
近日,清华大学语音和语言技术团队联合北京邮电大学发布了中国明星多场景音视频多模态数据集 (CN-Celeb-AV),供音视频多模态身份识别 (AVPR) 等领域的研究者使用。本数据集包含来自1,136名中国明星,超过419,000个视频片段,涵盖11种不同的场景,并提供了完备模态和非完备模态两套标准评测集。研究者可以在共享资源网站 http://cnceleb.org 搜索 CN-Celeb-AV 免费申请下载。
背景介绍
生物识别技术是一项自动化测量和分析人体生物特征来认证个人身份的技术。声纹和人脸是最受欢迎的两类生物特征,其主要原因在于它们可以在远程和非接触条件下采集获得。在过去的几年中,随着深度学习的出现和大数据的积累,这两种生物识别技术,即说话人识别和人脸识别,性能得到了显著提升,涌现了广泛的应用。
尽管取得了令人瞩目的进展,无论是声纹识别还是人脸识别都面临着各自的实际困难。对于基于音频的声纹识别,挑战在于内容变化、信道差异、背景噪声、话者说话风格甚至生理状态变化等。对于基于视频的人脸识别,挑战来自光照变化、位置变动、未知遮挡等。
为了克服单一模态的性能上限,一个直观的想法是整合音频和视觉模态的互补信息,构建一个音频-视觉多模态身份识别 (AVPR) 系统。特别是在复杂的实际应用场景下,该系统应该会更加稳健。为了回答这个想法,NIST 在 SRE 2019 上发起了音频-视觉多模态身份识别挑战赛道[1],并在 SRE 2021 中继续跟进[2]。现有的 AVPR 研究大都采用了两种方法:表征融合与联合建模。尽管这些研究都取得了不错的结果,但是其训练和评测数据场景单一、相对受限,难以反映真实应用中的复杂性,例如在真实应用中,时常会出现某个模态信息被破坏或丢失的情况。
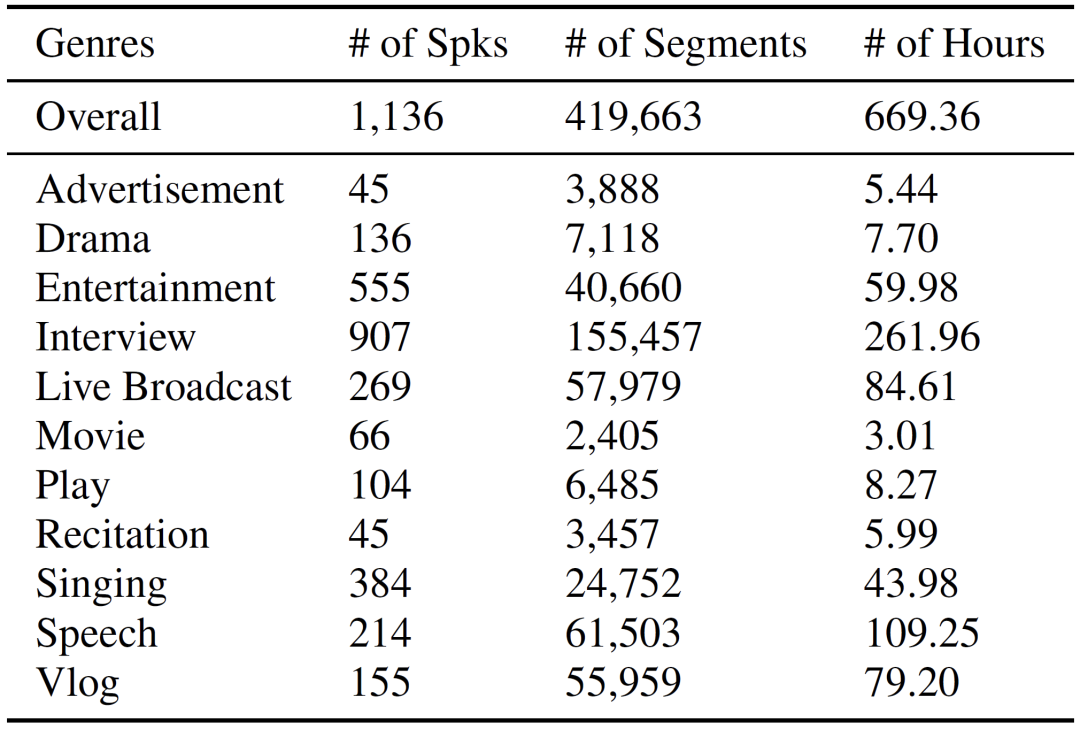
为了促进复杂应用场景下的 AVPR 研究,我们发布了一个名为 CN-Celeb-AV 的全新 AVPR 数据集。该数据集的采集流程遵循 CN-Celeb 的原则[3,4],包含了音频和视觉两种模态数据。整个数据集包括两大部分:“完备模态”部分和“非完备模态”部分。整个数据集涵盖了真实世界中的11种场景,包含来自1,136个人 (中国名人、视频博主和业余爱好者) 的超过419,000个视频片段。我们希望 CN-Celeb-AV 能够成为一个适用于具有真实世界复杂性的 AVPR 基准评测集。
数据特点
CN-Celeb-AV 拥有多种理想特性,使其适用于 AVPR 研究以应对真实世界的挑战。
1. 真实不确定性:几乎所有视频片段都夹杂着真实世界的不确定性。音频中的内容、噪声、信道、多人、说话风格变化等;人脸中的姿势、光照、表情、分辨率、遮挡等。
2. 多场景单说话人:包含大量的单一说话人多个场景的数据,可用于跨场景、跨会话测试,更贴近真实世界的应用。
3. 模态非完备性:在一些视频片段中,只有部分模态信息是完备的、可观测的,存在模态缺失情形,使其适用于评测 AVPR 系统在真实复杂条件下的性能,这也是多模态技术预期能发挥最大价值的情形。
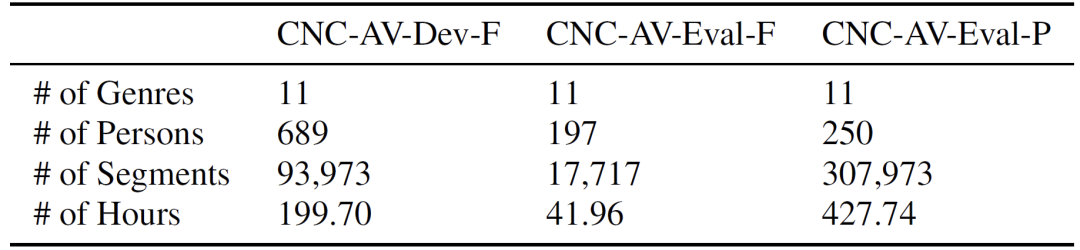
CN-Celeb-AV 共设有两个基准评测集:
1. “完备模态”评测集 CNC-AV-Eval-F:大多数音视频片段包含了完整的音频信息和视频信息。
2. “非完备模态”评测集 CNC-AV-Eval-P:包含了大量音频或视频信息损坏或完全丢失的音视频片段。例如,目标人物的面部和/或声音可能会短暂消失,被噪声损坏,甚至完全不可用。
初步验证
我们使用开源的声纹识别模型 ECAPA-TDNN 和人脸检测模型 RetinaFace 与人脸识别模型 InsightFace 在 MOBIO [5]、VoxCeleb [6] 以及 CN-Celeb-AV 评测集上开展了一系列对比实验。实验结果如下表3所示。
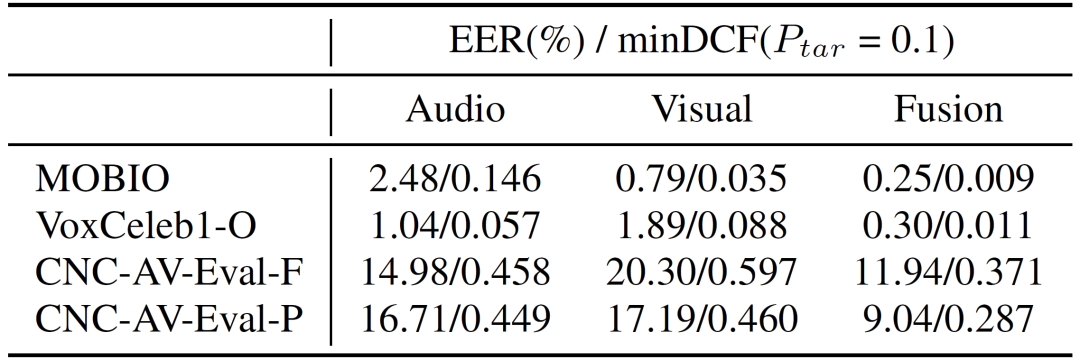
首先,在 MOBIO 和 VoxCeleb1 评测集上,单模态和多模态系统都取得了良好的性能。这是可以预期的,原因在于这两个数据集中的模态信息几乎都是完整的。相比之下,在两个 CNC-AV-Eval 评测集上,音频和视觉模态的性能要差得多,其主要原因在于 CNC-AV-Eval 中的数据更加复杂。这表明无论是音频还是视觉,当前主流的身份识别技术还难以应对真实世界中的复杂性。
其次,在所有评测集上,多模态系统的性能一致地优于单模态系统,凸显了多模态信息的优势。然而,即便如此,多模态系统在两个 CNC-AV-Eval 评测集上的性能仍然很差,这表明复杂场景下的多模态身份识别还需要进一步的研究。
资源下载
- 论文地址
- https://arxiv.org/abs/2305.16049
- 数据申请
- http://cnceleb.org/
- 采集工具
- https://github.com/smile-struggler/CN-Celeb3_collector
- 基线系统
- https://gitlab.com/csltstu/sunine/-/tree/cncav/
参考文献
[1] S. O. Sadjadi, C. S. Greenberg, E. Singer, D. A. Reynolds et al., “The 2019 NIST audio-visual speaker recognition evaluation,” in Odyssey, 2020, pp. 259–265.
[2] S. O. Sadjadi, C. Greenberg, E. Singer, L. Mason, and D. Reynolds, “The 2021 NIST speaker recognition evaluation,” arXiv preprint arXiv:2204.10242, 2022.
[3] L. Li, R. Liu, J. Kang, Y. Fan, H. Cui, Y. Cai, R. Vipperla, T. F. Zheng, and D. Wang, “CN-Celeb: multi-genre speaker recognition,” Speech Communication, vol. 137, pp. 77–91, 2022.
[4] Fan, J. Kang, L. Li, D. Wang et al., “CN-Celeb: a challenging Chinese speaker recognition dataset,” in ICASSP. IEEE, 2020, pp. 7604–7608.
[5] C. McCool, S. Marcel, A. Hadid, M. Pietikainen ¨ et al., “Bi-modal person recognition on a mobile phone: using mobile phone data,” in ICMEW. IEEE, 2012, pp. 635–640.
[6] A. Nagrani, J. S. Chung, and A. Zisserman, “VoxCeleb: A largescale speaker identification dataset,” in INTERSPEECH, 2017, pp. 2616–2620.
作者TINA
来源:清语赋
原文:https://mp.weixin.qq.com/s/IZpvYKM5H7l3cRB7aCQ12Q
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
