,用文件的方式快速转码,转完之后的直播系统再回收这些小片拼成实时的直播流进行下发。整体思路和点播分布式转码相似,从一台机器进行所有操作到n台机器共同进行实时转码,使得编码速度和效率得到大幅提升。
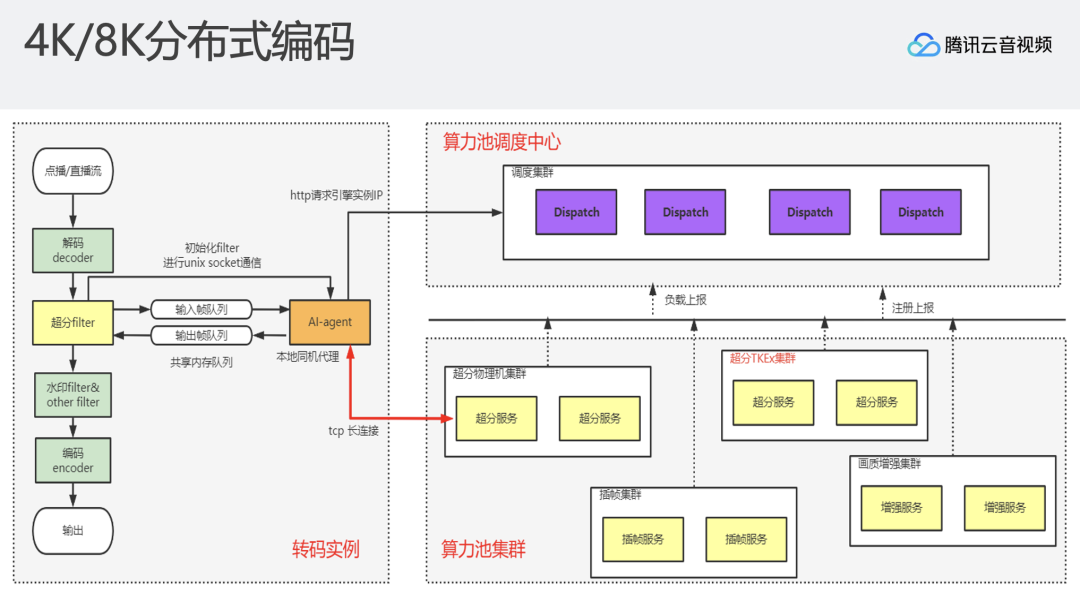
另一部分是如何支持实时超分?通过视频增强、AI增强算法等操作可以实现4K实时超分,但是目前还很难支持实时超分8K。在这个背景下,我们利用分布式增强能力,支持直播过程中从4K到8K的超分。解码出一个视频帧之后,会对这一视频帧进行压缩,将压缩后的视频帧以帧维度发送到下游的增强算力节点,每个算力节点只进行单帧的超分辨率操作。通过算力节点海量的GPU资源,实现直播4K到8K的超分辨率增强。
04 网络优化

作为云厂商,还有很多专有云部署的场景, 专有云环境下网络和设备环境更为复杂。
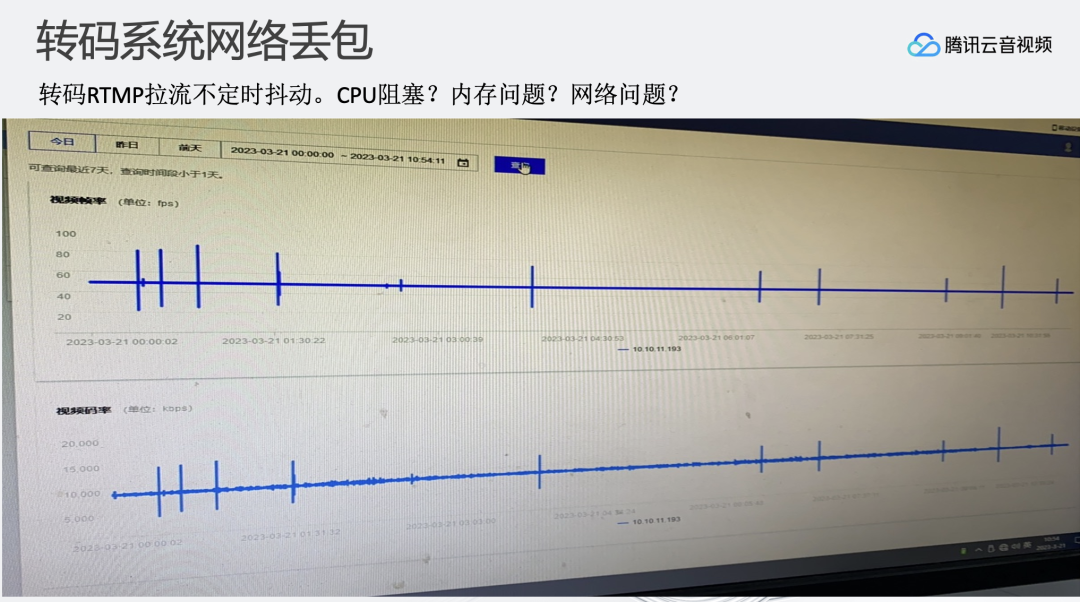
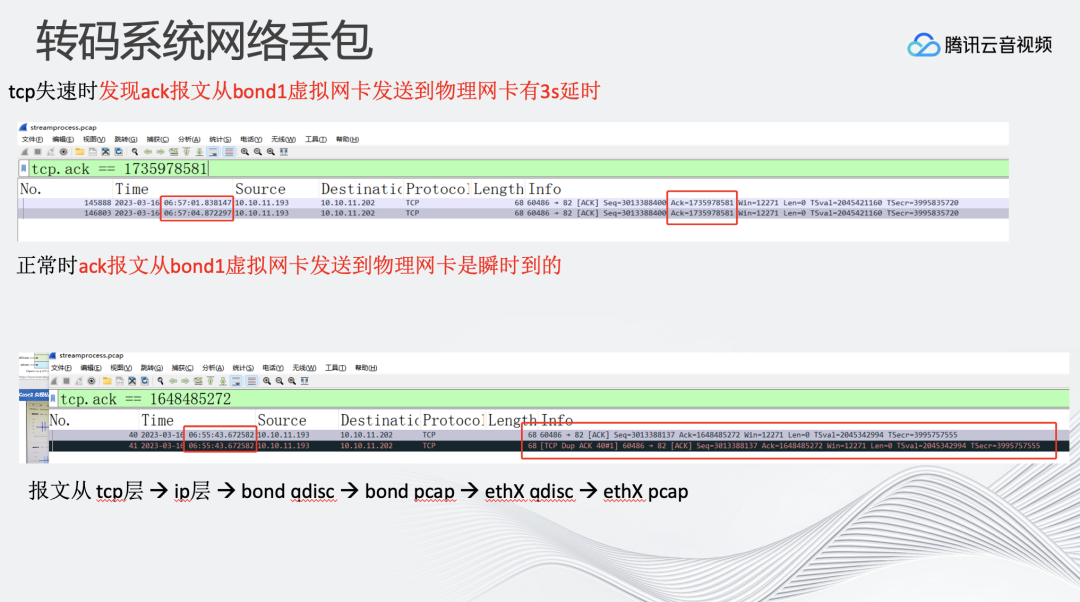
比如,从我们监控中看到大概每过1-2小时,整个直播转码系统会产生TCP慢速的过程。原因可能是我们提供的转码服务收到了拉流数据包之后,ack报文从虚拟网卡发送到物理网卡有3s延时,而正常应该是瞬时。
首先怀疑是否是系统负载问题,在CPU、内存、带宽利用率情况都良好的情况下,发现在某些机器上会发生这样的问题。传输过程是TCP→IP层→bond qdisc→ethX qdisc→ethX pcap。在虚拟网卡和物理网卡分别抓包的过程中发现慢速产生的原因是bond网卡会延迟2-3s的时间发送ack报文。通过netrace工具深入分析,发现从qdisc取包,到发送到驱动过程中,驱动状态表示不可以发送报文。最终确认专有环境设备的网卡驱动, 在大流量传输时产生了异常。
05 分发优化

另外遇到的一个问题是客户的网络环境受限体现在内部网络带宽只有千兆的交换机。
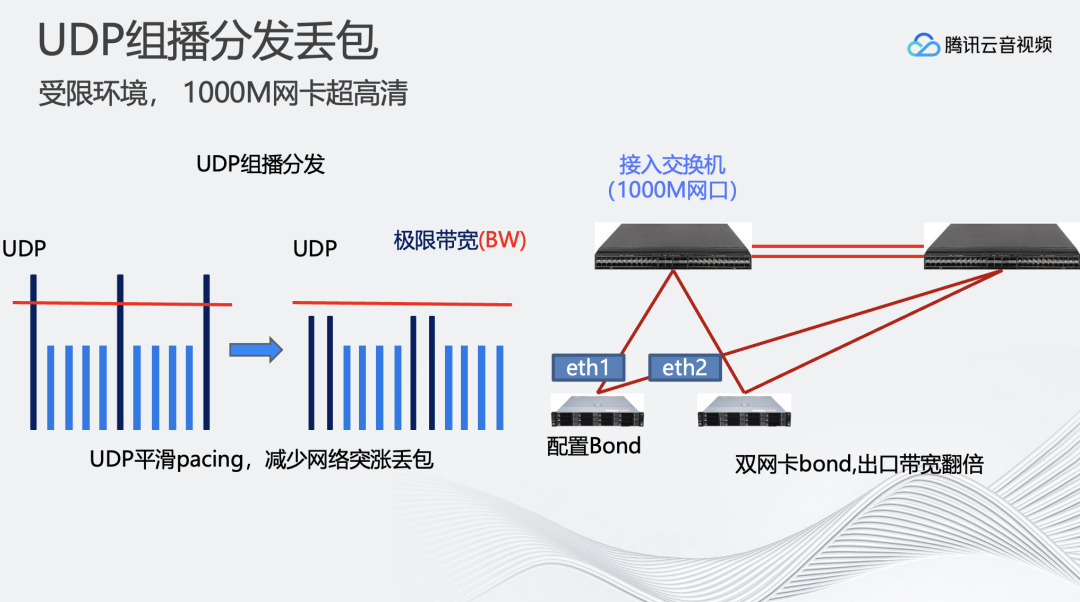
在这个条件下,需要进行更精确的负载均衡的算法,UDP组播发包的时候使用更高性能的API、系统函数等。这里提供几个小技巧:
1、可以对UDP包进行流速的控制。因为编码码率无法做到完全稳定,上下浮动比较大。因此只要UDP发包速率控制在低于网络带宽的限制就可以实现。
2、充分利用交换机的两张网卡。配置bond虚拟网卡,用这个虚拟网卡进行交互,能拓展原先单机的千兆带宽。

经过一系列优化,实时8K转码编码系统也部署在客户的专有环境落地。央视网内部部署的系统支持8K的实时编码。
06 总结与展望
最后是总结与展望。先说转码服务:
1、转码服务首先要进行编码器的优化。编码器的优化分成两个大的方向:首先如何提升整体编码并行度和CPU资源利用率,其次如何减少CPU运算量。
2、针对不同解码器进行不同的解码优化方案。例如,针对AVS3,将NV12到YUV的转换移到了编码器内核层进行操作;针对H265,通过多TILE并行编码进行加速
3、解决了内存带宽的瓶颈。通过管理每一项操作,减少所有内存拷贝和对内存带宽的使用等操作优化内存带宽。
4、转码链路稳定性提升。涉及了远端内存和本地内存的访问,需要规划每一步操作在哪个CPU上运行,减少跨NUMA的操作,提升整体访问效率。
转码集群:
1、 分布式转码通过多机、并行转码的能力支持最高8K 120FPS转码、4K到8K的超分等
2、 针对客户场景,要更关注可能产生的TCP慢速、丢包等问题。其次在客户受限的网络环境下进行UDP发包算法的平滑以及对分发的负载均衡算法的优化。
谢谢大家!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
