
VVC作为最新的视频编码标准,在保持像素质量方面表现出了良好的性能。为了挖掘视频会议场景在超低码率下的更大压缩潜力,我们提出了一种码率可调的人脸视频混合编码方案。该混合方案结合了传统编码的像素级精确恢复能力和深度学习基于压缩信息的生成能力,通过像素级双向预测、低比特率一阶模型和无损关键点编码器的协作,在1.47KB/s的超低比特率下实现了高达36.23dB的PSNR。在不引入任何额外比特率的情况下,在完全公平的比较实验中,我们的方法比VVC有明显优势,证明了该混合编码方案的有效性。此外,我们的方案可以适应现有的任何编码器/配置,以应对不同的编码需求,并可根据网络情况动态调整比特率。
混合编码方案的提出背景
在新冠肺炎疫情背景下,视频通话越来越多,人脸视频压缩技术越来越重要。在网络质量较差的情况下,以超低码率实现稳定流畅的视频通话是一个热门的研究课题。现有的人脸视频压缩方法可以分为两类:传统的编码方法和基于深度学习的方法。
传统的视频编码方法即使在快速变化的场景中也具有像素级的精确恢复的优势,其中VVC是最先进的标准。与HEVC相比,VVC在保持相同视觉质量的同时节省了约50%的比特率。然而,以VVC为代表的这些传统方法并没有对视频内容进行区分,并对所有视频进行了相同的压缩,但实际上,人脸视频压缩应该有更大的潜力。
深度学习具有基于精简信息的生成能力,因此在人脸视频压缩方面具有很大的潜力。研究人员提出了一些基于深度学习的方法[1-3,5]来实现人脸视频压缩。这些方法均采用静态参照系,在场景切换或姿态转换较大的情况下,难以保证良好的性能,导致高保真度恢复失败。还有的方法利用一个原始帧作为参考,并将生成的帧添加到参考帧池中,这样容易造成错误积累。然而,像素级的精确恢复是传统编码方法的优势所在。因此,我们提出了一种将传统编码与深度生成相结合的混合编码方案。此外,现有的基于AI的视频压缩方法很难动态调整比特率,进一步限制了其实用性。
混合编码方案
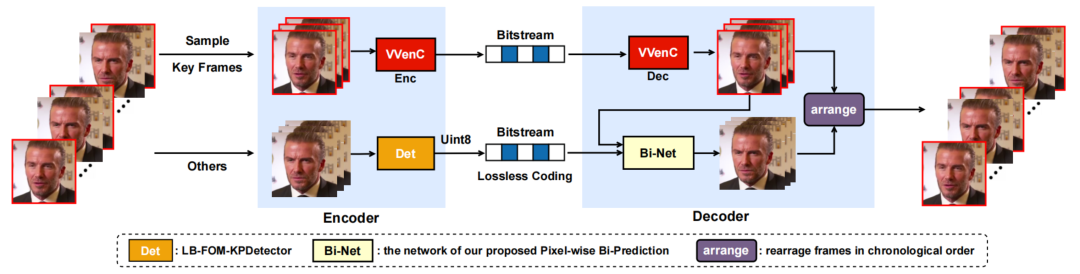
为了解决上述问题,我们提出了一种比特率可调的混合编码方案。对于一个视频序列,在发送端,我们按照一定的频率对关键帧进行采样(例如,每5帧取一个关键帧),使用VVenC[6]对这些关键帧进行编码,这是一种高效的VVC实现,压缩性能类似于VVC,但编码复杂度要小得多,然后将比特流发送给接收端。对于非关键帧,我们使用一个关键点提取器LB-FOM-KPDetector来提取Uint8型的关键点,对它们进行无损编码,并将比特流传输给接收端。
在接收端,对VVenC的比特流进行解码,重建关键帧。利用重建的关键帧和非关键帧的关键点,利用提出的像素级双预测方法的网络Bi-Net对非关键帧进行重建。最后,我们按照时间顺序重新排列所有帧,以在接收端得到最终的视频流。
总的来说,这是一种混合方案。结合传统编码的像素级恢复能力和深度学习的细节生成能力,我们提出的混合方案能够在超低比特率下合成高质量的人脸视频。同时,比特率可以通过两个通道动态调整:关键帧的采样频率或关键帧的压缩率。因此,我们可以根据网络情况动态地选择合适的配置,这比前面提到的方法更实用。
Bi-Net
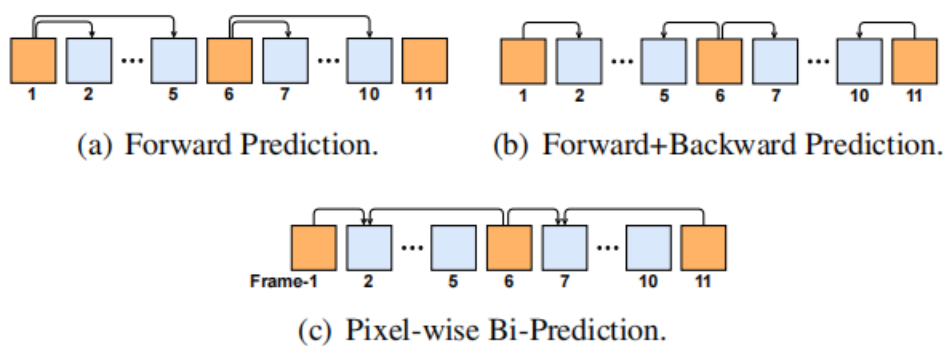
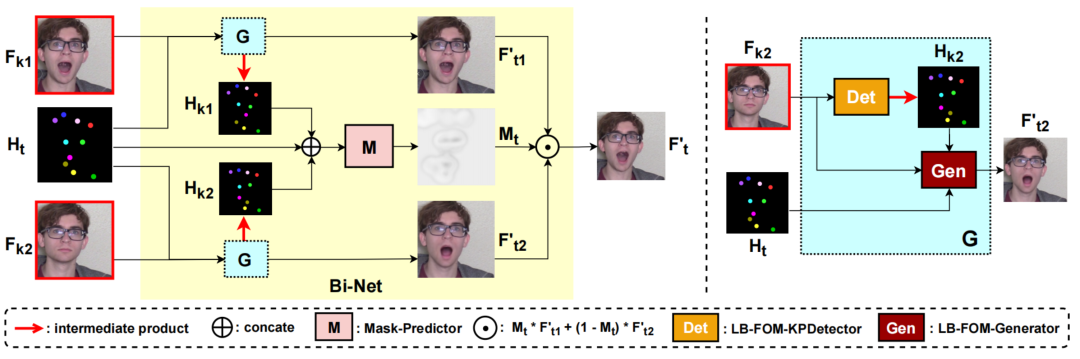
这里我们展示了三种预测方案,图中橙色方块表示关键帧,蓝色方块表示待预测的非关键帧。Forward prediction会导致第5帧到第6帧之间有明显的抖动,Forward+Backward prediction会导致第3帧到第4帧之间有明显的抖动,破坏我们的主观体验。因此,我们提出了一种像素级的双向预测方法,并设计了一个Bi-Net网络来实现这一思想。如下图所示。

LB-FOM
在这里,我们提出了低码率版本的FOM:LB-FOM,在几乎不损失重建质量的情况下,大幅降低关键点码率。结构如下:
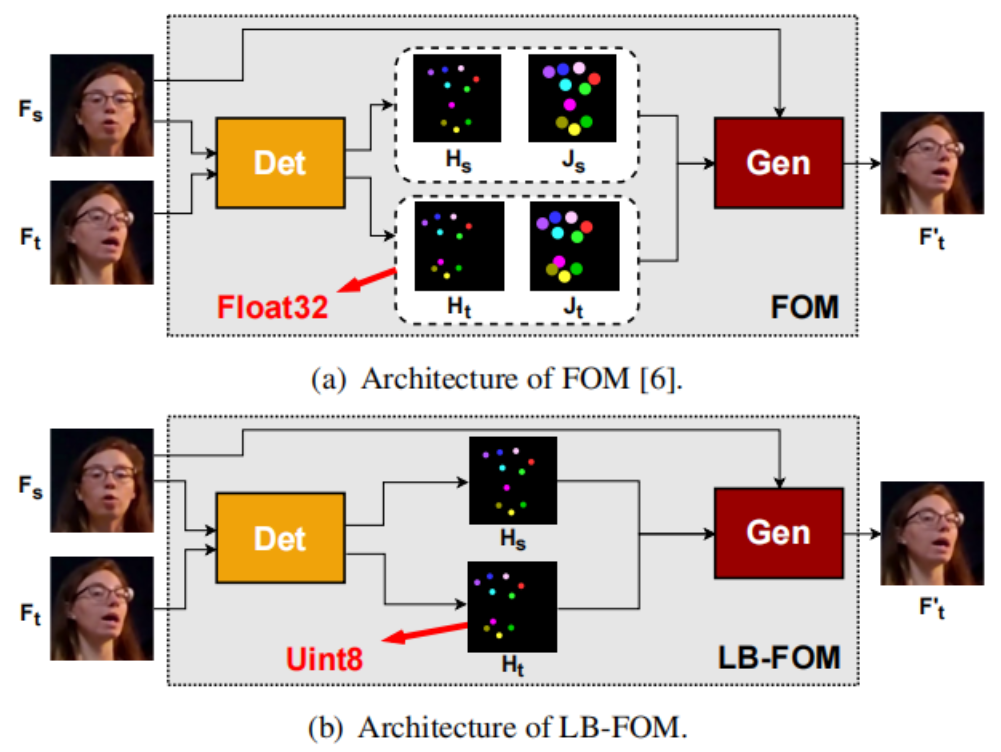
如图(a)所示,FOM[4]利用KPDetector预测源图像的关键点和对应的雅可比矩阵,预测目标图像的关键点和对应的雅可比矩阵,其中所有数据类型为Float32。然后将、、、和源图像输入生成器,得到最终结果。在原始FOM中,每一帧都由固定数量的关键点(例如10个)及其雅可比矩阵表示。每个关键点由(x, y)坐标组成,对应的雅可比矩阵大小为2×2。由于所有数据都是Float32类型,因此对于每一帧,关键点用80 Bytes表示,雅可比矩阵用160 Bytes表示,因此总比特率为240 Bytes/帧。
为了降低比特率,我们在图(b)中提出了一个低比特率版本的FOM(LB-FOM)。具体来说,我们去掉了雅可比矩阵的预测,将[-1,1]中的关键点量化为[0,255]范围,这意味着将Float32类型的数据转换为Uint8类型。这样,总码率从240 Bytes/帧降低到20 Bytes/帧。
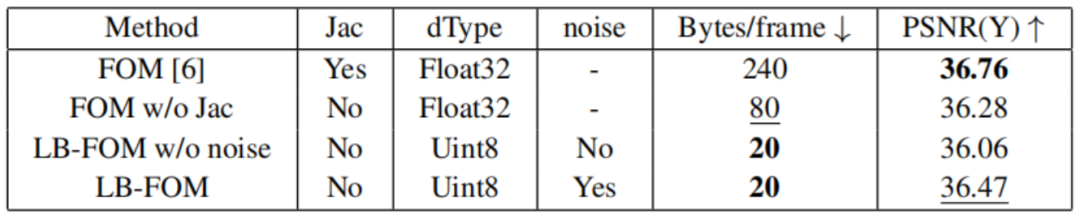
上表显示了此类削减的影响。在上表中,去除雅可比矩阵,将Float32转换为Uint8直接导致PSNR持续下降,从36.76dB下降到36.28dB,再到36.06dB。这可能是因为直接量化是不可微的,导致梯度反向传播失败。当我们在预测的关键点上加入均匀噪声来模拟训练阶段的量化损失时,与原始FOM相比,PSNR值仅降低0.29dB,而比特率降低到原来的1/12,这是很划算的。这表明我们提出的LB-FOM的有效性。
实验及Demo演示
混合编码方案 v.s. VVenC
下图展示了在相同的比特率下,分别使用VVenC方案与我们的混合编码方案对视频进行编码,在接收端重建出的图片质量对比。可以看出在极低码率下,VVenC编码的视频出现了明显的块效应,而我们的混合编码方案依然能保证较高的重建质量。

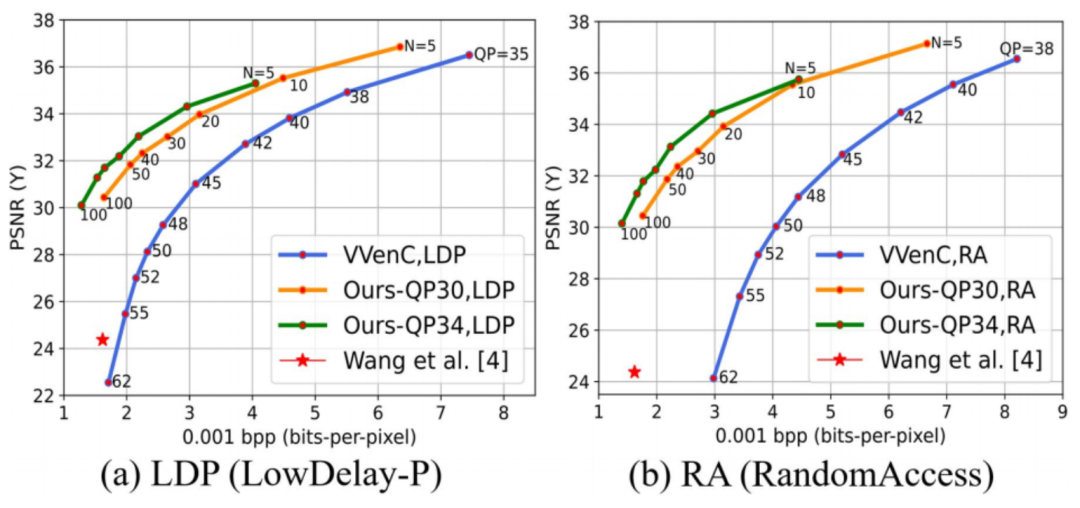
下面的折线图分别展示了在LDP和RA模式下的定量结果。不失一般性,以左图为例。我们选择VVenC作为我们的baseline,在QP=35到QP=62之间测试它的性能。QP值越高,压缩率越小。如前所述,我们的方法可以通过两个通道实现比特率的动态可调:调整关键帧的采样间隔或调整关键帧的压缩率(即QP值)。在左图中,橙色折线表示QP=30下采样间隔从5取到100时的不同性能,绿色折线表示QP=34下的性能。事实上,QP值和采样间隔是可以自由确定的,不局限于列出的。可以发现,无论在LDP模式还是RA模式下,我们的方法都比VVenC取得了显著的性能提升。在LDP和RA模式下,分别取得了-43.12%与-58.48%的BR-rate。
参考文献
[1] Dahu Feng, Yan Huang, Yiwei Zhang, Jun Ling, Anni Tang, and Li Song, “A generative compression framework for low bandwidth video conference,” in 2021 ICMEW, July 2021, pp. 1–6.
[2] Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu, “One-shot free-view neural talking-head synthesis for video conferencing,” in CVPR, June 2021, pp. 10039–10049.
[3] Maxime Oquab, Pierre Stock, Daniel Haziza, Tao Xu, Peizhao Zhang, Onur Celebi, Yana Hasson, Patrick Labatut, Bobo Bose-Kolanu, Thibault Peyronel, and Camille Couprie, “Low bandwidth video-chat compression using deep generative models,” in CVPR Workshops, June 2021, pp. 2388–2397.
[4] Aliaksandr Siarohin, St´ephane Lathuili`ere, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe, “First order motion model for image animation,” in NeurIPS, December 2019.
[5] Goluck Konuko, Giuseppe Valenzise, and Stephane Lathuiliere, “Ultra-low bitrate video conferencing using deep image animation,” in ICASSP 2021 – 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 4210–4214.
[6] Adam Wieckowski, Jens Brandenburg, Tobias Hinz, Christian Bartnik, Valeri George, Gabriel Hege, Christian Helmrich, Anastasia Henkel, Christian Lehmann, Christian Stoffers, Ivan Zupancic, Benjamin Bross, and Detlev Marpe, “Vvenc: An open and optimized vvc encoder implementation,” in 2021 ICMEW, 2021, pp. 1–2.
原标题:Generative Compression for Face Video: A Hybrid Scheme
作者:唐安妮,黄琰,凌军,张志宇,张一炜,解蓉,宋利
发表会议:ICME2022
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
