
视频编解码器的原理是,对于当前要编码的信号,编解码器会从之前重构的信号中找到相关的上下文(例如,各种预测作为上下文),以减少时空冗余。相关上下文越多,比特率节省就越高。但对于大多数神经视频编解码器(NVC),上下文提取和利用的方式仍然有限。
来源:arxiv
作者:Jiahao Li, Bin Li, Yan Lu
论文链接:http://arxiv.org/abs/2302.14402
内容整理:王妍
本文在时间和空间维度上增加上下文多样性以进一步提高 NVC。时间维度上,本文指导模型跨帧学习分层质量模式,进一步利用视频中的长距离时间相关性,并有效缓解大多数 NVC 中存在的质量退化问题。此外,本文采用偏移分集来增强基于光流的编解码器,其中多个偏移可以减少复杂或大型运动的扭曲误差。特别是,受传统编解码器中加权预测的启发,将偏移量分组,并提出了跨组融合来改进时间上下文挖掘。空间维度上,基于最近的棋盘模型和双空间模型,本文设计了一种基于四叉树的分区来改进潜在表示的分布估计。
实验表明,本文的编解码器比以前的 SOTA NVC 节省了 23.5% 的比特率。更好的是,本文的编解码器在 RGB 和 YUV420 色彩空间的 PSNR 方面已经超过了正在开发中的下一代传统编解码器 ECM。
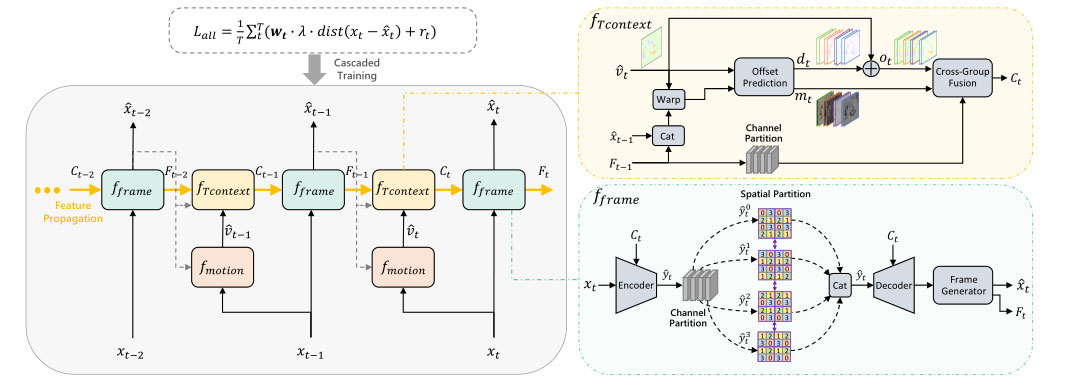
模型框架


分层质量模式
传统的编解码器广泛采用分层质量结构,将帧分配到不同的层,然后使用不同的 QPs(量化参数)。这种设计从两个方面改进了一般低延迟编码的性能。一种是周期性地提高质量可以缓解错误传播。另一方面,在多参考帧选择和加权预测机制的支持下,最近参考帧和远程高质量参考帧的预测组合更加多样化。事实上,有实验表明,同时参考最近帧和更远的高质量帧的分层质量结构获得的性能最佳。
为此,本文建议指导 NVC 在培训期间学习分层质量模式。具体而言,本文为率失真损失中的每个帧添加权重 wt , wt 的设置遵循层次结构。在这种分层失真损失的支持下,周期性地生成高质量输出帧 xt 和包含许多高频细节的特征 Ft 。这有助于提高运动补偿(MEMC)的有效性,从而缓解许多其他 NVC 所面临的错误传播问题。此外,通过跨多个帧的级联训练,形成了特征传播链。高质量的上下文对后续帧的重建至关重要,它被自动学习并保持在长范围内。因此,对于 xt 的编码,Ft-1 不仅包含从 xt-1 中提取的短期上下文,还提供了从许多先前帧中提取的长期且不断更新的高质量上下文。这种多样的 Ft-1 有助于进一步利用跨多个帧的时间相关性,然后提高压缩比。
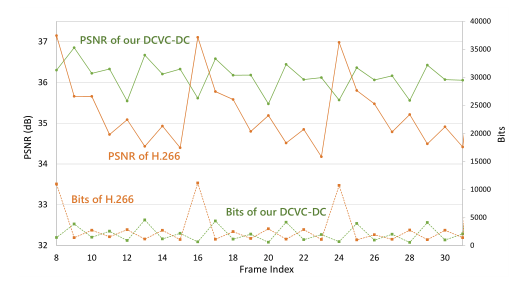
上图显示了本文的 NVC 的质量模式。可以看到,与 H.266 相比,本文的 DCVC-DC 以更小的比特成本获得了更好的平均质量。
基于组的偏移多样性
在大多数现有的 NVCs 中,fTcontext 仅是单个 MV 的扭曲操作。这种基于单一运动的对齐对复杂的运动或遮挡并不健壮。本文的 fTcontext 包括两个核心子模块:偏移预测和跨组融合。
偏移预测

跨组融合
在对每个组进行多个偏移并应用相应的掩码后,本文将在融合前对所有组进行重新排序。
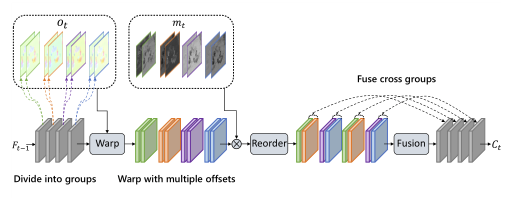
如图所示,重新排序前的特征以偏移顺序为主序,组序为次序。重新排序后组序为主序,偏移顺序为次序。后续的融合操作把每 N 个连续的组融合为一个组。因此,在此过程中,组重排序可以在不增加复杂性的情况下实现更多的跨组交互。该设计与传统编解码器中不同参考帧的加权预测具有相似的优点。通过跨组融合,引入更多不同组的时间上下文提取组合,进一步提高偏移多样性的有效性。
基于四叉树分区的熵编码
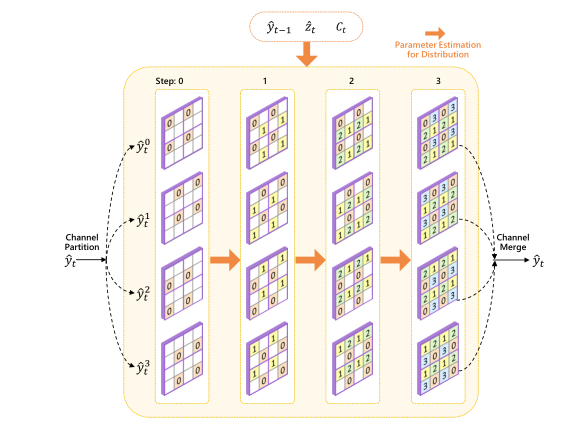
本文将 y^t 沿着通道维度分成四组,将每组在空间维度上划分为不重叠的 2×2 斑块。整个熵编码分为四个步骤,每步编码与图中相应指标相关联的不同位置。第 0 步,同时对所有斑块中索引为 0 的位置进行编码。对于四组,索引为 0 的位置是不同的。因此,对于每个空间位置,有四分之一的通道(即一组)被编码。在随后的第 1 步、第 2 步和第 3 步中,使用之前步骤中编码的所有位置来预测当前步骤中编码的位置的概率质量函数(PMF),并且在每一步中为不同的组编码不同的空间位置。
在此过程中,利用了更多样化的邻居。如果考虑一个位置的 8 个空间邻居,如果不考虑边界区域,自回归模型对每个位置使用 4 个(左、左上、上、右上)邻居。棋盘和双空间模型分别为第 0 步和第 1 步使用 0 和 4 个(左、上、右、下)邻居。相比之下,本文的 DCVC-DC 在这四个步骤中分别使用 0、4、4 和 8 个邻居。平均而言,DCVC-DC模型的邻居数是棋盘和双空间模型的 2 倍,与自回归模型相同。然而,本文的模型比自回归模型更省时,因为每个步骤中的所有位置都可以并行编码。
此外,本文的模型还利用了跨通道相关性。例如,在第三步中,对于一组的一个特定位置,相同位置的其他通道已经在前几步中从不同的组中编码,并且它们可以用作该步骤中熵建模的上下文。这有助于进一步压缩冗余。
总的来说,本文基于四叉树分区的解决方案使熵编码受益于细粒度和多样化的上下文,它充分挖掘了空间和信道维度的相关性。
实验
实施细节
- 在基本块设计中广泛使用深度可分卷积来代替正态卷积,以降低计算成本,同时缓解过拟合问题;
- 对不同分辨率的特征使用不相等的通道数设置,为低分辨率特征( yt )分配较大的通道数 (128) 以增加潜在的表示能力,为高分辨率的特征( Ct , Ft )分配较小的通道数 (48) 用于加速;
- 将部分量化操作移动到编码器中更高的分辨率,这有助于实现更精确的位分配。编码和量化的协调也带来了一些压缩比的提高。
实验设置
训练数据集集为 Vimeo-90k。YUV420 视频的测试集为 HEVC B ~ E ,UVG 和 MCL-JCV。RGB 视频的测试集除了 HEVC RGB 数据集,还使用 BT.709 将 YUV420 视频的测试集从 YUV420 转换为RGB 格式。每个视频测试96帧,内周期设置为32。
本文采用多阶段培训策略。本文的模型还支持单个模型中的可变比特率,因此在不同的优化步骤中使用不同的 λ 值。本文使用 4 个 λ 值(85、170、380、840)。但与在损耗中使用恒定失真权重不同,本文建议对失真项使用 wt上的分级权重设置。考虑到本文的训练集 Vimeo-90k 每个视频只有 7 帧,本文参考了传统的编解码器设置,将模式大小设置为 4。4 个连续帧的权重设置为(0.5、1.2、0.5、0.9)。
实验结果
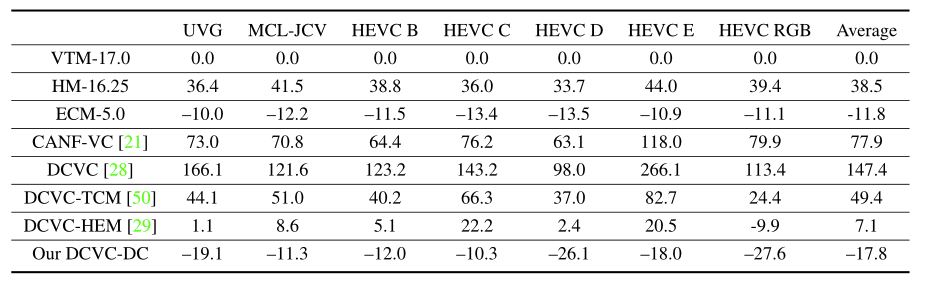
以上两个表格分别显示了 RGB 视频在 PSNR 和 MS-SSIM 方面的 BD-RATE 比较。在 PSNR 上,本文的编解码器在每个数据集上都比 VTM 实现了显著的压缩比改进,并且平均节省了 17.8% 的比特率。与 ECM 相比,仍然平均节省 6.4% 的比特率。
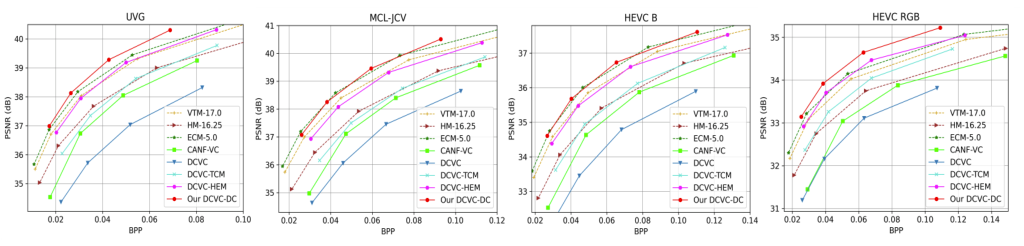
从率失真曲线中可以看出,本文的 DCVC-DC 在宽比特率范围内实现了更好的 SOTA 压缩比。
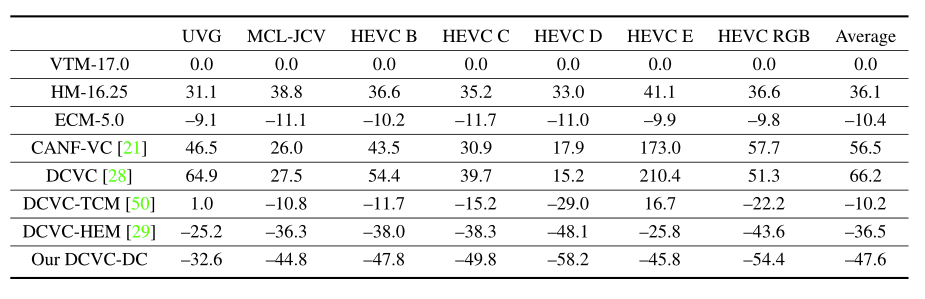
当使用 MS-SSIM 作为质量度量时,DCVC-DC 显示出更大的改进。DCVC-DC 比 VTM 平均节省 47.6% 的比特率。相比之下,ECM 超过 VTM 的相应数值仅为 10.4%。
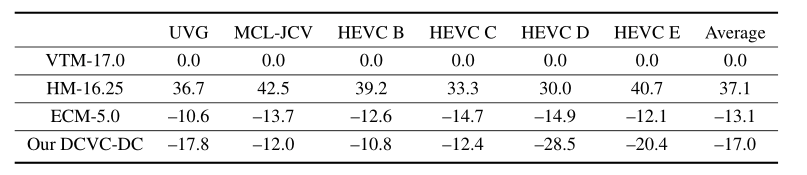
上表为 YUV420 视频在 PSNR 方面的 BD-RATE 比较。可以看到,DCVC-DC 比 VTM 平均节省 17.0% 的比特率。如果只考虑 Y 分量,平均可以节省 15.3% 的比特率。更好的是,DCVC-DC 在 YUV420 中的平均性能也优于 ECM。这是 NVC 发展的一个重要里程碑。
值得注意的是,本文的编解码器对 RGB 和 YUV420 颜色空间使用相同的网络结构,在训练期间只使用不同的微调。这显示了 DCVC-DC 在不同输入颜色空间的优化上的简单性和强大的可扩展性。
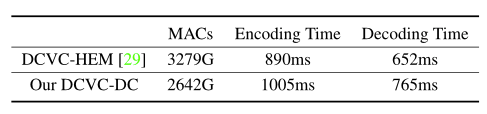
复杂度方面,本文的 DCVC-DC 的 MAC 比 DCVC-HEM 降低了 19.4% ,但实际的编码和解码时间更高。这是因为在相同 MAC 条件下,目前深度卷积的计算密度还没有正常卷积高。但通过定制化优化,可以在未来进一步加速。从另一个角度来看,考虑到 DCVC-DC 比之前的 SOTA DCVC-HEM 节省了 23.5% 的比特率,这样的运行时间增加程度是值得付出的代价。相比之下,ECM 比其前身 VTM 节省了 13.1%,但编码复杂度是 VTM 的 4 倍多。
展望
在训练过程中,为了学习分层质量模式,本文仍然使用与传统编解码器类似的固定失真权值。这可能不是 NVC 的最佳选择。实际上,强化学习很擅长解决这类时间序列的权重决策问题。在未来,可以对利用强化学习来帮助 NVC 在考虑时间依赖性的情况下做出更好的权重决策进行研究。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。