
本文提出了一种结合自回归、层次化以及组合先验的方案,并权衡他们的成本与效益。众所周知,自回归模型会带来显著的计算代价,但我们发现在压缩性能方面,自回归和分层先验是互补的,而且共同利用潜变量中的概率结构,相结合即可产生最优秀的的速率-失真性能。
作者: David Minnen, Johannes Ballé, George Toderici
题目: Joint Autoregressive and Hierarchical Priors for Learned Image Compression
来源: https://doi.org/10.48550/arXiv.1809.02736
内容整理: 何朱萱
简介
近期的基于学习的有损图像压缩方法大都使用了基于变换编码的技术,其将像素数据转换为量化的潜像表示,然后对潜像进行无损压缩。在深度学习研究中,通常采用卷积神经网络(CNNs)作为变换器,因为它可以将像素映射到比线性网络更可压缩的潜空间。这种方法类似于自动编码器,由编码器和解码器组成。编码器将数据映射到潜在空间,解码器将潜像映射回数据。为了提高压缩性能,模型部分收到了关注,并结合熵模型和标准熵编码算法,生成压缩比特流。训练的目标是最小化比特流的预期长度以及重建图像相对于原始图像的失真,从而产生一个速率失真优化问题:

本文基于高斯尺度混合模型(GSM)的熵模型[1]进行了拓展,将分层GSM模型推广为高斯混合模型,并加入了自回归成分。 通过这些扩展,熵模型能够实现空间自适应和图像相关的建模,从而提高了压缩性能。
模型细节
图1呈现了本文提出的压缩模型,该模型包含两个主要子网络。第一个子网络是核心自编码器,它能够将图像量化映射至潜在空间(编码器和解码器)。第二个子网络负责学习用于熵编码的量化潜在空间的概率模型。它结合了上下文模型(针对潜变量的自回归模型)和超网络(超编码器和超解码器),超网络用于学习表示对纠正基于上下文的预测有用的信息。这些数据通过熵参数网络进行合并,生成条件高斯熵模型的均值和尺度参数。
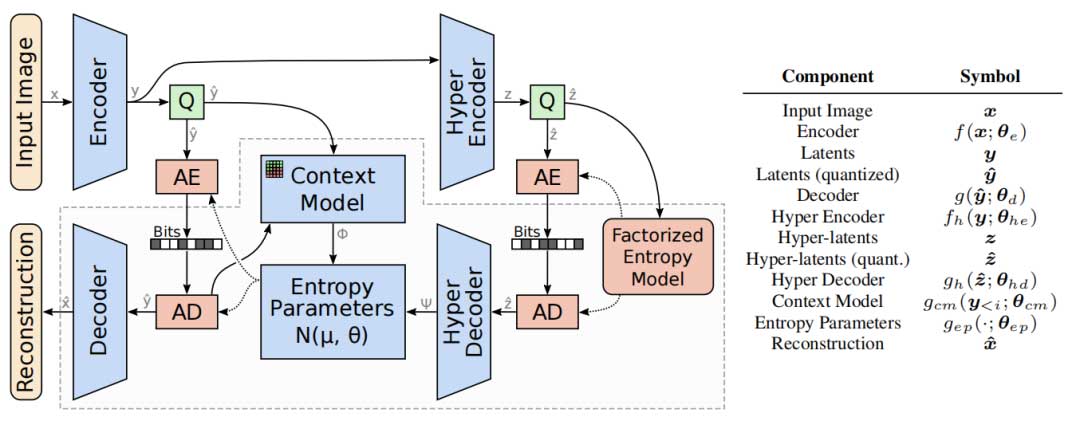
深度学习的目的是最小化方程中定义的率失真损失。由于本文拓展了模型,所以高斯分布的尺度不仅以超先验为条件,还以每个潜变量的因果上下文为条件。所预测的高斯分布参数是超解码器、上下文模型和熵参数网络的学习参数的函数(分别记为θhd、θcm、θep):
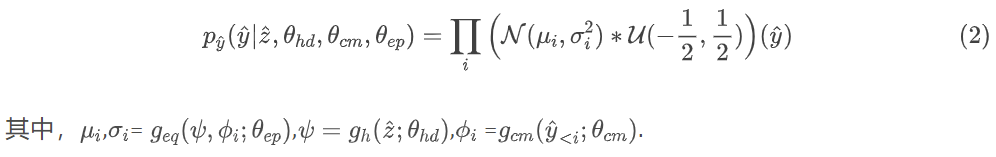
本模型中,超编码器和超解码器与自回归网络一起用于预测熵模型参数,由于对超潜变量的分布没有任何假设,因此使用了非参数化、完全分解的密度模型,对于超潜变量来说,更强大的熵模型可能会提高压缩率,因此从方程中得出的速率-失真损失必须扩展。所以完整损失函数为:
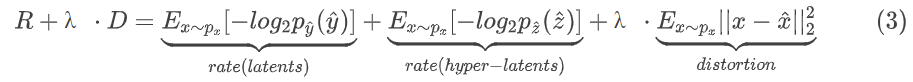
表1是各网络层的详细信息:

实验结果
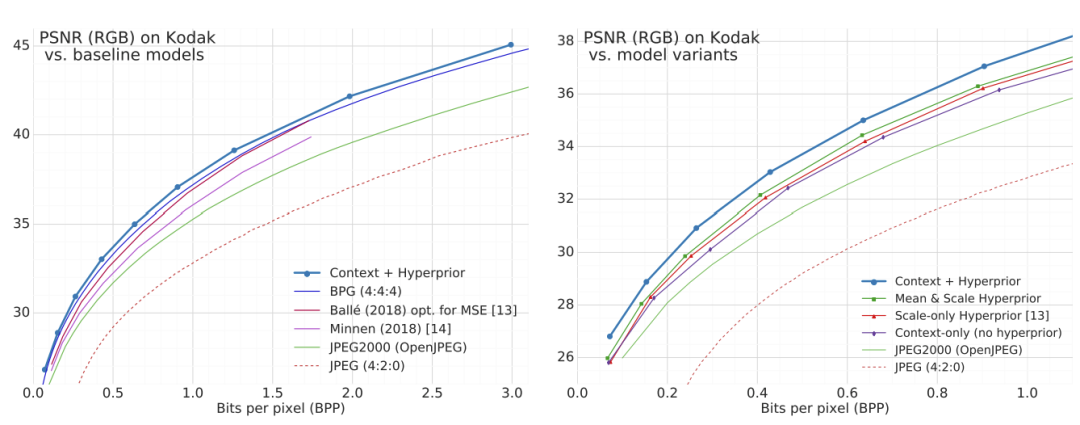
使用PSNR作为度量
使用 MS-SSIM (RGB)作为度量:
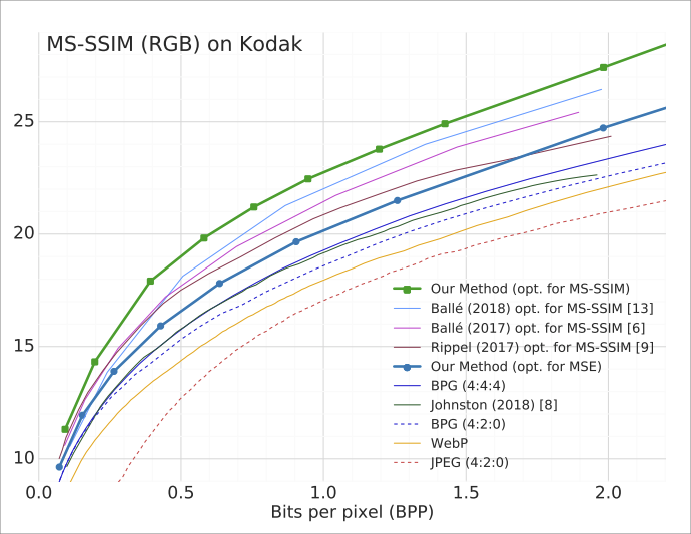
在相似的比特率下,我们的组合方法提供了最高的视觉质量。

讨论
本文模型在balle的方案之上[1]进行了两方面的扩展。一方面是将通用的高斯尺度混合模型(GSM)推广为条件高斯混合模型(GMM),在超先验的条件下生成均值和尺度参数。另一方面是将自回归模型与超先验相结合。从超先验的角度来看,结合后能够有更多的信息来改进熵模型,而自回归模型能够消除一些不确定性。结果显示,本文的方法有效改进了压缩模型的性能,产生的图像质量比起自回归模型的VAE模型更高。且有条件独立的潜变量使自回归模型的性能得到显著提升。
然而,由于自回归模型是串行的,且无法通过并行化等技术加速,故为了报告包含自回归组件的压缩模型的性能,作者并未实现完整的解码器,而是选择与Shannon熵进行比较,测量值在算术编码生成的位流大小的百分之一以内。
串行性这一性质导致此模型无法应用于压缩领域。为了解决这个问题,本文提出的探索方向是研究更轻量级的上下文模型,并考虑更多技术来减少上下文模型的计算需求和熵参数网络,如工程上紧密集成的算术解码器与可微的自回归模型。另一个可能的研究方向是通过在严格的层次先验中引入更多的复杂性来完全避免因果关系问题。
引用
[1]https://openreview.net/forum?id=rkcQFMZRb
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
