
编者按:数字人作为AI能力集大成者,涉及计算机视觉、计算机图形学、语音处理、自然语言处理等技术,正在金融、政务、传媒、电商等领域应用越来越广。LiveVideoStackCon 2023 上海站邀请到华为云的李明磊为我们介绍华为云在数字人领域当前的主要进展,包括2D数字人驱动、3D数字人建模、绑定、驱动、情感数字人生成等,同时介绍数字人领域的一些挑战。
文/李明磊
编辑/LiveVideoStack
原文/https://mp.weixin.qq.com/s/0H6QKa1H8SN3TfABDhjNSw
大家好,我今天分享的是华为云MetaStudio数字人生产线在多模态数字人方面的进展及挑战。我是李明磊,目前担任华为云虚拟数字人技术负责人。我的分享分为以下几部分:

-01-数字人背景介绍
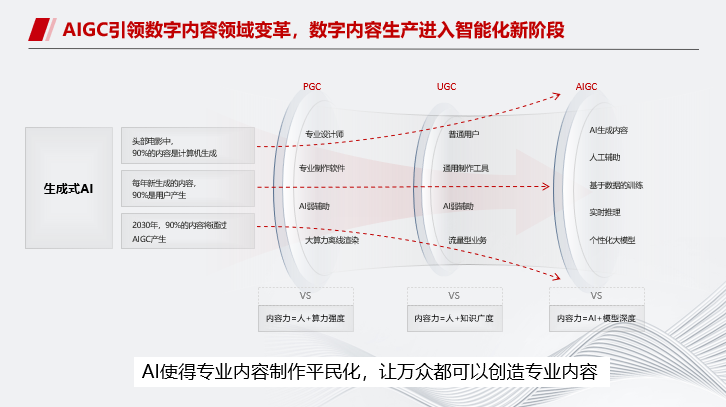
首先,AIGC是今年大热的话题。从PGC、UGC到AIGC,AI的一个核心价值是把专业内容制作的门槛降低了,让更多人都可以参与到专业内容的创作中来。

下面介绍一下数字人。什么是数字人?首先要有三个要素,第一是具备人的外观;第二是具备人的行为;最后是具备人的思想。
为什么称为多模态呢?数字人本身是AI集大成者,涉及视觉、音频、文本等多种模态。

如图是数字人的一些典型应用,在千行百业已经开始落地。
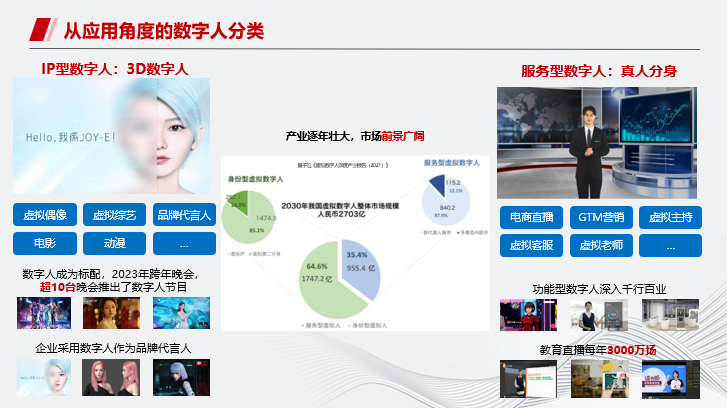
从应用角度的数字人来分类,可以分为IP型数字人(主要为3D数字人)和服务型数字人(真人分身)。上图中间为数字人市场的规模和份额数据。
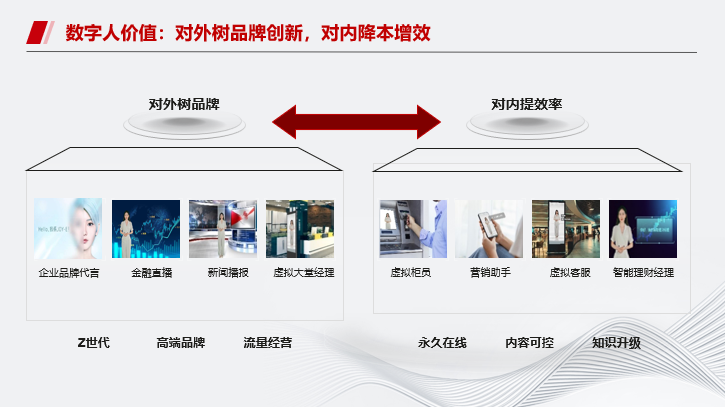
接下来是数字人的价值。数字人可以对外树立品牌形象,并进行流量经营;对内可以提高效率,例如数字人分身直播带货,可以永久在线。
-02-MetaStudio服务及案例介绍

接下来介绍华为云MetaStudio数字内容生产线。我们未来希望所有的内容都生于云、长于云、用于云。图中左侧是华为云在媒体领域的架构:
底层算力算子包括昇腾芯片,同时也兼容N卡;CPU有鲲鹏,也兼容x86。AI框架平台包括训练平台ModelArts、深度学习框架MindSpore以及TensorFlow和Pytorch等。
基于ModelArts,我们有训练加速引擎和推理加速引擎等。再往上一层是媒体引擎和盘古基础大模型。接着是媒体服务,包括云桌面、远程写作平台、数字人生产线等。
总体来讲,华为云可以提供数字人领域从底层到上层全栈服务。
假设一家企业没有数字人,可以使用华为云的数字人生成和驱动服务端到端完成数字人相关业务;如果已有数字人模型,但无法让数字人动起来,可以使用数字人模型驱动服务;如果已有数字人且可驱动,但是想进一步降低成本,可以使用华为云的底层算力服务。

针对客户想从零开始制作数字人的需求,华为云提供全栈的数字人解决方案。主要包括IP型数字人和服务型分身数字人全方位的解决方案。在底层会提供包括建模、驱动、仿真、渲染等能力,并基于这些能力开放一些API,让联合伙伴可以根据行业进行应用。
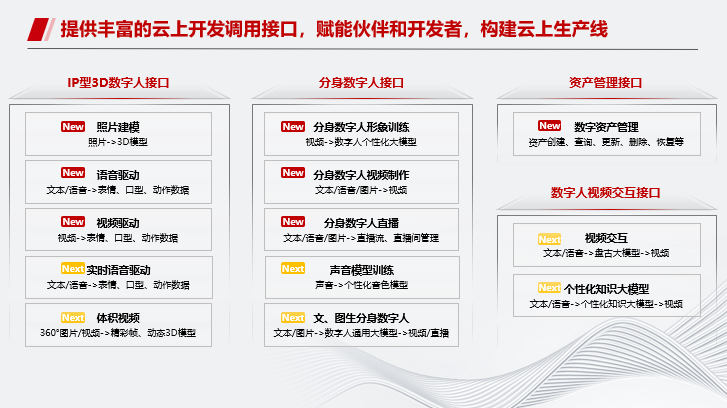
华为云目前提供两大类数字人相关服务,比如IP型3D数字人的照片建模、语音驱动、视频驱动等,以及分身数字人的形象训练、视频制作等;同时还包括数字人资产管理相关的服务。目的就是为了让伙伴和开发者可以快速集成华为云的底层API接口。

这两个视频演示如何制作一个服务型分身数字人以及如何制作一个IP型数字人。

下面重点介绍下分身数字人的具体应用场景。其当前已经在各个领域广泛使用,主要是用于复刻真人并把真人从重复的劳动中解放出来,同时也能够超越真人,实现真人无法实现的功能,比如多语种、渊博的知识等。

华为云MetaStudio分身数字人解决方案主要提供三大服务:
数字人视频制作:无需拍摄,通过输入文字生成视频。
数字人视频直播:一天24小时不停直播带货,用算力换人力并超越人力,真正实现不受地域限制、不受模特资源限制的、不受语种限制的全球全天候直播。
数字人视频交互:结合ChatGPT等对话机器人,可以实现实时智能交互,通用问答、垂直知识库等都能解决,可用于虚拟讲师辅导等。

这里介绍不同场景下数字人效果:和真人对比,真假难辨;同时支持移动场景,即可实现可走动的分身数字人;基于分身数字人可以制作数字人名片,更加亲切。

另外,还可以通过一次训练,实现多语种驱动。通过录制5分钟中文演讲视频,就可以生成分身数字人,用于多语种的视频生成。

这是分身数字人用于金融新闻播报的案例。

我们还做了另外的尝试:通过和华为云会议系统结合,实现了数字人参会,通过你的真人声音驱动你的数字人。
不管你有没有化妆,躺在床上都可以以正式的形象参会。当然,这里也会加入基于声纹、人脸识别等多模态的身份认证,防止用其他人形象参会。

以上介绍了分身数字人的应用场景,分身数字人也有自身缺点,比如无法实现多视角观看、大幅度转身,无法在3D空间中自由奔跑、走动等。
数字人中的另外一个重要分支是IP型数字人,即打造一个数字人形象,作为一个公司、组织的IP。相比传统的IP,如明星大V等,IP数字人的优势在于颜值无限美,才华横溢,人设稳定可控,市场响应快,性价比更高。
2021年被业界称为元宇宙的元年,元宇宙可能还离我们很远,但是我们看到数字人的应用已经进入到了很多行业。
比如在影视综艺行业,湖南台的虚拟主持人小漾,主打了湖南台黄金档节目“你好星期六”,成为新的明星IP。
在文娱电商行业,已经有近10万的虚拟数字人主播。B站的数字人主播洛天依,出场费高达90万,是普通主播的10倍。湖南多豆乐基于华为云打造的数字人方小锅,粉丝达到了1千万。
为什么那么多行业和公司热衷于做虚拟数字人?抛开当前元宇宙技术来讲,虚拟人本身有自身的优势:
①颜值无限美。虚拟人的外在形象非常完美,颜值也不会下降,甚至可以根据人们的审美进行进化调整,相比娱乐圈的明星来说,虚拟偶像的外形条件具备天然的优势,甚至永远不会发胖、超越年龄限制,不会变老。
②人设稳定。永远不会崩塌,不会有绯闻等各种负面消息。
③才华横溢。可以叠加各种才华,艺术、科技等可以无所不能,集万物于一身,可以做到颜值才华兼备。
④可操控强。不需要遵循数字人的个人意愿,即可安排符合数字人品牌定位的事宜。更没有档期风险。

如图是华为在IP型数字人领域可以提供的能力,包括建模、驱动、和渲染,以及一些实际应用的IP型数字人形象。

这是数字人作为活动主持人的实际应用案例。
以上介绍了数字人的背景、华为云MetaStudio在数字人领域的服务和应用案例,下面重点介绍数字人背后的技术。
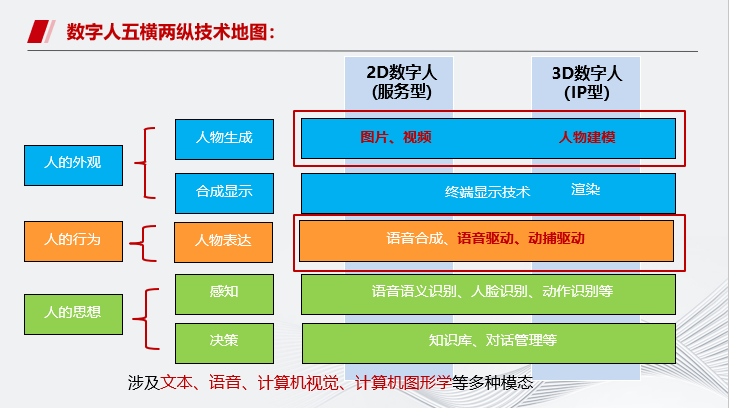
从技术角度,主要分为五横两纵。
“五横”是指用于数字人制作、交互的五大技术模块,即人物生成、 人物表达、合成显示、识别感知、分析决策等模块。其中,人物表达包括语音生成和动画生成。动画生成则包含驱动(动作生成)和渲染两大部分。
“两纵”是指 2D、 3D 数字人,3D 数字人需要额外使用三维建模技术生成数字形象,信息维度增加。
数字人是AI集大成者,涉及自然语言处理、计算机视觉、计算机图形学、语音处理、多模态、生成等。本次技术介绍主要涉及数字人形象构建以及驱动相关技术。
下面分别介绍服务型即2D数字人关键技术和IP型即3D数字人关键技术。
-03-分身数字人技术介绍
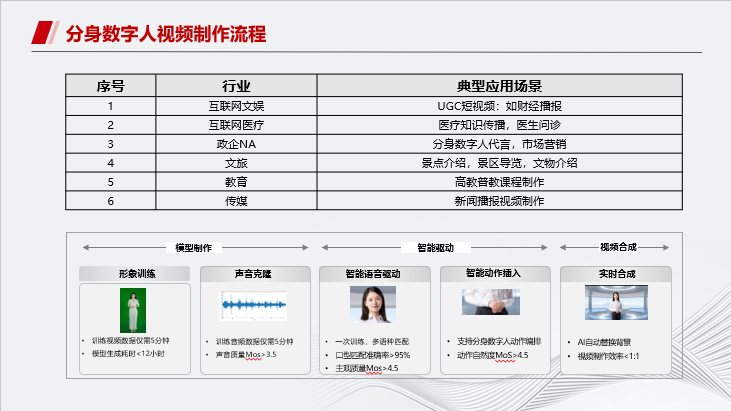
这是分身数字人的视频制作流程。首先是形象训练,训练视频数据仅需5分钟,并且模型生成耗时<12小时;如果对声音有要求,还可以做声音克隆;然后输入文本进行智能语音驱动,以及智能动作插入;最后进行实时合成,生成视频。

在直播场景中,前三个步骤和上述一致,不一样的地方在于要进行直播话术的输入,再进行实时推流。
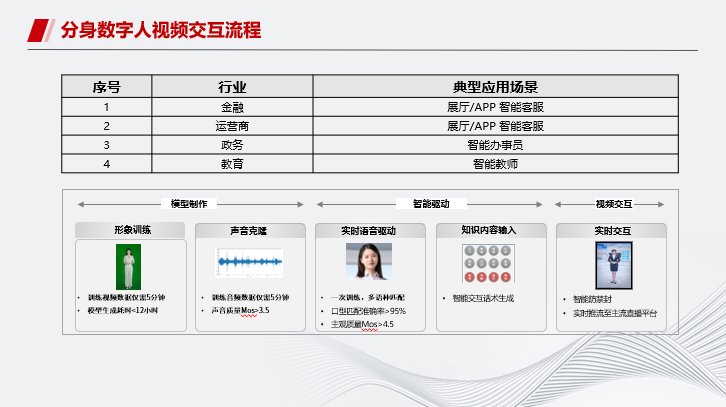
在交互场景中,要进行知识内容输入,生成智能交互话术,并进行实时交互的应用。
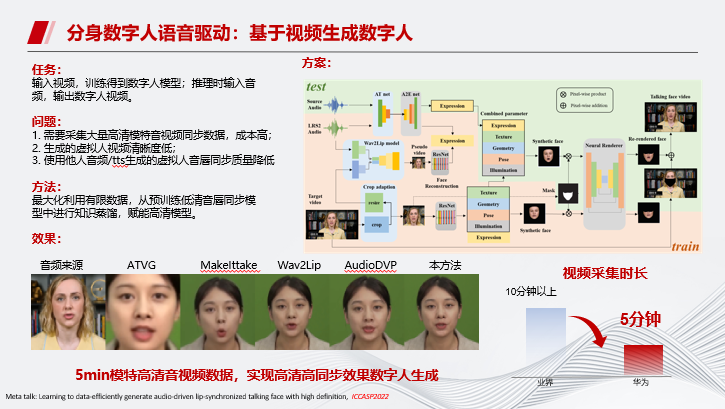
接下来介绍基于视频生成数字人的原理。
首先,任务是输入视频,训练得到数字人模型,并在推理时输入音频,输出数字人视频。
传统的方法需要采集大量高清模特音视频同步数据,成本很高;华为云把视频采集市场缩短到了5分钟,采用低质量视频做预训练,再用高质量视频做微调。
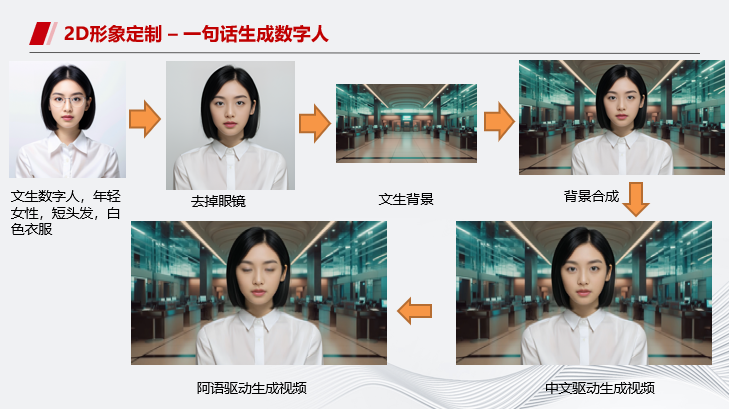
另外,我们还尝试了通过文本生成数字人,避免了绿幕录制的繁琐以及肖像权的争议,同时还可以随时通过文本进行数字人形象调整。
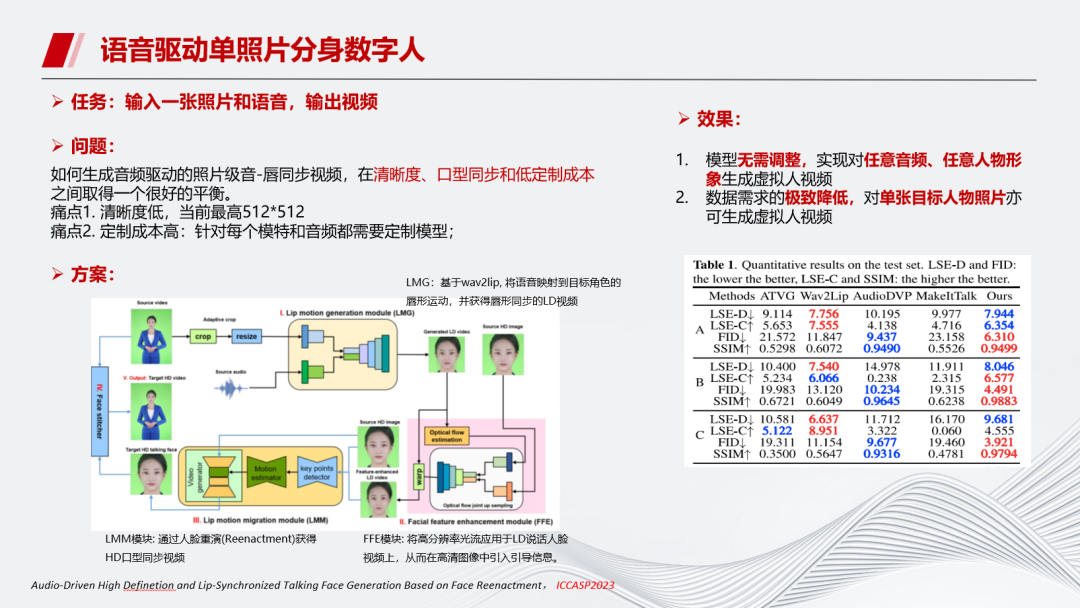
接下来介绍语音驱动单照片分身数字人的原理。
我们希望输入一张照片和语音,输出视频,首先通过wav2lip做预训练基础,再通过动作迁移的方式,把后台预制的视频迁移到照片上。
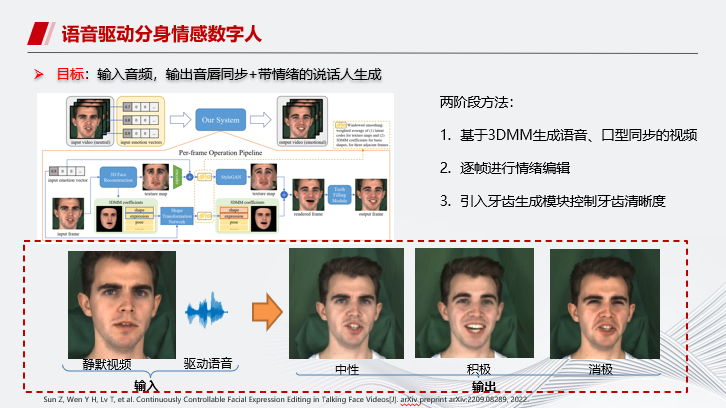
另外我们也探索了语音驱动分身情感数字人。除了中性表情之外,实现数字人积极和消极表情的输出。
整体的逻辑是首先生成中性表情的数字人,再逐帧进行情绪编辑,另外引入牙齿生成模块控制牙齿清晰度。
-04-IP数字人技术介绍
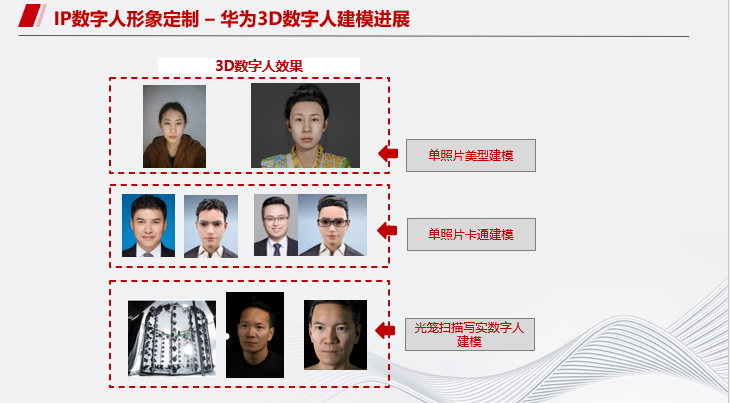
接下来介绍IP数字人技术。华为3D数字人目前可实现单照片美型建模、单照片卡通建模以及光笼扫描写实数字人建模。
美型建模的技术流程是:输入人像图片后,会进行人像证件化的预处理,然后进行形状建模,再进行配件组装和皮肤生成,最终输出完整的3D模型。

接下来是传统超写实3D数字人建模,即3D分身。其成本非常高,传统方法需要光笼扫描,再进行几何重建,需要大量的人工参与,所以华为云在探索如何进行通过AI的方式加速这一流程。
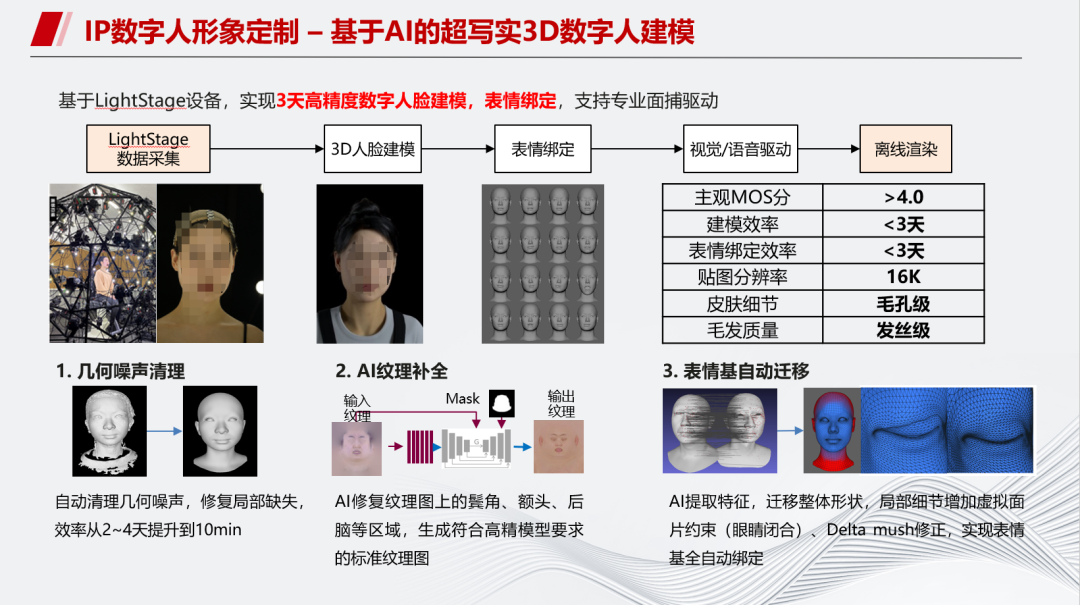
如图是基于AI的超写实3D数字人建模的技术路线。因为整个流程涉及很多环节,目前的思路是如果不能端到端全AI化,那么就在每个环节AI化。例如在3D建模阶段,在光路扫描后通过AI进行建模。目前整个周期可以压缩到一周左右。
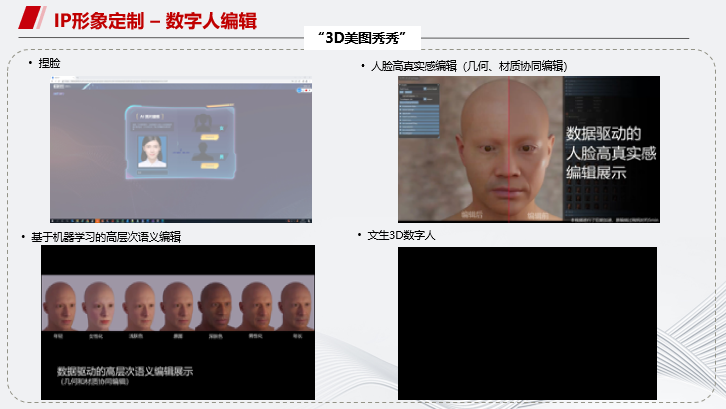
完成建模之后,还可以进行二次编辑。这里展示几种不同的编辑方式,意在使编辑操作更加易用。
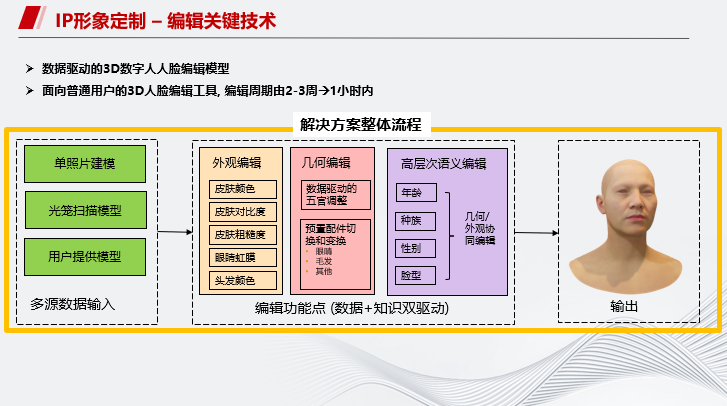
如图是编辑关键技术流程,包括外观编辑、几何编辑和高层次语义编辑等功能点。

编辑完成之后,结合表情绑定,就可以用来做驱动了。那么如何进行驱动呢?如图中右侧所示,单目视觉驱动是通过摄像头实现,捕捉中之人的动作,以驱动数字人的相应动作。
其底层技术是基于华为云在ECCV 2022 Oral发表的一篇论文,在AGORA动捕榜单上持续位列第一。
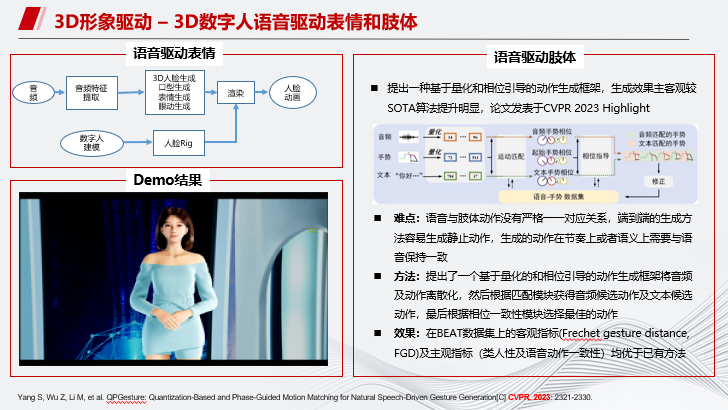
如图是3D数字人语音驱动表情和语音驱动肢体的技术流程,可以实现去人化,完全通过语音驱动数字人。
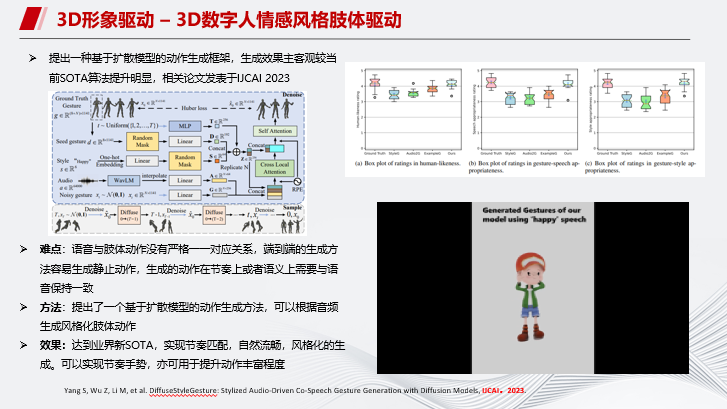
另外我们也在3D数字人情感风格方面做了一些探索。人在不同情绪下肢体表现是不一样的,所以我们提出了一个基于扩散模型的动作生成方法,可以根据音频生成风格化的肢体动作。
-05- 总结与挑战

最后进行总结与挑战:目前的挑战包括如何自动化构建影视级的3D超写实可驱动数字人形象,跨越恐怖谷效应;其次,如何生成丰富的情感协同表达?目前可以生成带情感的表情、肢体,那么如何能使它们都情感一致进行表达,目前还是一个难点;
另外,数字人不同肢体规范的动作和语义内容如何匹配、动作迁移时如何避免身体穿模也是一个很大的挑战;最后,如何让数字人具备多模态交互的能力,在对话过程中同时考虑多种模态信息,也是一个亟待探索的领域。
我的分享就到这里,谢谢!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
