
一 幻星数字人简介
幻星数字人是天工制作部联合人工智能平台部虚拟人算法组打造的3D数字人解决方案,主要由工业化数字人智能生成管线+AI驱动的表情与动作捕捉系统两部分构成。如上图所示,渲染风格涵盖卡通/游戏CG/古风/超写实等,能够兼容市面上大部分主流审美。目前支持的上游业务包括3D数字人直播,虚实融合的内容创作投稿,平台级用户虚拟形象专项,3D虚拟礼物,3D虚拟偶像IP孵化等。行业中对标的竞品包括网易伏羲虚拟人平台,百度希壤数字人平台,腾讯超级QQ秀,快手KVS虚拟演播助手等。
幻星数字人整体的技术思路是依托UE/Unity等头部商业引擎工具链和渲染架构,针对业务需求进行源码级别的二次开发与平台化改造,实现跨平台多模态的数字人内容制作方案。目标有两个:一是降低内外部PGC创作者在虚拟制作方向上的成本和门槛,提供更高效的上下游工具链和丰富的资产模板。二是逐步向UGC内容方向进行渗透,以“为B站每个用户提供一个虚拟形象“为切入点,撬动用户在虚拟世界进行自我展示,内容表达的欲望,从而拉动虚拟内容在供给侧的效能,为整体的虚拟生态带来消费增量。
本文将重点介绍人资产生成管线的技术方案与细节,着重分享真实感渲染,角色个性化定制,物理仿真等行业难点问题在幻星侧的解决思路。也非常欢迎各位前来建联沟通,业务合作和技术交流。
二 打造具有行业竞争力的实时虚拟角色制作管线
1 兼顾品质与性能的虚拟人渲染系统
1.1 真实感渲染
1.1.1 三千烦恼丝,一丝胜一丝-虚拟人头发渲染的技术方案
头发渲染面临的技术挑战主要分为几何结构和光照阴影两部分:
- 几何结构:真实人体的发丝一般有10w根左右,并且头发是弯曲的,如果完全按照真实发丝一比一还原,所需要的顶点数是海量的,不管是从资源制作上,还是实时渲染都不可能负担的起。市面上的主流游戏通常采用hair card模型加上透明贴图的方式来模拟发丝。
- 光照阴影:真实世界中,一根发丝上的不同部位受到光的影响不同,每根发丝间也并不是独立的,发丝间互相遮挡影响,互相交错造成了复杂的光学现象,从而使得我们无法用一个单一准确的物理模型进行模拟从而得到较好的效果。
目前行业中相对比较成熟的写实发型建模方案主要分为两种:一种是传统3A游戏中大量使用的基于头发插片的Hair Card模型,典型案例如《最后生还者》《神秘海域4》等,在低配机器或移动端上,该方案会进一步退化成纯Mesh模型,以降低渲染开销。另一种是近几年随着软硬件性能不断提升,各大厂商基于发丝发束的Strand-Based模型,提供更好的物理效果和光影视效,典型案例如AMD的TressFx, Nvidia的HairWorks,UE5的Groom方案等。下图结合幻星虚拟人的具体业务需求,对这两类方法进行三个维度的对比。
| Hair Card/Mesh | Strand-Based Hair | |
| 模型制作 | 限制大,造型不能太过复杂卷曲,否则计算出的光照分布杂乱。制作工艺繁琐费时,容易出错,需要处理每片头发的前后位置关系、透明贴图的发丝粗细、模型布线平整等。 | 无限制,头发以strand为单位进行建模。制作方便,头发以strand为单位进行建模,这种建模方式正是美术同学在建模软件中制作头发的第一步工序,同时还省去后面制作hair card的时间消耗。 |
| 光影效果 | 较粗糙,比如光照缺少真实头发蓬松的质感,发丝较粗,如果采用透明剔除方式则边缘会很粗糙,如果采用半透明方式又会有排序问题。使用比较简单的渲染模型,复杂效果无法表现。 | 渲染逼真度高,方便基于发束进行剔除,更细的发丝,能够更好的表现头发间复杂的光照交互。 |
| 性能 | 性能较好,对硬件要求低,普通电脑可流畅运行移动设备上退化成Mesh方案,常见于主流角色扮演类手游中 | 硬件设备要求高,渲染开销较大,资源占用高 |
下图可以直观对比Hair Mesh 和 Strand Based两种方式下的初始头发模型形态。

在数字人直播领域,特别是移动直播间/PC游戏直播间等场景,对性能有较高要求,我们采用以Hair Mesh为主的降级策略来进行模型制作。而在虚拟偶像,虚实融合的投稿视频制作中,为了提升效果表现,幻星虚拟人则是围绕Strand-Based方案打造了对应的升级方案。下文将分别详细介绍两种方案的着色步骤与技术细节。
Strand-Based 头发渲染


目前写实方向上,行业里主流的渲染方案是基于PBR(Physically-Based Rendering)着色模型来构建的,用来渲染场景,道具,衣服等常规物体是游刃有余的。但在基于发束的人物头发模型上,由于特殊的物理结构,通用方案无法获得较高的渲染质量,如上左图所示,硬边,高光不成型,缺乏立体感等问题非常明显。经过对Frostbite在Siggraph19上分享的发束渲染方案的研究,我们引入了新的渲染流程,如上右图所示,在光影层次和立体感上有了较大的提升。那么我们是如何一步步优化成上图的究极形态呢?为了解决这个问题,我们先要理解真实头发的物理结构。
理解真实头发物理结构
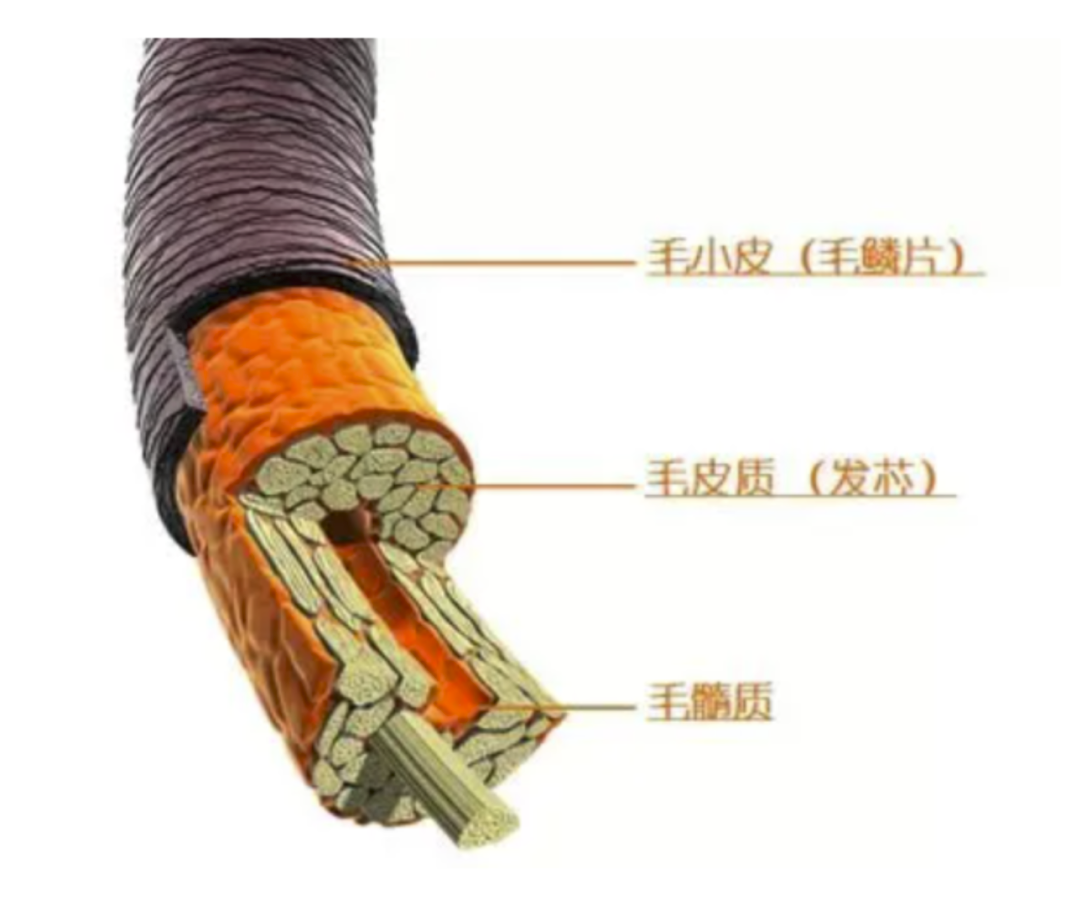
毛小皮:毛表皮的最外层结构,由扁平细胞交错,呈鱼鳞片状,从毛根排列到毛梢,包裹着内部的皮质。
毛皮质:毛皮质占毛发成分的75%至90%,由柔软的角蛋白构成,对头发受光表现有着比较大的贡献。
毛髓质:位于头发的中心,细胞集合体以一至二并排呈立方体的蜂窝状排列着,内部是空心的空状结构。和毛皮质一起影响了头发的散射、透射效果。
通过对头发真实构造进行观察,我们发现造成头发像稻草的主要原因有二。
首先在于传统的头发渲染方式,只考虑到了表层的反射,而忽略了光线在皮质层中的散射和光线与多根头发间交互的复杂形态。
并且一根发丝往往小于一个像素,且有多根头发堆叠在同一个像素中的情况。如果直接通过传统的光栅化填充像素,则会造成头发过硬。
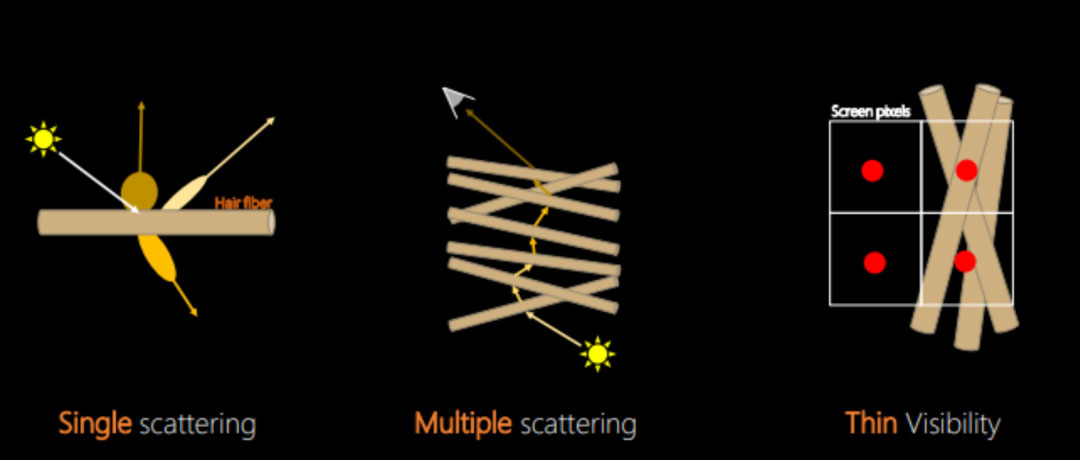
因此,针对这些问题,我们采用了更贴近头发真实构造的物理建模,将头发渲染拆成了单次散射、多重散射和可见性计算三个部分,下文会分别介绍各部分的具体实现。
发束光照着色的主要步骤
发束光照计算主要分为下图所示的三个步骤:单次散射->多重散射->可见性计算
仅描述单根发丝受光照的影响,不考虑头发间的相互作用。常用的是Marschner Model,模拟了头发在远距离下的观察效果,没法很好的模拟近距离下的发丝。


从上图对比可以看出,单次散射的效果明显比PBR更具有头发的质感。
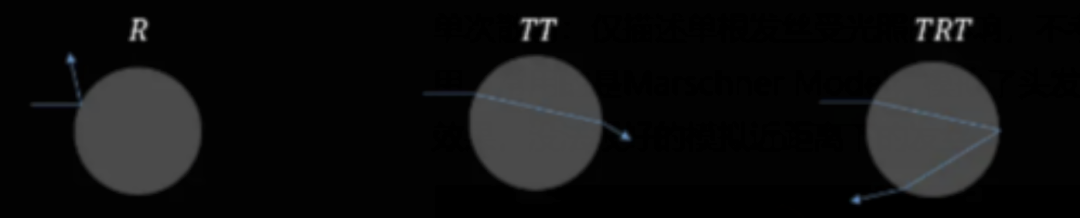
单次散射通常按光路拆成3部分进行独立计算,最后结合成最终的渲染效果。
- R(Reflective)表示光直接照射到毛鳞片微表面上后,立即反射出去这一路径。
- TT(Transmissive)表示光进入头发内部后,有一部分被吸收,剩下的部分直接从另一边穿过发丝的光路。(皮质、髓质统一看成一种散射介质)
- TRT则表示光照进入发丝介质发生一次折射后,在内壁进行了一次反射,最后又再次折射出发丝这一路径。
由于性能原因,光照在近似圆柱的发丝上,可拆成沿着发丝生长方向(M项)和发丝圆周方向(N项)的乘积,通过头发表面粗糙度、吸收因子以及头皮倾斜角度作为影响因子来计算。
其中N项的TT路径分布函数通过一张LUT图做了近一步的简化。

多重散射

多重散射增加了光线在多个发丝之间的相互作用。通过上图对比单次散射和多重散射的效果可以看出,右图的多重散射提升了头发颜色饱和度,还原了更真实的光影层次,提升了头发整体的立体感。
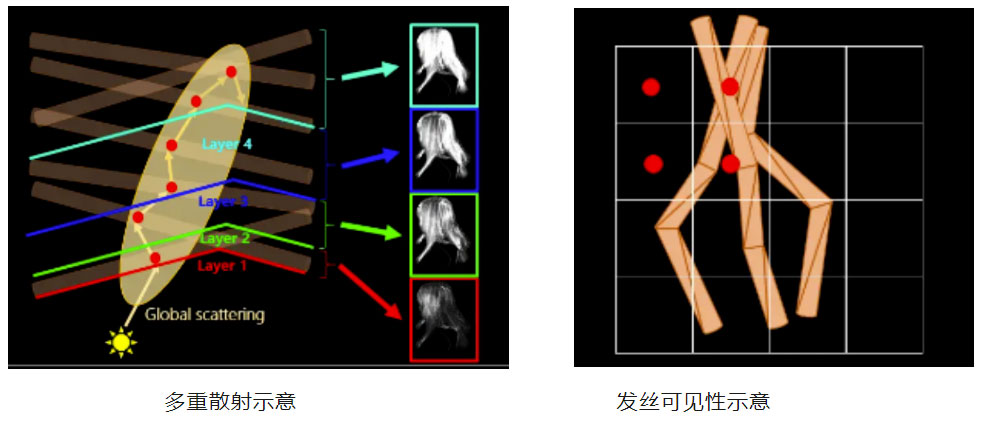
多重散射的核心思路是采用局部散射+全局散射来实现对多次散射的模拟。局部散射只需要渲染点附近区域参与计算,而全局散射要通过考虑沿着光照方向或者阴影方向来计算散射,因此需要一种沿着光线方向计算头发厚度的方法。这里采用了Deep Opacity Maps,通过深度对头发进行切片,每片分别生成一张阴影贴图,最终来计算光照透射、衰减等效果。
发丝可见性
我们根据Mesh和Strand-Based特性,采用不同的可见性计算策略。
Strand-Based
Strand-Based由于发丝细,小于一个像素,且发丝间有大量叠加区域,如果采用传统的处理方式,在发丝tessellation时输出的面片宽度提升到pixel-size,就会看起来特别粗糙,像干草一样。
这里通过引入Visibility-Buffer的方式进行优化。
V-buffer不同于延迟渲染的G-buffer,它在灯光屏幕空间像素点内,存储了实际场景发丝信息的地址,通过地址映射到一个发丝数据结构上,这个结构可以通过V-buffer里的场景地址索引到,因此就可以得到当前这个像素实际上所有发丝的信息,比如发丝的数量、深度、透明度、覆盖在后边的发丝地址,结合这些信息可相对正确的计算出发丝的可见性。
Hair Mesh
Hair mesh则有两种方式来优化头发模型层次的可见性,分别是透明剔除和半透渲染
透明剔除
通过透明贴图mask,结合alpha test来剔除,其中有两问题需要解决。
- alpha test直接截断某一阈值的透明度,使得原本连续的图像变得离散,产生大量噪点。
- alpha test边缘过硬和粗糙,发丝看起来像稻草。
为了解决上述两问题,我们通过引入一系列技术组合拳来平滑发丝边缘和降噪。
- 图像领域的Dithering降噪技术,通过给采用的透明通道叠加一张蓝噪声贴图进行空间上的抖动
- 通过Alpha to coverage平滑边缘
- 通过TSR(Temporal Super Resolution)进行时间上的抖动
- 通过后处理进一步对边缘进行平滑


半透明渲染
半透明头发渲染最大的挑战是如何正确的进行排序,我们尝试了以下两种方式来解决该问题。
- 通过将头发分成内外层,其中内层采用alpha test渲染,外层采用半透明渲染。内层要求头发制作工艺上不允许出现很细的发丝,发丝全部放在外层,并且外层发丝间不能交错。外层通过先独立绘制一次深度,通过比较深度信息来剔除后边的发丝。
- 还是分内外层,内层和上一个方式一致,外层通过前后顺序关系,分层一个个小区域,每个区域有自己的id,实际渲染时,通过比较id包围盒中心点深度,来给发片排序,之后进行半透绘制。复杂头发往往要分20+层才能保证排序不出现明显的问题。
这两种处理方式的区别主要在美术制作流程上。前者半透是单层,美术制作时比较简单,往往用于不太复杂的头发造型,比如单层薄刘海波波头。后者半透是多层,制作时比较复杂,用于复杂多层的头发造型,比如多层卷大波浪。我们根据头发造型的复杂程度选择更适合的制作方案。
头发成型高光-天使环
在计算头发高光时,我们遇到下面的问题,可以很明显的看到头发高光分布不均匀,且高光太细。

CG风格需要我们呈现形状分布美观的高光,直接使用Marschner的反射层计算天使环形状的高光时,容易出现头发高光碎和乱的现象,为此我们使用了Kajiya模型来替换Marschner算法的高光计算部分。可以看到上右图是经过Kajiya算法计算的“天使环“高光区域。
那么如何估算正确的法线方向,以制作上图这种分布均匀美观的高光?Kajiya光照模型中将头发假设成光滑圆柱体,过副切线的起点并且与副切线和光线共面,可以找到唯一的一条法线,我们使用这条法线就可以计算出一个近似的高光。这样就解决了图中圆柱体法线朝向各异的问题。
为了使得高光规则有形状,我们还需要对头发面片制作工艺有要求。首先是设计上尽可能保证头发面片的完整且平滑,减少碎发和复杂造型,比如留出大片平顺刘海。之后在模型制作上,相邻片的布线尽可能连续,这样计算出的切线平整,高光规则。最重要的一点,在DCC软件中,为设计师提供和引擎中相同的头发高光环境,使得设计师在制作发片时就能所见即所得的调整面片来控制高光形状。
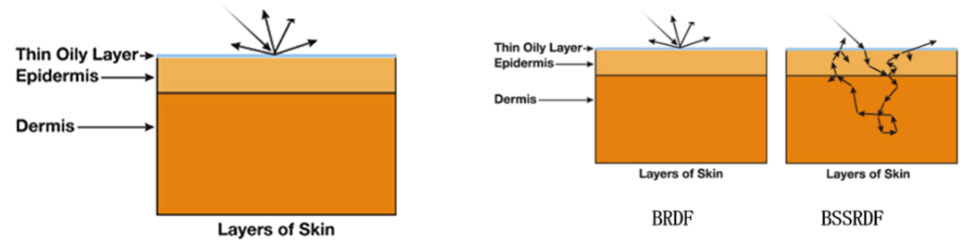
1.1.2 肤如凝脂 面如白玉-虚拟人皮肤渲染技术方案
皮肤的真实感渲染一直是人物渲染领域的难点之一。真实世界人体皮肤构造复杂,由绒毛、油脂、表皮、真皮以及其下各种血管、组织组成,且皮肤表面还包含了毛孔、油脂等许多微妙的视觉特征。人的视觉对脸部皮肤的细节非常敏感,质量较低的皮肤效果容易产生“恐怖谷“效应。此外,在实时渲染领域,除了追求渲染质量外,也需要考虑到平台算力的限制。因此,如何兼顾品质和性能是研发过程中的一大挑战。
方案初期,我们曾尝试使用通用PBR模型来直接渲染皮肤,如下左图所示,整体效果塑料质感明显,缺少皮肤的通透感。通过调研行业主流的次表面材质方案,我们采用了符合幻星数字人风格的SSP(Subsurface Profile)渲染方案,如下右图所示,在鼻尖,鼻翼,下颌线等关键脸部结构位置,皮肤的通透感和光泽度有较为明显的改善。下面我们将介绍实现的原理和细节。


渲染技术方案
首先,我们对皮肤的物理结构进一个简单的剖析。
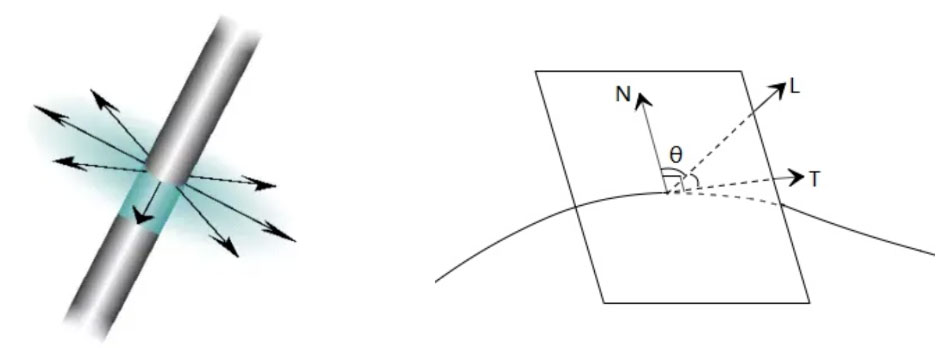
实验测试表明,皮肤表面油脂层主要贡献了反射部分(约6%的光线被反射),而油脂层下面的表皮层和真皮层则主要贡献了次表面散射部分(约94%的光线被散射)。如果没有了次表面散射部分,那么皮肤则过于生硬。对于皮肤来说,光线穿过油脂层进入表皮层和真皮层后,在其内部不断传播,散射到不同方向,其中一部分会再次穿过表面被观察到,这种现象称为次表面散射,最直观的解释就是光在皮肤表面反射的位置,和光实际的入射点位置不一样。
扩散剖面
那么,要怎么实现次表面的散射效果呢?我们引入扩散剖面来解决这一问题。扩散剖面(Diffusion Profile)是用来描述光线如何在半透明物体中进行扩散和分布的函数。相当于一个记录次表面散射细节的“地图”,通过这个“地图”我们就能快速的索引到周边像素需要使用什么程度的散射。
当我们假设皮肤材质各项均匀其散射行为和角度无关时,就可以用一个一维函数来描述。对于不同的材质RGB根据距离衰减的行为是不一样的。
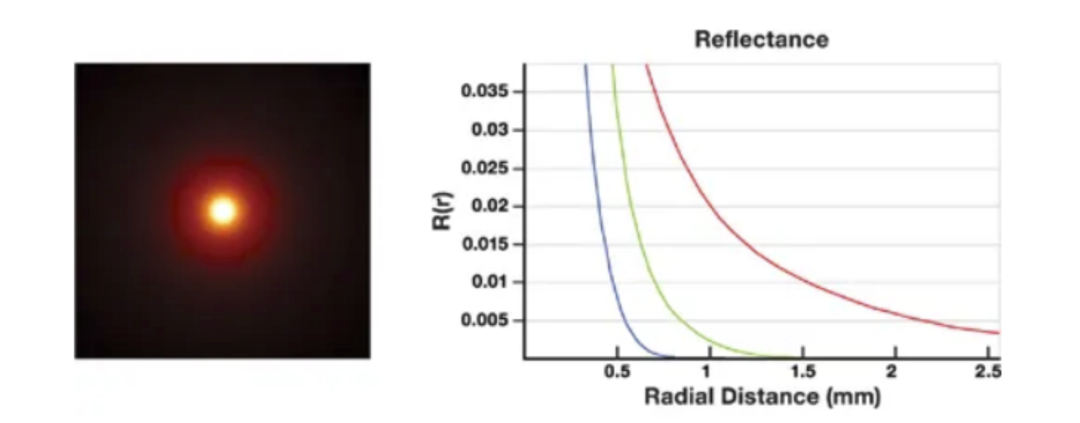
上图为在黑暗密闭空间中,使用白色薄激光束打到一个平坦表面时,产生的光晕效果。其中边缘光晕是红色的,由此我们可以发现每种颜色都有自己的剖面。
我们可以将其绘制成一维曲线,发现扩散剖面具有很强的颜色相关性:红光比绿色和蓝色散射得更远,而正因为红色扩散得更远一些,所以耳朵和鼻子的部位通常会更有红彤彤的感觉。
在计算次表面时,我们考虑下面两种部分。
- 计算漫反射:逐像素计算漫反射。
- 计算次表面:根据上一步漫反射的计算结果,结合扩散剖面定义的周围像素权重,加权计算周围像素对当前像素的次表面散射贡献。
皮肤渲染方法,通常就是对扩散剖面的不同近似。
- 偶极子:初期的Diffusion Profile使用的是偶极子来拟合计算的,但是偶极子只能表达单层材质,然而皮肤具有多层散射特性,轮廓的形状变得比偶极子所能表示的更复杂,如果仅用偶极子,皮肤效果就像开了重度磨皮一样,缺乏表面细节,因此有了后续的多极子。
- 多极子:多极子能够捕获广泛散射的真皮层顶部的薄的、窄散射的表皮层的组合反射率,在皮肤的表现力上往往能够在保留皮肤细节的同时达到更贴合真实皮肤的合理次表面散射程度。
- 高斯函数求和:由于高斯的可分离、可径项对称、可多个高斯相互卷积成新高斯的特性,相比多极子的方式能更有效率的求解出次表面特性。因此我们采用高斯和的方式来拟合扩散剖面。
高斯拟合
- 1个高斯函数可以很好拟合单散射效果,但无法拟合单散射+多散射
- 2个高斯函数可以勉强拟合单散射+多散射
- 6个高斯函数可以得到相当高精度的拟合效果
实验数据表面,结合皮肤真实构造进行建模,6个高斯函数结合可以得到相当高精度的拟合效果。
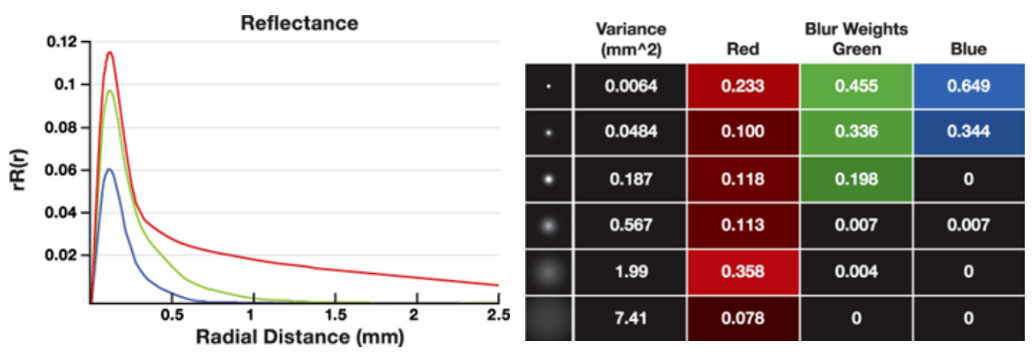
早期的实时3s(次表面散射)技术采用的是屏幕空间方法,针对上边列的6个高斯函数,需要12个pass来渲染,性能开销十分大。因此,针对这一问题,有两种解决方案。一种是可分离次表面散射技术(Separable Subsurface Scattering),俗名4s,还有一种是Pre-Integrated Skin(基于预积分的皮肤着色技术)。在PC平台的中低端设备上,我们主要以4S技术为主来简化计算,而针对移动端和web端,我们则考虑通过预积分的方法来进一步压缩计算开销。
可分离次表面散射

4s技术(可分离次表面散射),极大的优化了3s的效率。使得原先需要进行的6次高斯函数,12个pass的计算,压缩成了1个高斯函数,2个pass,将皮肤次表面渲染时间压缩到0.5ms内,我们在pc端选用的就是可分离次表面散射技术。
那么他是怎么压缩高斯函数的呢?先抛出个问题,根据高斯函数特性,1个2维高斯虽然可分离,但是6个2维高斯和却是不可分离的,除非使用6*2个1维卷积 Pass 但仍然十分耗性能。
基于上述问题,业界有几种解决方式:
- 基于SVD分解的可分一维卷积核:但是限制多,且也相对耗时
- 物理不准确,纯经验trick:分解为近距离散射和远距离散射两个部分,两个高斯函数先相加后相乘,相当于四个高斯函数单独作用再相加,问题是不物理且还是很耗时
- 引导函数:给每个位置增加了一个重要性系数,用户可自定义,但没有直接的物理意义,实现起来也比较耗时
- 预积分:对6个高斯和拟合成的函数,进行预先卷积(对距离的积分)得到一张一维表,使用时直接输入一个偏移值,就能得到该处位置的高斯权重。该方案耗时少,能够很好的还原真实物理皮肤,因此在计算4s时,推荐该方式进行,我们线上也是使用的这种方法
- 通过对实验观测分析得到的6个高斯和拟合成的精确的 diffusion profile,进行预积分,得到1个1维卷积核查找表。让时间复杂度从O(n^2)=>O(n)
- 通过偏移值得到查找表的高斯核,传参给shader,在shader中做高斯模糊。
- 高斯模糊时,先对diffuse color做一次横向卷积 Pass ,再经过一次纵向卷积Pass,就能得到2D维卷积的效果,最后再添加Specular color
(需要注意的是,如果不把高光拆开,代入模糊中则会出现星形异常高光现象)
通过该方案,设计同学可以通过调节ssp资源参数,来控制角色皮肤实际照明应该散射的距离、次表面颜色以及离开对象后照明的衰减色等效果。在一些算力比较充沛的机型上,我们引入Burley次表面散射模型,他在物理上更为精确,主要用于改善皮肤着色的质量。
Burley Normalized Diffusion
4s方案已经能够满足绝大多数效果品质需求了,但是他的拟合形态还和真实皮肤存在小误差,有没有什么方式可以更近一步的减少误差呢?
Burley于2018年提出了 Burley Normalized Diffusion方式来近一步拟合真实皮肤扩散剖面。该方案放弃物理,直接用纯数学(一个数学公式)的方法拟合 diffusion profile。
下面先上下两种方式的对比图,主要差别在于 Burley Normalized Diffusion方式更接近真实物理。可以看鼻头处差别,4s方式模糊过了,burley方式更清晰。

那么该方案具体是怎么做的呢?要从下面这个公式开始说起。
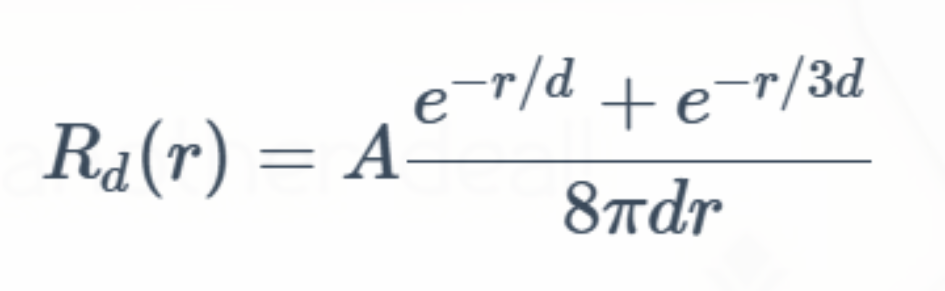
其中A 是 Surface Albedo(或者说单散射 Albedo),d 是用来控制这条曲线的参数,r则是距离半径。
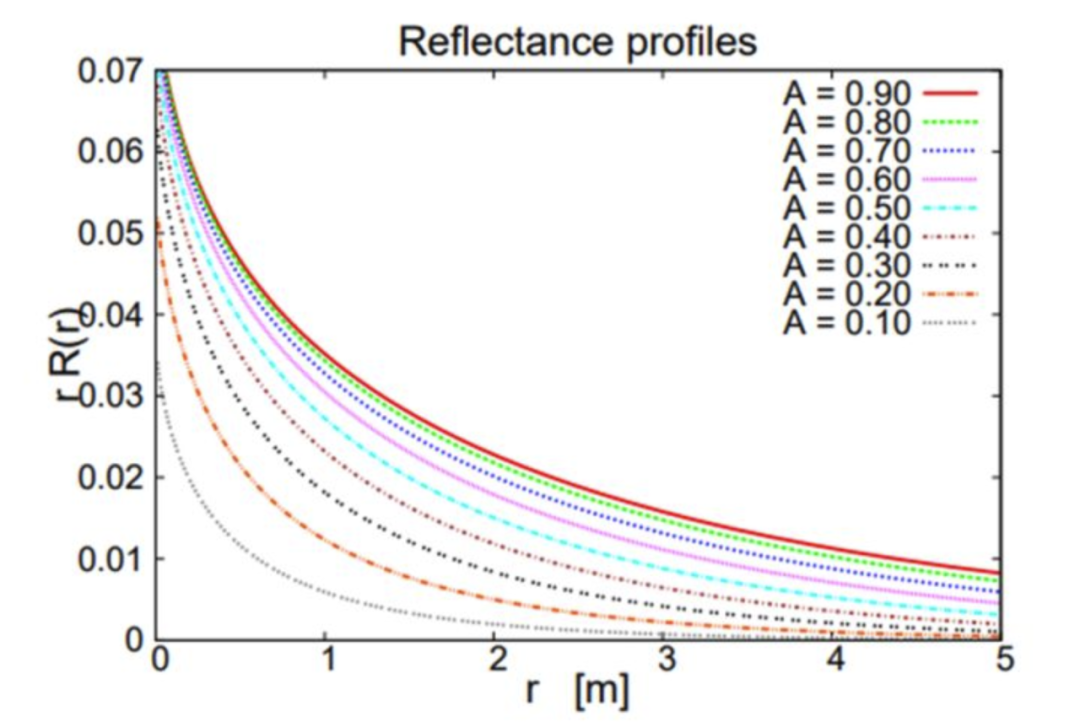
上图是Burley在论文中使用的Surface Albedo和Diffuse Mean Free Path Length着色模型参考数据。为了简化近似复杂度,舍弃了模型中原本的入射光的角度,介质本身是否 isotropic等特性。
我们通过调整 d,来让整个近似的曲线可以根据 A 的变化达到正确的近似结果。那么d值的计算方式怎么来的呢?我们可以根据上面的曲线算出一张 d 表,然后根据实际的 A 值插值出求出 d。这样做虽然有误差,但从结果来看,范围大概在 4.9% 左右,是一个很不错的结果。除了查表以外,还可以使用简单的函数来拟合出 A 和 d 的对应关系。
我们使用Burley模型在一些高配置PC或离线制片上,中低端配置PC还是采用4s方式。
Burley模型的特点在于
- 精确度相当逼近基于蒙特卡洛暴力积分的无偏解,开销却低很多
- CDF 有解析解,可进行重要性采样(importance sampling)优化
- 和高斯和拟合相比,Normalized Diffusion 不能使用分离核方法,也就是说它必须得老老实实进行 2D 卷积 Pass,因此性能要求更高
预积分的皮肤渲染
4s和burley在移动端、web端上由于耗时大,帧率一直不太理想,直接上PBR性能好但是又太塑料,那么有没有一种方式在效果折损在可接受的范围内,在这些看重性能的平台上流畅运行呢?
针对这个问题,我们采用了预积分的皮肤渲染技术。通过下图可以看到,低配版预积分皮肤虽然效果略差于高配版皮肤,但显著优于直接用pbr渲染。

预积分方案最大的优势就是速度快,主要的应用场景还是在移动端、web端上,此方案其实是一种从结果反推实现的方案。
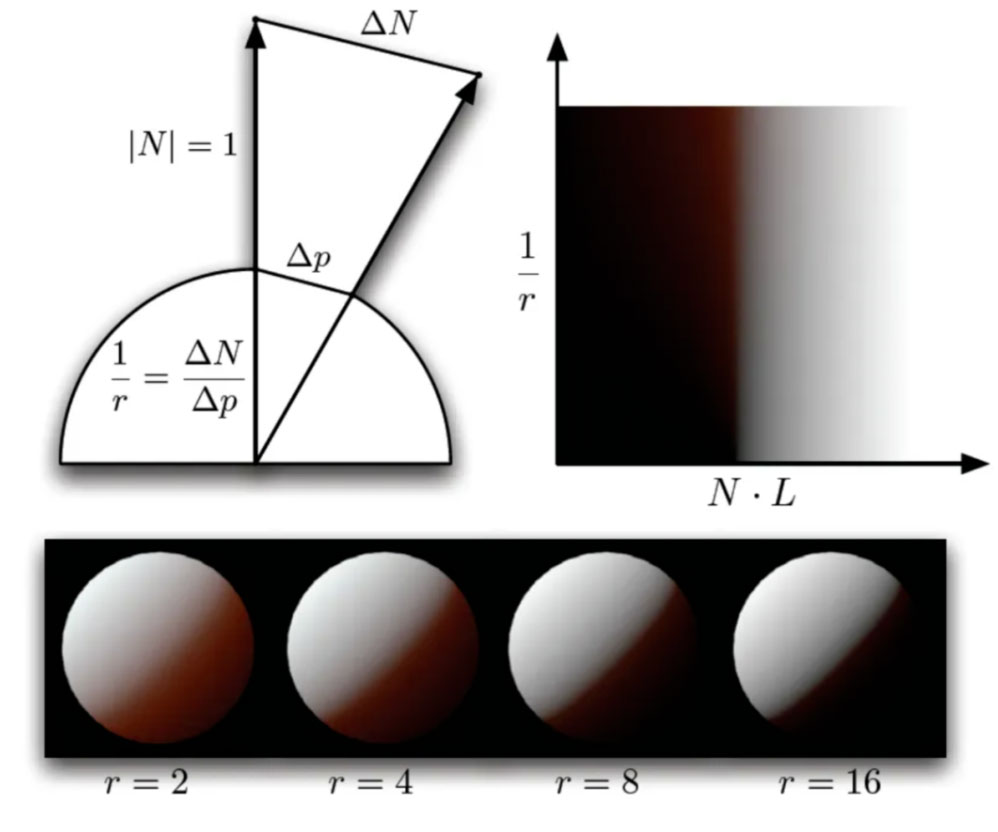
将次表面散射的效果预计算成一张二维查找表,参数分别是dot(N,L)和曲率。其中N是法线,L是光照方向。实际皮肤计算时,通过查表的方式,通过法线、光线方向、表面曲率即可直接取sss结果。该方案的效果不如4s和burley的,皮肤表面通透感差些,但是胜在性能好,在低端机如小米7上耗时也在1ms内。
1.1.3 眉蹙春山,眼颦秋水-虚拟人眼球渲染技术方案
背景
生物学的眼球解剖图非常复杂,涉及的部位数十种,在图形渲染领域,将眼球构造做简化,只关注其中的几个部位。
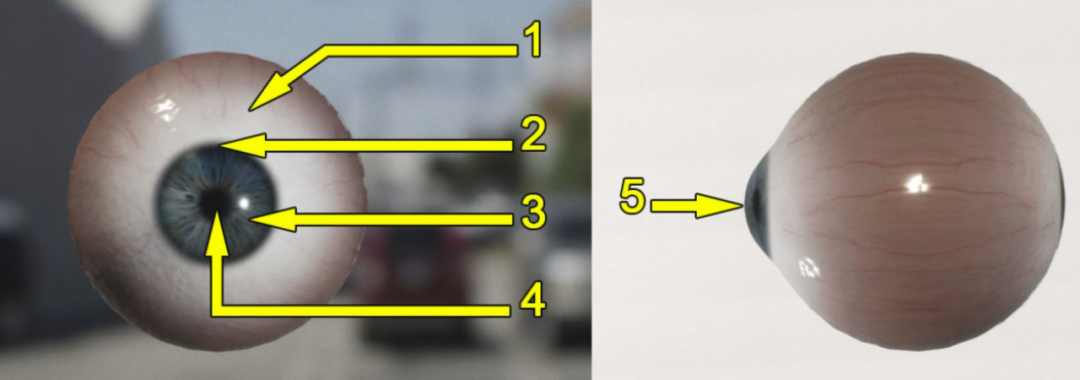
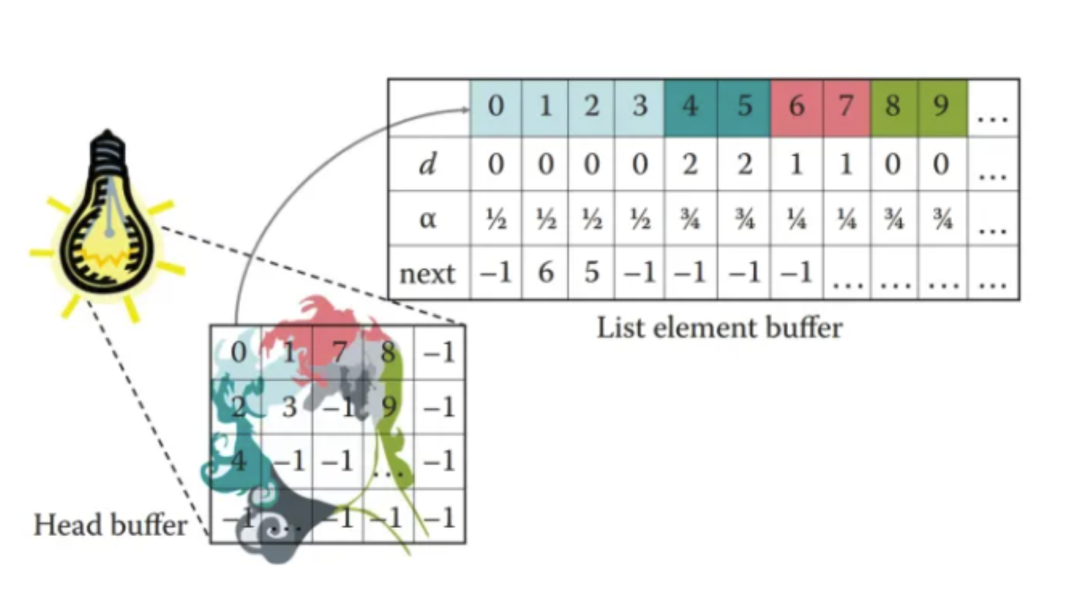
1 – 巩膜(sclera):也称为“眼白”,通常非常湿润,包含少量的触感纹理、血丝等细节。
2 – 角膜缘(limbus):角膜缘存在于虹膜和巩膜之间的深色环形。有些眼睛中的角膜缘更为明显,从侧面看时往往会消退。
3 – 虹膜(iris):虹膜是围绕在眼睛中心周围的一圈色环。
4 – 瞳孔(pupil):瞳孔是眼睛中心的黑点。这是一个孔,光线穿过这个孔后才会被视网膜的视杆和视锥捕捉到。
5 – 角膜(cornea):角膜是位于虹膜表面上的一层透明的、充满液体的圆顶结构。
眼球的渲染
眼睛的渲染通常包括以下效果部分。
- 角膜的半透和光泽反射效果。
- 瞳孔的折射和次表面散射。
- 瞳孔的缩放。最好根据整个场景的光照强度动态调整缩放大小。
- 虹膜的颜色变化。
- 其它眼球细节。

眼神光
角膜的反射部分,就是我们常说的眼神光,我们将光照结果直接烘焙成matcap贴图,实际计算中,通过将法线转换到相机空间对贴图进行采样,从而模拟眼神光。为了更真实的效果,我们还给眼神光叠加了层周围环境的cubemap,来使得眼睛更加有神。
采用该方案而不是实时计算物理光照的原因有两种,一是性能,还有一种是效果的稳定性。效果稳定性主要体现在角色的眼神光要保持稳定的形状,如果是物理光照,场景往往不止一盏光,且光的位置不一,会造成眼神光特别杂和乱。
折射和散射
瞳孔的折射和次表面散射部分,是由眼睛结构产生的。瞳孔的结构可以概括为一个有纵深的高低不平的区域,瞳孔与角膜间存在间隔。这使得光线在此处会发生折射,且光线还会进一步在瞳孔结构内部发生次表面散射。
光线在进入瞳孔内部组织前,首先会在角膜表面发生一次折射,然后进入瞳孔组织的内部,产生散射,最后从瞳孔表面的另一个点散射出来。
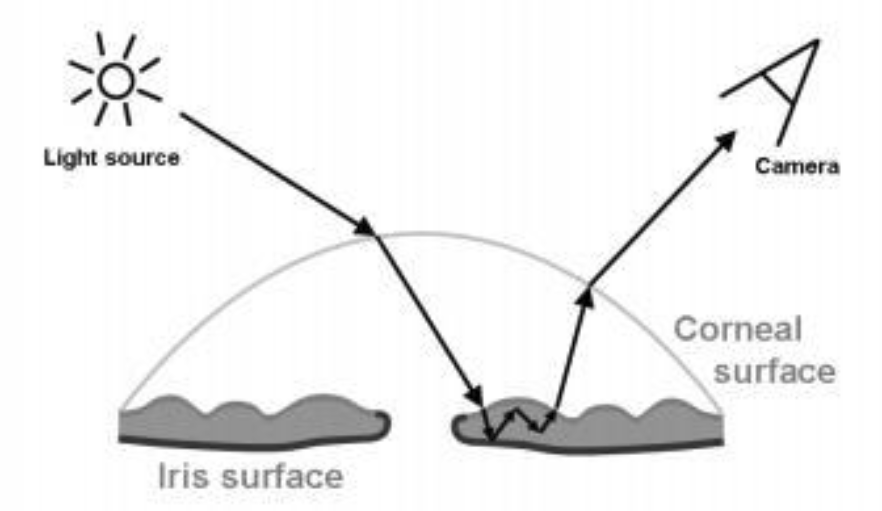
我们面临如下两个问题。
- 一束射到角膜表面的光线在经过折射后,如何计算最终入射到瞳孔表面的位置
- 光线进入角膜内部后,如何计算其散射效果
为了解决这些问题,我们采用了次表面纹理映射技术,主要为了解决多层厚度不均匀的材质次表面层的计算。
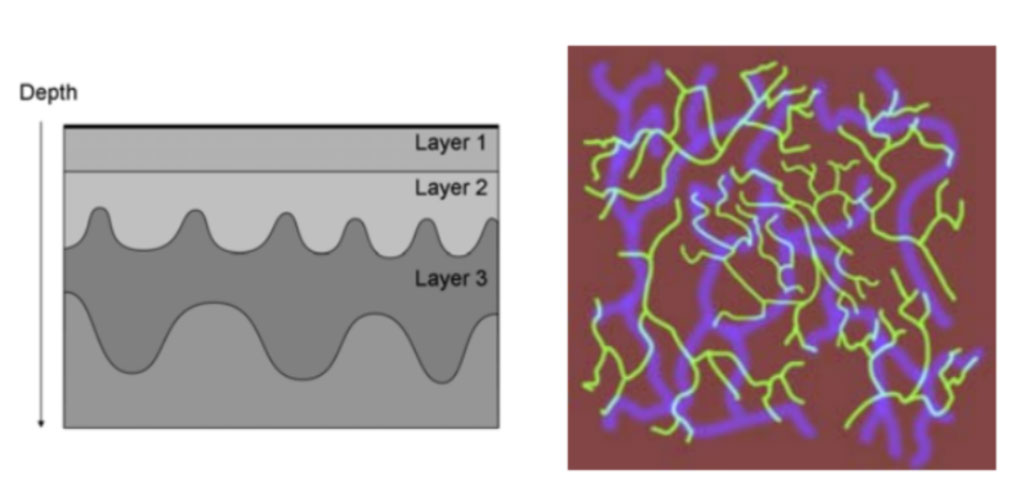
该方案核心在于将眼睛根据深度的差异分成多层,每层的散射参数分别存在贴图的一个通道中,通过当前眼睛像素分别位于哪一层取得具体的散射参数来参与眼睛散射的计算。
折射部分可以采用视差贴图或者IOR来计算。
2 角色个性化的核心功能:捏脸与换装
2.1 基于面部骨骼驱动的捏脸系统介绍
捏脸系统的目的是满足用户的个性化需求,业界常见的捏脸方案有两种:
- 骨骼驱动:通过修改骨骼Transform达到网格体变化以完成捏脸,自由度高,但可控性较低。
- Blendshape(融合变形):通过一系列Blendshapes混合的方式完成,自由度与精细度受Blendshape影响,因此设计师制作工作量巨大。
幻星数字人基于骨骼驱动的方式实现了捏脸/捏人系统。骨骼驱动相比于Blendshape方案,设计师制作工作量较少,且有着更好的性能,但是捏脸的精细程度受骨骼数量/权重限制。
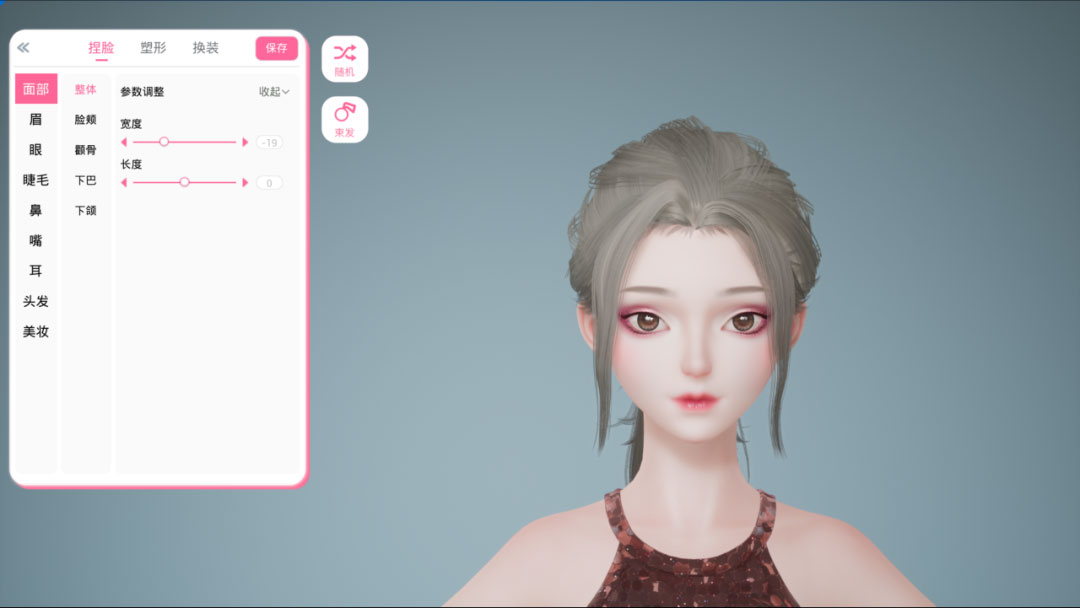
为解决骨骼驱动方案可控性较低的问题,需要设计师在有限的骨骼数量下,设计好捏脸项,并为每个捏脸项配置好控制的骨骼以及参数范围。而这个配置过程需要反复调试、验证,极其消耗设计师的时间。为此我们配套开发了捏脸配置工具,设计师可以在该工具上直观的配置每个捏脸项所控制的骨骼和参数范围,并直接看到捏脸效果,降低了设计师与开发的沟通和反复调试成本,缩短了制作周期。
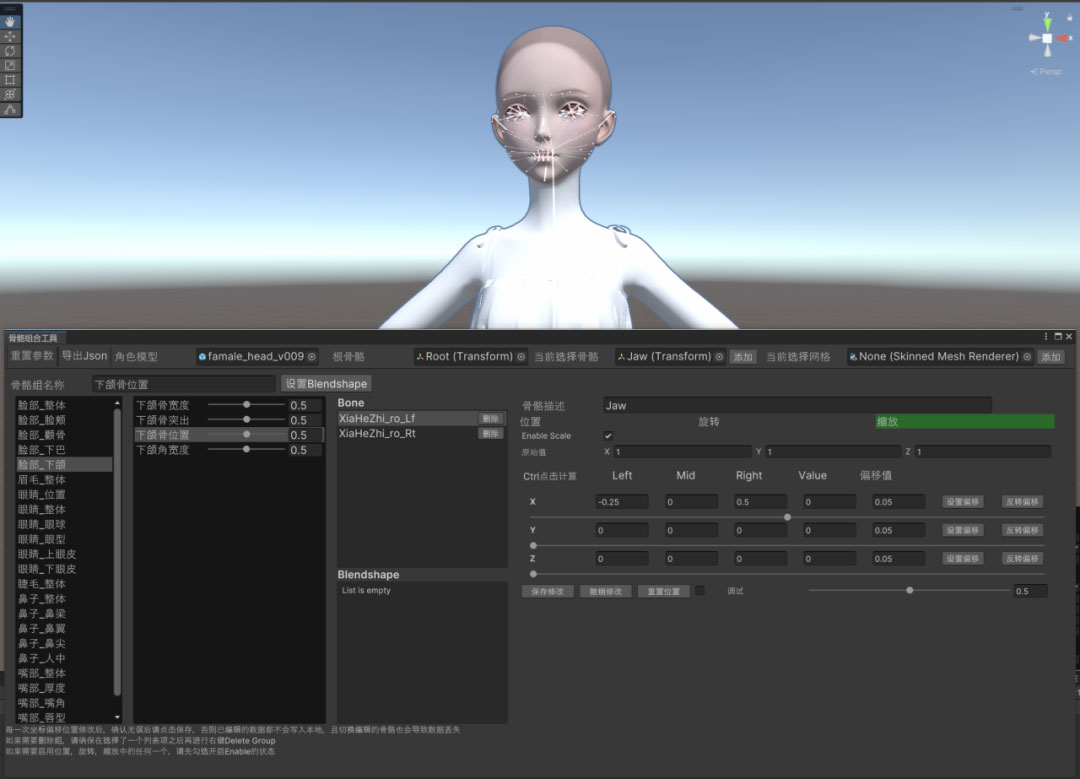
幻新数字人还支持实时面捕驱动。表情动画方面我们使用Blendshape来实现,按照苹果ARKit52个表情基为规范制作。然而在捏脸骨骼驱动的基础上再叠加Blendshape容易出现异常穿帮现象,如眼睛无法闭合或者过度闭合等。为了缓解该问题,一方面需要控制好捏脸与动画Blendshape的程度,另一方面我们提供了表情动画系数与捏脸参数关联的配置,面捕驱动过程中会实时根据当前的表情Blendshape系数调整捏脸参数。

除了基于骨骼驱动的捏脸修改脸部外形,切换妆容,如唇妆、面妆、美瞳等功能也提供了更多的个性化选择。
2.2 分部件可定制换装系统介绍
换装本质上是切换网格体(Mesh),由于幻星数字人还支持塑形和半身驱动,因此需要使用骨架网格体(SkeletalMesh),并保证服装的基础骨架与身体骨架保持一致。
我们一开始仅对服装进行了部件拆解,如上装、下装、鞋子等,代码中使用枚举对其定义并固定了服装类型间的互斥规则。设计师需要严格按照身体模型大小制作服装,以免与身体模型发生穿模。然而这样无法满足设计师对有紧身部位的服装需求,在紧身处服装可能与身体模型大小一致甚至更小。
为满足设计师灵活的服装需求,我们对身体模型也进行了拆分如躯干、手臂、手、腿、脚等,换装时需要根据规则将重叠的身体部件隐藏。由于身体部件的拆分,换装规则更加复杂,我们设计和开发一套更加灵活的换装系统,方便配置换装规则。我们使用GameplayTag来定义身体和服装部件,因为GameplayTag是树形结构,相对于枚举更直观的描述部件间的父子结构,方便完成复杂的匹配、检测、互斥等功能。每一件服装都需要为其配置好部件Tag以及覆盖的身体部件,运行时会根据该配置完成换装。换装整体流程为,首先根据新服装的配置,将覆盖/冲突的身体/服装部件卸载;再加载设置上新的服装部件;最后还需要对身体部件复原,如长袖上衣时卸载了手臂部件,切换到无袖上衣时需要将手臂部件复原。
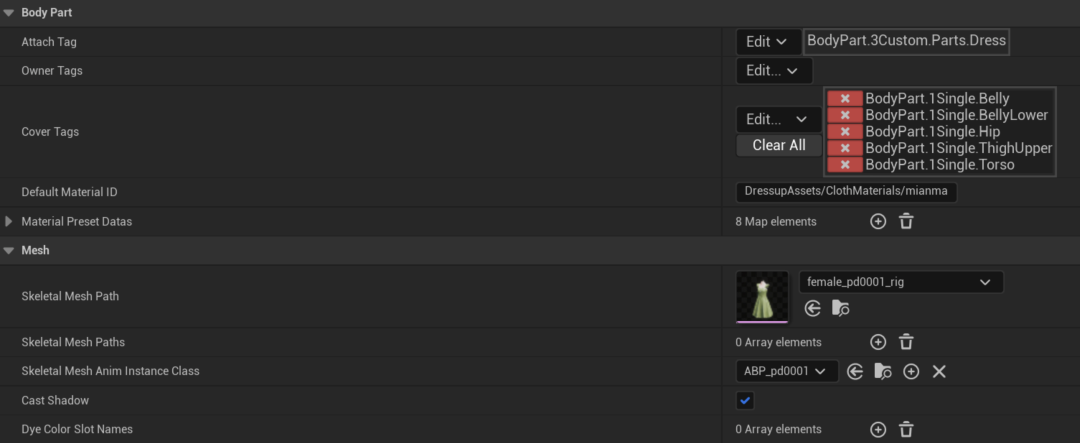
同时该配置上还可配置服装可选的材质,以支持更换材质/颜色等功能,满足用户个性化需求。
2.3 引擎中的半身驱动技术方案
半身驱动的基本流程是:通过算法实时检测出人体关节点,再对算法人体姿势进行重定向并应用在幻星数字人上。
由于幻星数字人是使用拆分部件的方式组成,需要将当前驱动的姿势同步给所有部件。对于和身体骨架完全一致并且不需要支持物理的部件,如脚、腿、手等,使用设置主姿势组件(Set Master Pose Component)的方式同步姿势,减少游戏线程消耗;对于有额外骨骼和需要物理的部件,如衣服、裙子等,通过动画蓝图从网格体复制姿势(Copy Pose From Mesh)的节点同步姿势。
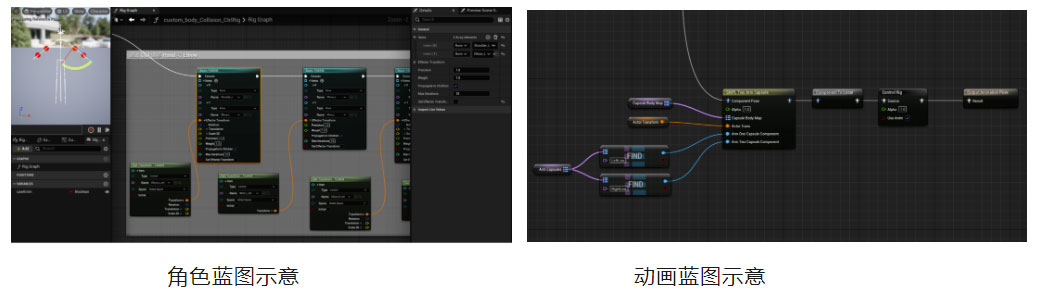
基于以上工作,数字人已经能够实现驱动,但仍存在关节扭曲,肩膀塌陷和部件穿模等效果问题,下面将分别介绍针对类似动态效果问题的优化方案。
如果直接将检测算法计算得出的手腕旋转值设置到幻星数字人的手腕骨骼上,会产生数字人手腕区域网格明显扭曲的问题。这个问题是由于手腕的旋转不符合人体的手腕运动约束,真实的手腕旋转时会带动到手肘之间的肌肉一起运动。为了模拟这样的情况,首先在模型设计生产阶段,需要在手肘与手腕之间插入多段骨骼。
并在运行时实时处理手腕关节扭曲校正。算法检测出的手腕旋转值后,将其转化为欧拉角的形式,并确定手腕的扭曲轴(此处假设扭曲轴对应欧拉角的Roll)。对于该手腕欧拉角,需保持Pitch和Yaw值不变,将Roll值以一定的权重值插值分摊到小臂关节链上。

手臂抬起时,肩膀处出现挤压、凹陷等问题。这些问题是由于线性混合蒙皮导致的体积损失。为了系统性的解决该问题,我们引入了基于Pose Space Deformation的修型模块。绑定师需要给需要修型的骨骼添加不同方向/角度的姿势,并为每个姿势制作BlendShape修型,最终将所有姿势烘培到动画中。这些动画通过我们的自研插件导入UE后能自动生成姿势资产(PoseAsset)及动画蓝图(AnimBlueprint)。插件会为每个需要修型的关节创建一个姿势驱动器(Pose Driver)动画节点,并为每一个与该关节关联的姿势创建对应的姿势目标(Pose Target)。
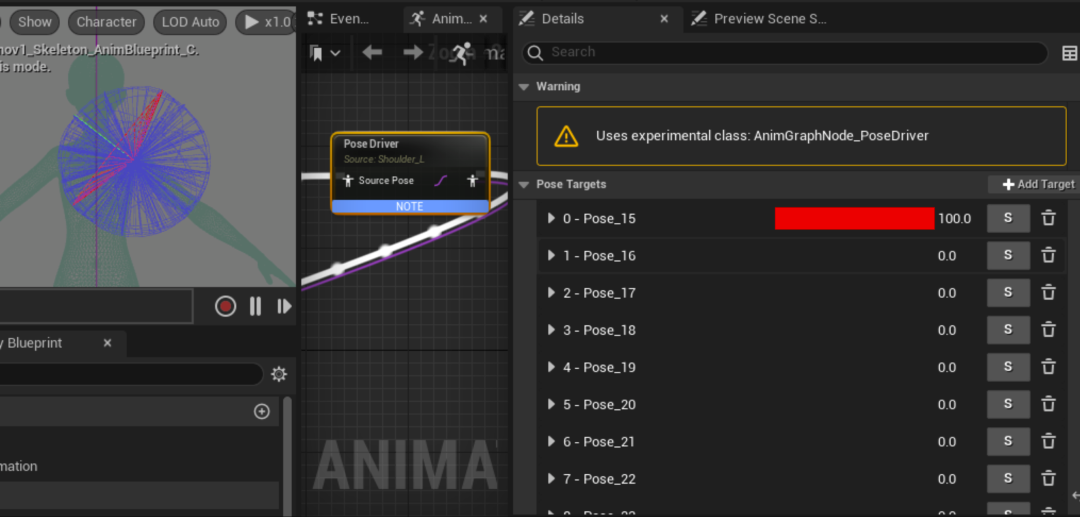
该蓝图会作为后处理动画蓝图作用于幻星数字人上,根据数字人的当前姿势与姿势目标的”接近程度“得出一个权重值,该权重值最终会作为每个姿势目标对应的BlendShape系数叠加到人物网格上。
为了解决由于肢体关键点深度信息不足导致的穿模现象,我们在幻星数字人的驱干及手部添加了用于碰撞检测计算的胶囊体,并在动画蓝图的Retarget重定向步骤后添加了自定义动画蓝图节点。该节点的作用是根据预设胶囊体间的相交结果,对手部关节进行旋转调整,避免手部之间或手部与躯干的相交。再进行IK(Inverse Kinematics)重计算以得到更自然的姿势。
3 物理仿真与模拟
在人物动态效果的物理仿真与模拟方面,头发和服装是该方向的两大模拟难点。
幻星数字人在人物头发的实时物理模拟上,为不同计算平台设计了高配与低配两套模拟方案。在算力紧张的终端设备上,如移动设备,低配笔记本电脑等,我们基于Hair Mesh方式制作头发模型,并通过Dynamic Bone的动态模拟方案来还原头发飘动的物理效果。每顶头发平均绑定40-50根左右的动态骨骼,即可达到满足简单物理力学模拟的顺滑效果。其原理可理解成具备父子层级关系的弹簧振子铰链,如下图所示,每个黄色包围盒对应一根动态骨骼,运动状态会从根节点向子节点传导。运动过程中通过每个step的约束求解来更新符合力学模型的运动参数,同时可设置对应的阻尼,弹性,硬度和惯性等参数来控制仿真过程中的物理量。
这套方案的优势是计算开销小且效果精度可伸缩。以40根骨骼,3万面数的头发为例,经过测试,该方案能在骁龙625等7年前的主流移动设备上跑满30帧。且随着算力的增加,通过骨骼的LOD分级设置,可以在骁龙825等高端设备上应用80-100根动态骨骼,来提升整体的物理仿真表现。
该方案在移动端实时渲染场景下,基本能够达到对物理效果的预期,但依然存在一系列的真实感问题。在马尾或者丸子头等发型上尚不明显,但如下图所示的蓬松刘海长发中,可以看到头发的物理存在两处明显问题:1 头发的柔性体效果没有表现出来,整体像打了较重的发胶,动态效果不丝滑,且头发和头部模型进行碰撞时有明显被撑开的效果问题。2 发束与发束间没有相互穿插的效果,没有办法做手撩刘海等动态效果。
在计算性能较好的PC平台,为了解决上述问题,我们采用了Strand Based毛发实时模拟技术。该方案通过引导线制作发束,针对引导线进行tessellate细分,生成多个控制点,如下图所示。我们可以将控制点的运动抽象成单个粒子在速度场中运动分析,以欧拉法的视角在网格中进行基于位置的约束求解。一般来讲一个人物拟真发型通常包含8-10W根发丝,逐根解算的性能开销过大,因此主要算力聚焦在求解引导线的运动状态,其他发丝通过插值得到当帧的位置信息。在计算开销增加的前提下,大幅提升了头发真实感物理的模拟效果,如上图所示,在柔顺程度和与头皮的贴合感上有较为明显的改善。
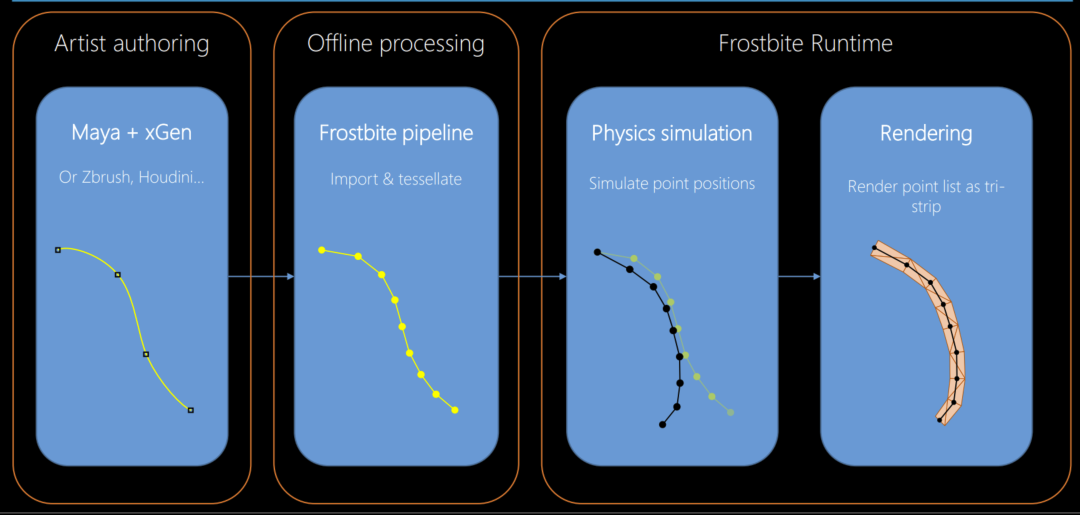
服装方面,布料的物理效果模拟是图形学领域比较有挑战的技术方向之一。常见的模拟算法包括基于物理(Physics-Based)的求解方法,基于约束(Constraints)的求解方法和有限元分析(Finite Element Method)等。对于虚拟人的实时服装仿真这一业务场景而言,对求解方式有两个具体要求:性能和稳定性。性能方面,要求求解过程能够并行化,迭代能够较快收敛。这方面如基于约束的Projective Dynamics,有限元分析等方法都难以彻底的GPU并行解算,在5000-8000个三角面的布料上无法达到实时。而在稳定性方面,要求运动过程中物理状态尽量稳定,避免在离散时间步长内发生越界和穿插。这方面弹簧质点系统中的显示欧拉方法就难以满足稳定性要求。
在游戏和虚拟人直播领域中,较为主流的方案还是基于位置的约束求解方法PBD(Position Based Dynamics),比如Nvidia的Flex,UE5的Chaos Cloth等。PBD并不是一个严格物理正确的求解算法,但其最大的优势是实现简单,对内存访问少,可以在GPU上完成并行化求解过程,能够在网格分辨率相对不高的布料模型上做到实时。且因为迭代过程相对简单,对其他约束有较好的兼容性,Flex在Siggraph2014上发表的Unified Particle Physics框架也很好的说明了这一点。
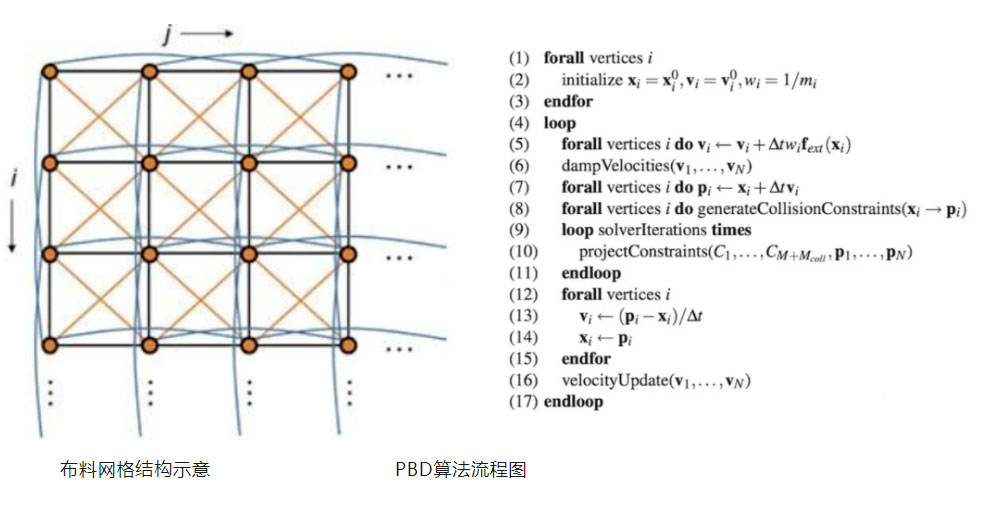
PBD的算法思路可简单概括为:先建立Stretching和Bending等约束,再将约束投影作用到位置和速度的更新上去。整个算法流程如下图所示,最核心的步骤在9-11行进行约束投影,并得到优化后的位置,在12-15行更新当前的位置和速度信息。如何进行约束的并行化求解是整体计算加速的关键问题,本质上来说是一个线性系统的优化问题。常用的方法包括Gauss-Seidel 迭代方法和Jacobi方法。GS方法的优势是一般情况下收敛速度会略快于Jacobi方法,但存在bias问题。Jacobi方法不存在偏向性,主要通过位置更新量的平均值来和当前位置做线性混合,但整体的收敛速度会低于GS方法。
当然如上文中提到,PBD因为其求解过程并非完全基于物理,导致控制效果的参数并不完全正交,迭代步长,迭代次数与布料硬度等参数的调节相对不直观且容易顾此失彼。为了更好解决这一问题,业界推出了最新的XPBD(Extended Position-Based Dynamics)算法,未来我们将基于UE5的Chaos物理系统,通过XPBD的方法进一步提升实时过程中服装的布料仿真精细程度。
三 未来展望
幻星数字人未来的愿景是为B站每个用户打造个性化的3D数字人形象。我们将在下一阶段持续探索形象风格化渲染方面的相关技术,优化虚拟人资产生成管线的类型兼容性和生产效率。此外,随着AIGC技术的快速发展,我们将在两个方向结合制作管线和业务需求进行AI能力的整合。第一,我们将聚焦在3D数字人动画智能生成系统这一领域,通过AI算法识别并提取真人视频中的人物动作,以重定向的方式输入到幻星数字人模型上,实现高效的数字人舞蹈/短剧/MV视频生产流程。第二,我们将在制作管线的原画环节,引入Stable Diffusion等AIGC能力辅助视觉设计,降低产研之间的沟通成本,提升设定->概念视效->审核->制作的整体效率,同时持续关注3D建模和绑定环节的AI相关技术。这些技术的引入,将加速我们在虚拟制片与投稿领域的业务落地,为平台创造更高的生态价值。
参考文献
- Pharr, Matt, Wenzel Jakob, and Greg Humphreys. Physically based rendering: From theory to implementation. Morgan Kaufmann, 2016.
- Marschner, S. R., Jensen, H. W., Cammarano, M., Worley, S. and Hanrahan, P. 2003. Light Scattering from Human Hair Fibers. ACM Transactions on Graphics, 22, 3, 780–791
- Kajiya, J. and Kay, T. 1989. Rendering Fur With Three Dimensional Textures. In Computer Graphics (Proceedings of ACM SIGGRAPH 89), 23, 3, ACM, 271–280
- Burley, Brent, and Walt Disney Animation Studios. “Physically-based shading at disney.” Acm Siggraph. Vol. 2012. vol. 2012, 2012.
- Unreal Engine Document, et al. “Working with Modular Characters.” https://docs.unrealengine.com/4.27/en-US/AnimatingObjects/SkeletalMeshAnimation/WorkingwithModularCharacters/#:~:text=The%20Master%20Pose%20Component%20is,considered%20to%20be%20the%20master.
- Nvidia, GPU Gems3. chapter-14-advanced-techniques-realistic-real-time-skin.
- Arkit 52 BlendShapes,BlendShapeLocation | Apple Developer Documentation(https://developer.apple.com/documentation/arkit/arfaceanchor/blendshapelocation)
- Unreal Engine Document, et al. “Subsurface Profile Shading Model.” Subsurface Profile Shading Model | Unreal Engine 4.27 Documentation(https://docs.unrealengine.com/4.27/en-US/RenderingAndGraphics/Materials/LightingModels/SubSurfaceProfile/)
- Macklin, Miles, Matthias Müller, and Nuttapong Chentanez. “XPBD: position-based simulation of compliant constrained dynamics.” Proceedings of the 9th International Conference on Motion in Games. 2016.
- Bouaziz, Sofien, et al. “Projective dynamics: Fusing constraint projections for fast simulation.” ACM transactions on graphics (TOG)4 (2014): 1-11.
- Müller, Matthias, et al. “Position based dynamics.” Journal of Visual Communication and Image Representation2 (2007): 109-118.
- Volino, Pascal, Nadia Magnenat-Thalmann, and Francois Faure. “A simple approach to nonlinear tensile stiffness for accurate cloth simulation.” ACM Transactions on Graphics4 (2009): Article-No.
- Tafuri, Sebastian. “Strand-based Hair Rendering in Frostbite.” ACM SIGGRAPH Courses: Advances in Real-Time Rendering in Games Course (2019).
- Macklin, Miles, et al. “Unified particle physics for real-time applications.” ACM Transactions on Graphics (TOG)4 (2014): 1-12.
作者:
Paladin:哔哩哔哩技术专家;怪盗基德:哔哩哔哩资深开发工程师;KayPlus:哔哩哔哩资深开发工程师;AI酱:哔哩哔哩资深开发工程师
来源:幻星数字人团队 哔哩哔哩技术
原文:https://mp.weixin.qq.com/s/OgyG0-7CCvNool0r6soO2w
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
