
个性化生成已成为生成领域的重要需求之一,然而微调大模型的成本是很高的。为了克服这个困难,本文提出了 HyperDreamBooth——一种能够从单个人脸图像高效生成一组个性化权重的超网络。通过将这些权重组合到扩散模型中,再加上快速微调,HyperDreamBooth可以生成各种背景和风格下的人脸,不仅保留了参考人脸的信息,同时还保留了模型对不同风格和语义修改的关键知识。这个方法在大约 20 秒内实现了人脸个性化生成,比 DreamBooth 快 25 倍,比Textual Inversion 快 125 倍,此外,这个方法的参数量比普通 DreamBooth 模型小约10000 倍。
作者:Nataniel Ruiz 等
论文题目:HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
论文链接:https://arxiv.org/abs/2307.06949
内容整理:王怡闻
相关工作
Dreambooth
之前,谷歌提出了一种个性化(Personalization)的文本到图像扩散模型DreamBooth,用户只需提供 3~5 个样本+一句话,AI就可以为参考图片中的主体定制各种风格、背景的图片。
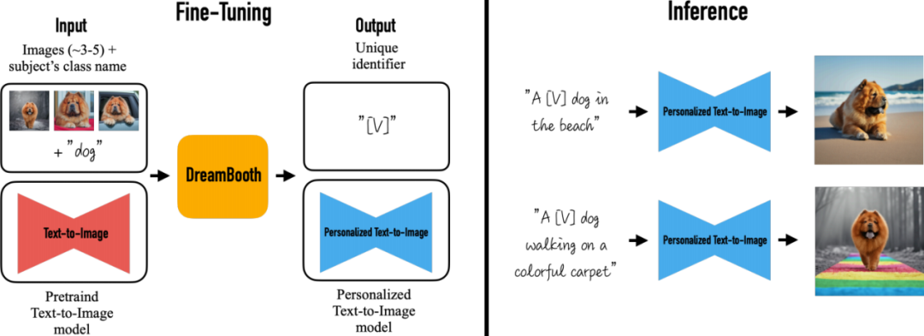
原来的Dreambooth方法的主要思路是:给定3~5张参考图片,和这组参考图片里的主体的类别,dreambooth会根据这些信息微调一个已经预训练好的大模型,在微调过程中,模型会学习这组参考图片中的主体和一个特殊标识符之间的概念绑定。在推理过程中,只需要将这个唯一标识符和类别组合在一起,微调后的模型就可以根据你caption中指定的内容将之前参考图片里面的主体生成到不同背景或者是不同风格的图片中。
Lo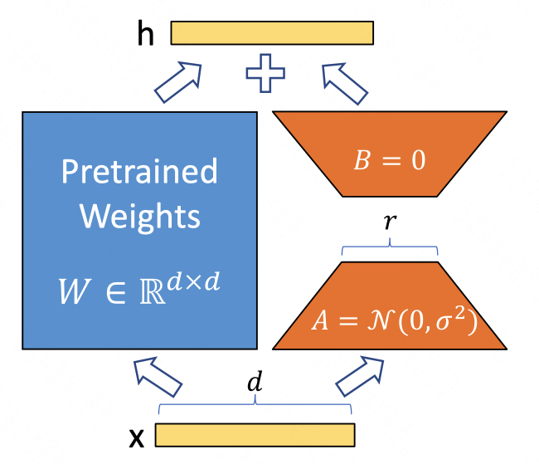
但由于预训练模型参数过多,就算是微调训练成本也很高,这也是当时大部分的微调方法的一个通病。LoRA原本是为了解决大语言模型比如GPT微调成本太大所提出的方法,后来被借用到了图像生成领域。它的主要思路是在固定预训练的大网络的参数,并训练某些层(在扩散模型中是self、cross attention层)参数的增量,且这些参数增量可通过矩阵分解变成更少的可训练参数,大大降低finetune所需要训练的参数量。比如在这个图里面预训练的模型尺寸是d*d,在训练的时候我们不调整预训练的模型,转而在旁边并联接入另外一个模型,这个模型就是LoRA。我们将LoRA进行矩阵分解,只要这个r远远小于d,那参数量就会大幅下降。在推理时把预训练的结果和LoRA模型的结果加到一起就是当前层的最终输出。
方法
轻量级 Dreambooth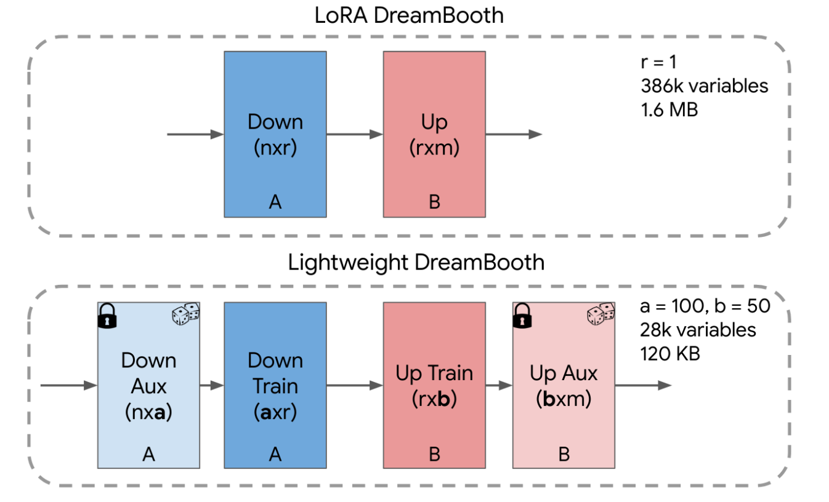

在Dreambooth的LoRA版本中,把中间收缩的尺寸r=1。Hyperdreambooth分别对LoRA的这两个部分进行了进一步的分解。如图,把Down(这里称为A)模块分解成了两部分:辅助块和训练块。辅助块不参与训练,用行正交向量随机初始化。Up模块也是同样,最后需要训练的只剩下A_train和B_train模块,参数量进一步减少。
超网络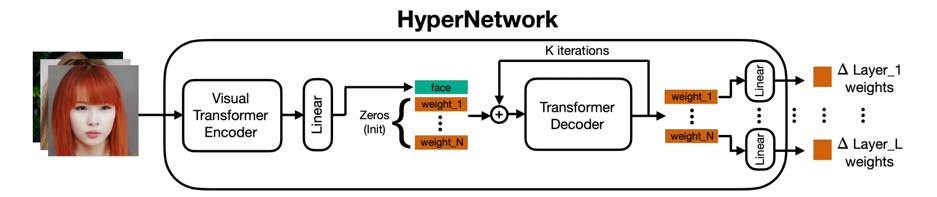
为了学习这些可训练模块的参数,Hyperdreambooth提出用一个用超网络来预测这些模块的权重。这个超网络的输入是参考图片和这些图片的类别(和dreambooth一样),它的输出是上面提到的这些A_train、B_train层的权重。
超网络分成两个部分,前半部分由Visual Transformer组成,用的模型结构是VIT-H,后半部分由Transformer Decoder组成。输入一组参考图片,ViT提取图片中的人脸特征向量f,然后和N个权重向量加到一起作为decoder的输入,这些权重向量由0初始化,decoder解码得到N个预测过后的权重向量,这个解码过程会迭代K次。
超网络的训练过程如上图所示,loss由两部分组成:一个是扩散模型输出图片和参考图片的重建loss,一个是预测的权重和ground truth的权重之间的loss。这里的ground truth权重就是用参考图片对模型进行普通微调得到的权重。通过最小化这两个loss去更新hypernetwork的参数。
快速微调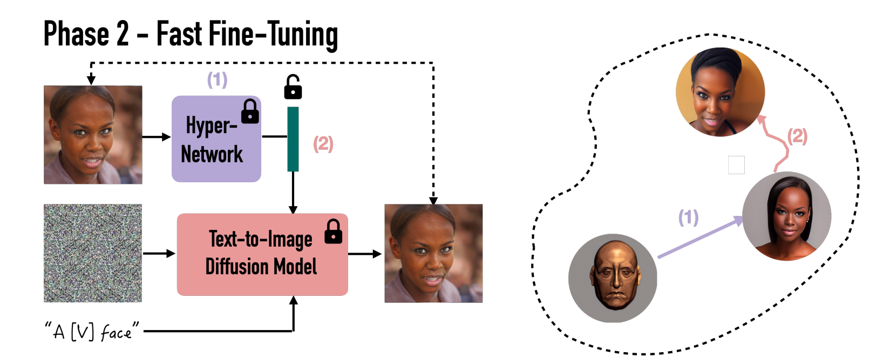
文章发现超网络预测生成了具有与目标人脸相似的语义属性(性别、头发、肤色等)的人脸。然而,细节并没有被充分捕捉。所以在超网络预测之后又加入了一个fast finetuning的步骤。在这个步骤里固定hypernetwork和预训练大模型的权重,再接入一个LoRA块进行快速训练,训练约40轮。这里的一个细节是:之前我们说的LoRA版dreambooth里的r=1,但在fast finetuning的过程中这个r是大于1的,这样的设计可以让模型更充分地捕捉人脸细节。
实验
与其他方法的对比
在量化实验中,文章选取了四个指标:Face Recognization用以衡量人脸保真度;DINO、CLIP-I衡量生成图片与参考图片的主体一致性、CLIP-T衡量生成图片与文字提示的语义一致性。可以看出,HyperDreambooth具有优势。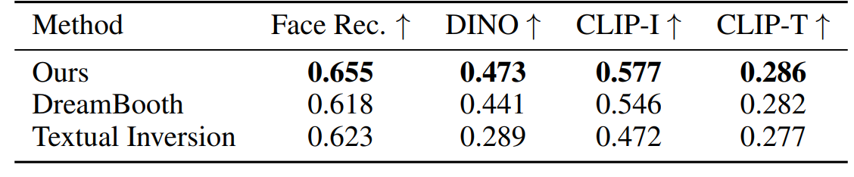
消融实验
在可视化以及量化消融实验结果后,我们可以看出超网络预测、快速微调、K次迭代等设计都能提高模型效果。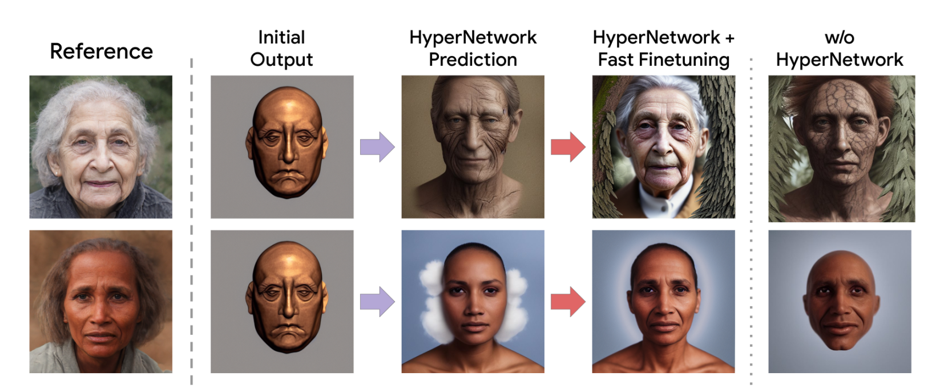
结论
这项工作提出了 HyperDreamBooth,一种用于文本到图像扩散模型的快速、轻量级的个性化生成方法。这个方法利用 HyperNetwork 为扩散模型生成轻量级 DreamBooth (LiDB) 参数,并进行后续的快速微调,与 DreamBooth 和其他个性化生成工作相比,实现了模型参数和推理时间的显著减小。通过实验可以证明,这个方法可以生成不同风格和不同语义修改的高质量、多样化的面部图像,同时保留人脸细节和语义完整性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。