
大多数现有的学习图像压缩方法是基于 CNN 或基于 Transformer 的,它们具有不同的优势。如何有效的利用这两种方法的不同优势是一个值得探索的方向,而这面临着两个挑战:一是如何有效地融合这两种方法,二是如何在适当的复杂度下实现更高的性能。为此,本文提出了一种融合了Transformer 和 CNN 的混合结构(TCM),并将swin-transformer的注意力模块(SWAtten)引入了通道熵编码中,提升了模型的率失真性能。
题目:Learned Image Compression with Mixed Transformer-CNN Architecture
作者:Jinming Liu, Heming Sun, Jiro Katto
论文来源:https://arxiv.org/abs/2303.14978
代码链接:https://github.com/jmliu206/LIC_TCM
内容整理:李江川
引言
有损图像压缩在高效存储和传输方面发挥着重要作用,在过去的几十年里,出现了许多经典标准,如JPEG,VVC等。与这些经典标准不同,端到端的学习图像压缩是整体优化的,它们在峰值信噪比(PSNR)和多尺度结构相似性(MS-SSIM)方面都优于现有的图像编码标准。这表明学习图像压缩在下一代图像压缩技术中具有巨大的潜力。
现有的学习图像压缩方法都是单独使用CNN或者Transformer的。CNN具有局部建模的能力,而 Transformer 具有对非局部信息建模的能力。这两种方法的优点能否在适当的复杂度下有效地结合起来,仍然值得探索。本文试图在可控的复杂度下提出一个有效的并行 Transformer-CNN 混合块(TCM)来有效地结合 CNN 和 Transformer 的优点,以提高学习图像压缩的率失真性能。
除了网络结构的类型外,熵模型的设计也是学习图像压缩中的一项重要内容。最常见的方法是引入额外的潜在变量作为超先验,将紧凑编码符号的概率模型转换为联合模型。同时,会将图片和潜在变量划分为不同的切片,而注意力模块可以帮助学习模型更多地关注复杂的区域,已编码切片的结果会辅助编码之后的切片。
注意力模块可以帮助模型更多地关注复杂的区域,这有利于改进图像压缩的性能。但这些注意力模块通常被放置在图像压缩网络的主路径和超先验路径中,这将引入较大的复杂度。为了解决这个问题,本文将注意力模块转移到信道熵模型中,这将使注意力模块的输入图像大小变为原来的十六分之一。同时,为了解决熵模型中切片数量的增加引起的输入图像通道数增多的问题,使用通道压缩来控制熵模型的整体复杂度。
大量的实验证明,本文提出的方法在三个不同分辨率的数据集(Kodak, Tecnick, CLIC Professional Validation)上均达到了SOTA。
模型
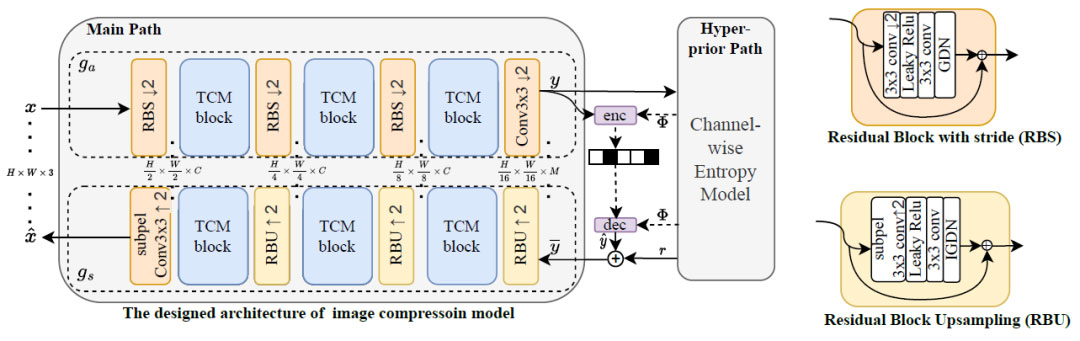

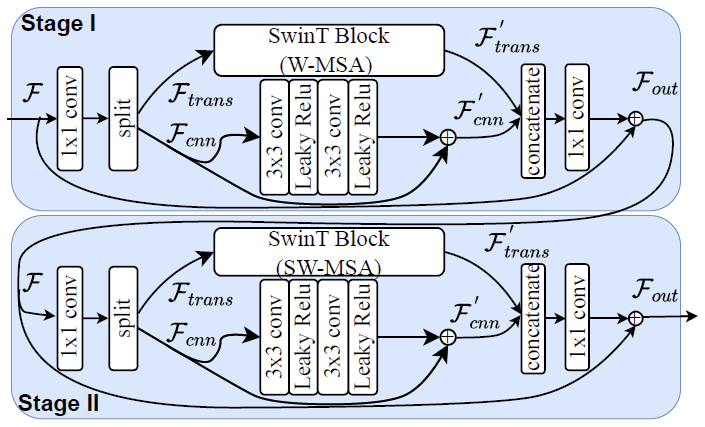
Transformer-CNN混合块

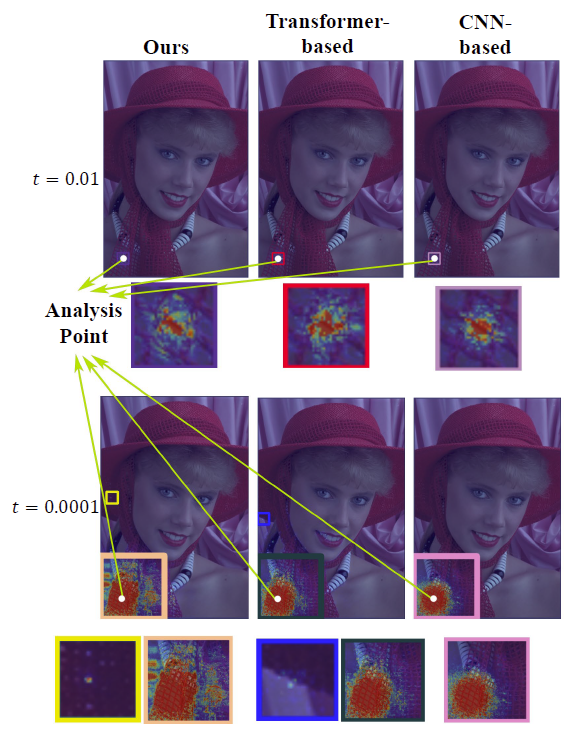
为了探索TCM块是如何聚集局部和非局部信息,本文可视化了模型的有效感受野(ERF),并和仅基于CNN的模型和仅基于Transformer的模型进行了对比。为了估计不同距离处信息的重要性,我们用两个阈值t(0.01和0.0001)来剪裁梯度,以使其可视化。意味着将大于阈值的梯度值减小到阈值,并且小于阈值的梯度数值保持不变,这可以让可视化具有更高的可见性精度。具体的可视化结果如下图3所示。当t=0.01时,模型的ERF更趋近于CNN模型,这表明模型更加关注相邻区域,并且具有与CNN相似的局部建模能力。同时,当t=0.0001时,模型的ERF和Transformer模型一样,在远离目标区域处仍然有梯度残余,这表明模型也具有远程建模能力。
通道熵模型
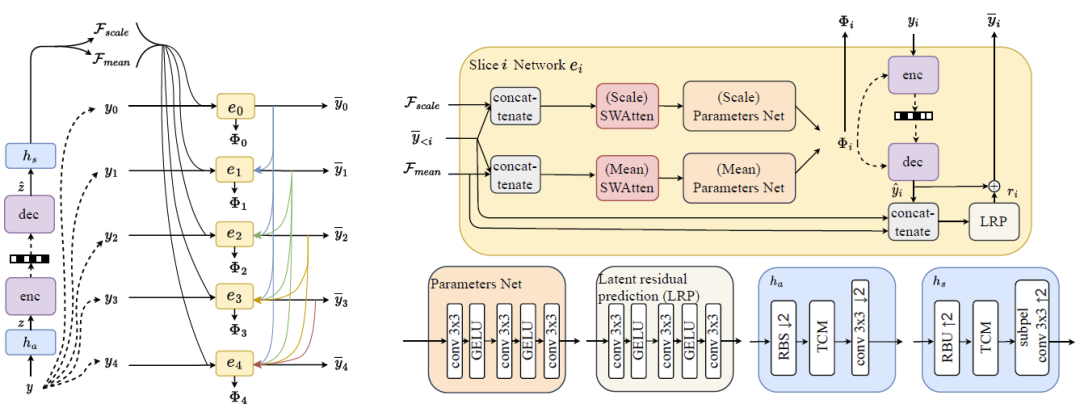

在通道熵模型中,为了提升模型的性能表现,同时控制模型的复杂度,设计了一个基于 Swin-Transformer 的,拥有通道压缩能力的 SWAtten 模块,该模块的具体结构如下图所示。SWAtten 模块位于切片网络中,输入张量的尺寸已经变为原始的 1/16。但由于已编码的切片会被输入到切片网络中,其面临着通道数增加的问题,这大大增加了该模块的参数量。因此,在张量输入到残差块和Transformer之前,会通过一个 1 x 1 的卷积将通道数固定为128,而注意力模块的输出也会通过一个 1 x 1 的卷积来恢复通道数。
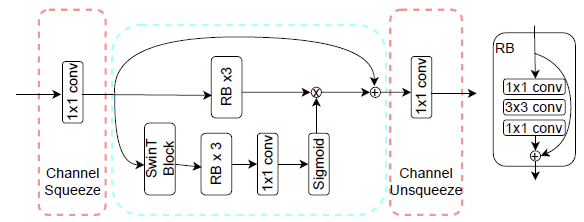

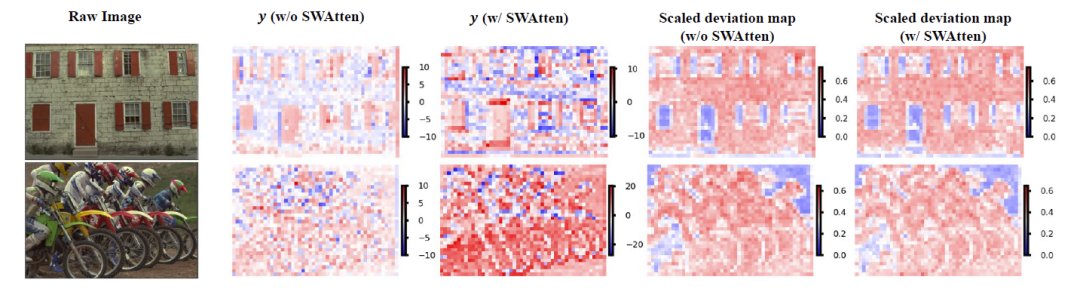
实验
本文测试使用的三个数据集分别为:Kodak(分辨率为 768 x 512),Tecnick(分辨率为 1200×1200)以及CLIC professional validation(分辨率为2K)。同时为了测试模型在不同复杂度下的性能,设计了三种不同尺寸的模型,这是通过改变主路径中的通道数来实现的。small,medium,large模型分别对应于 C = 128,192,256。
率失真性能与模型复杂度
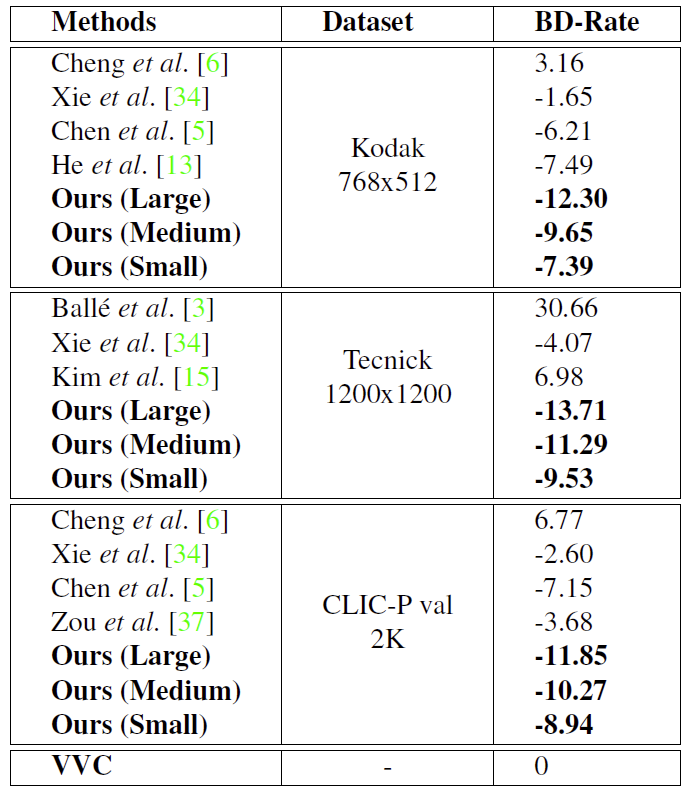
计算率失真时,以VVC的结果作为基准。具体结果如下表1所示。
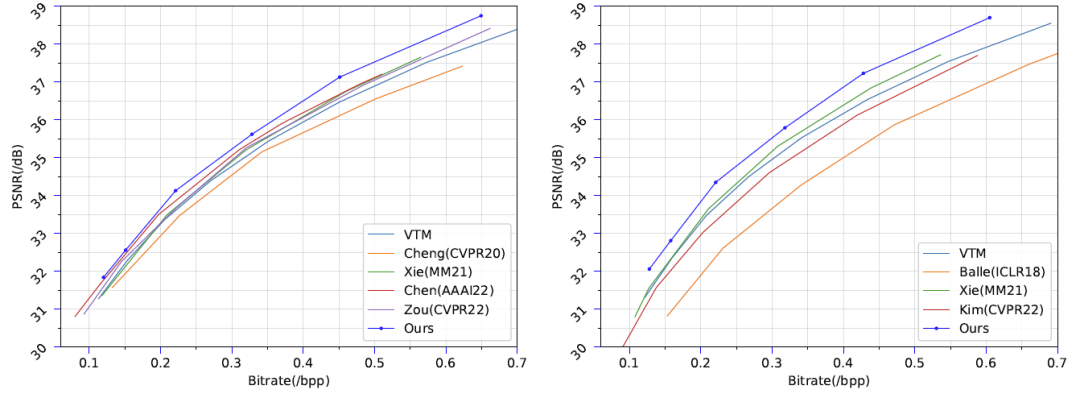
下图7展示了Kodak数据集上的性能对比。
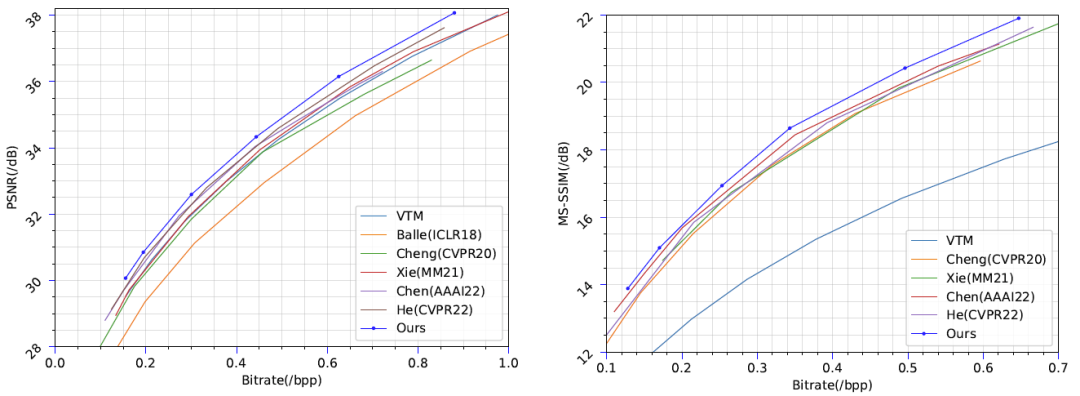
下图8展示了Tecnick和CLIC professional validation数据集上的性能对比。(左图为CLIC,右图为Tecnick)
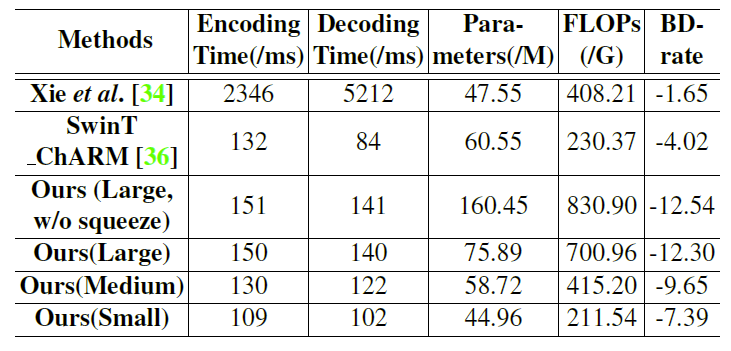
下表2展示了在Kodak数据集上,不同模型的编解码时间和复杂度大小。(测试基准为一块RTX 3090)
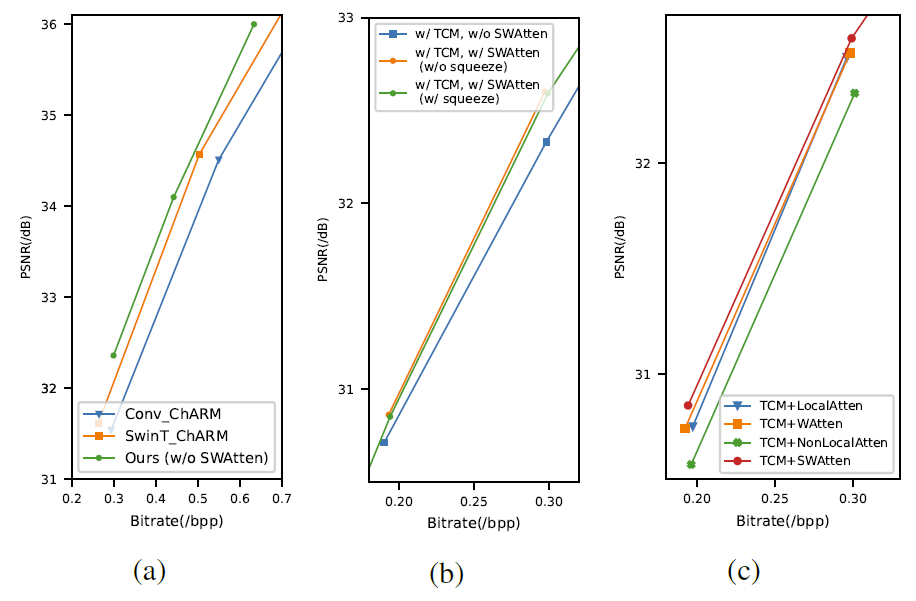
消融实验
下图9展示了不同消融实验下,模型性能的对比。图(a)是证明 TCM 模块有效性的实验,为了保持不同模型之间的一致性,而没有使用 SWAtten 模块。图(b)是证明 SWAtten 模块的有效性,从图中可以看出通道压缩使用与否,模型的性能表现是相近的,但模型的参数量差距极大。图(c)对比了使用不同注意力模块时的性能表现。
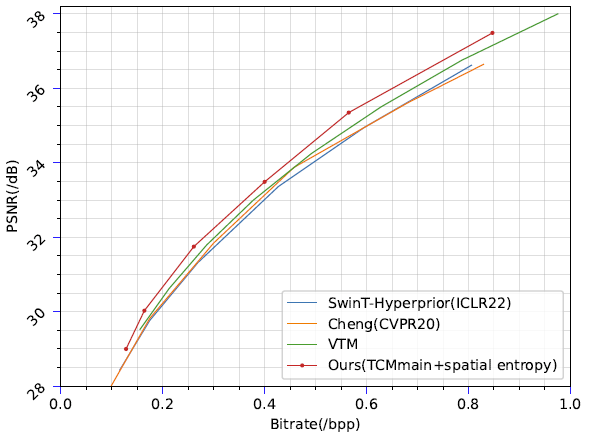
下图10展示了,将通道熵模型替换为空间熵模型后,使用不同主路径的模型的性能对比。
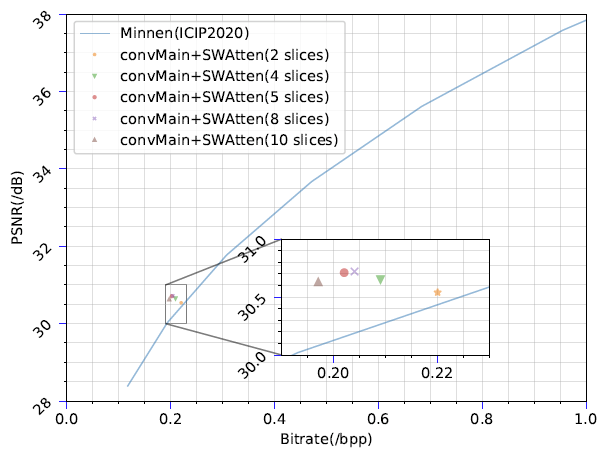
下图11展示了在通道熵模型中,不同切片划分数对模型性能的影响。
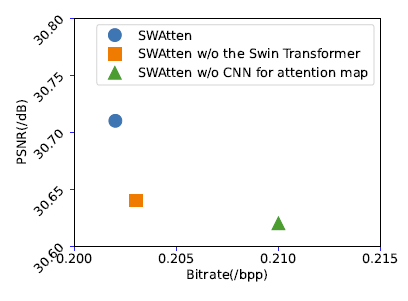
下图12展示了在SWAtten模块中,除去CNN网络或者Transformer网络后的性能对比。
结论
本文将 Transformer 和 CNN 结合起来,提出了一种有效的并行 Transformer-CNN 混合块。该块利用了 CNN 的局部建模能力和 Transformer 的非局部建模能力。然后,基于TCM块设计了一种新的图像压缩结构。此外,此文提出了一个基于 Swin-Transformer 的注意力模块来改进通道熵模型。实验结果表明,在适当的复杂度下,具有TCM块的图像压缩模型优于仅基于 CNN/Transformer 的模型。此外,SWAtten 的性能超过了以前为图像压缩设计的注意力模块。最后,本文的方法在三个不同分辨率的数据集上达到了 SOTA,并且优于现有的图像压缩方法。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
