

研究意义
在视频理解任务中,视频片段定位是一个新兴且极具挑战的任务。给定一个自然语言描述的查询和一个未裁剪的视频,视频片段定位需要在这个未裁剪的长视频中找到符合这个描述的视频片段,并给出该片段的起止时刻。
视频中通常包含复杂的运动背景和复杂运动语义信息,且自然语言描述蕴含了丰富的文本信息,这使得该任务很具有挑战。如图1,现有的工作可以分为基于动作提名(proposal-based)和无动作提名(proposal-free)两大类。在本文中,我们基于无动作提名网络的架构,提出了一个新颖的片段边界回归方式,即使用一个可学习令牌来直接预测视频片段的起止时刻。
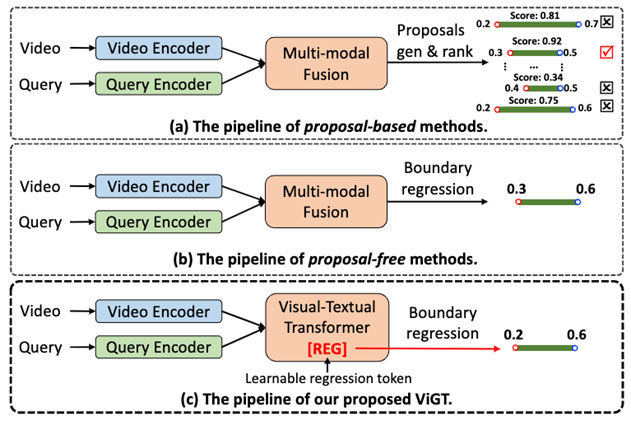
本文工作
如图2所示,本文提出了一个基于可学习令牌的视频片段定位网络,该网络主要由视频-语言编码器、视觉-语言Transformer和定位头三部分组成。
- 首先,视频-语言编码器主要负责文本查询和视频的特征编码;
- 然后,视觉-语言Transformer使用一个可学习令牌[REG]和视频-文本特征作为输入,使得令牌[REG]能够学习到视频和文本查询到关系;
- 最后,令牌[REG]被送到定位头来直接预测动作片段的起止时刻。
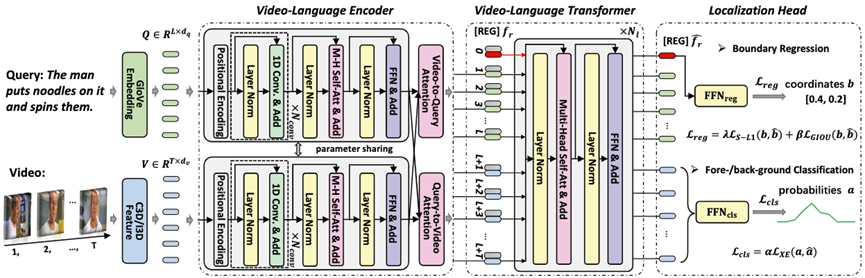
本文的创新点如下:
(1) 我们在视频片段检索上考虑了可学习令牌的概念,提出了一个简单但有效的无提名的基于Transformer的框架,该框架隐式地捕捉视频和文本查询之间的关系。
(2) 本文所提出的方法是以无提名的方式实现的,它通过可学习的令牌预测目标时刻,与以前的工作中通过多模态或跨模态特征预测目标时刻是不同的。
(3) 在三个基准数据集上进行了广泛的实验,并证明了所提出方法的有效性。消融研究和可视化分析也验证了每个组件的贡献。
实验结果
本文所提出的基于可学习令牌的网络框架在公开的三个数据集上进行了实验验证,均取得了较好的实验结果。
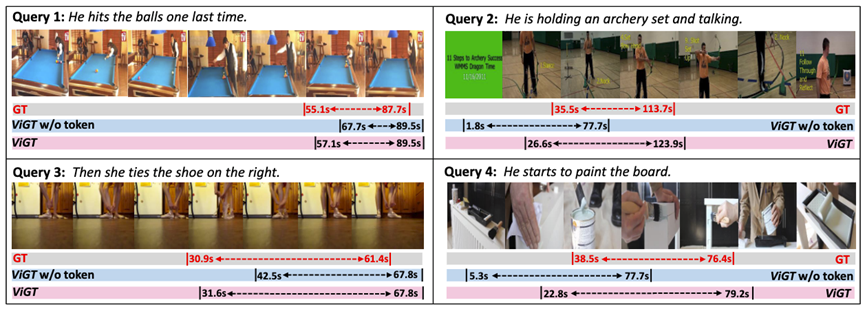
如图3所示,本文对ActivityNet Captions数据集上的一些预测结果进行了可视化,结果表明,本文所提出的方法ViGT比不使用可学习令牌的方法(ViGT w/o token)预测的片段边界时刻更精准,这也验证了可学习令牌能够有效地聚合视频和文本查询的全局语义信息。
文章信息
Kun LI, Dan GUO & Meng WANG. ViGT: proposal-free video grounding with a learnable token in the transformer. Sci China Inf Sci, doi:10.1007/s11432-022-3783-3
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
