
实时声学效果的建模和渲染是非常密集的计算。如果没有复杂和昂贵的硬件,就很难呈现出真实的声学效果。对真实或虚拟场景的声学特性进行建模,同时允许声源和听者的移动,这是一个困难的问题,特别是对于复杂的场景。
在名为“Parameterized modeling of coherent and incoherent sound”的专利申请中,微软就介绍了一种声音的参数化建模。
在对场景的声学效果进行建模时,需要考虑的一个重要因素是声音到达听者处的延迟。一般来说,听者收到声波的时间会向听者传达重要的信息。
例如,对于一个由声源引入场景的给定的波脉冲,压力响应到达听者的时候是一系列的峰值,每个峰值都代表了声音从声源到听者的不同路径。每个峰值的时间、到达方向和声能都取决于各种因素,如声源的位置、听者的位置、场景中结构的几何形状以及结构的组成材料。
听者倾向于将脉冲响应中第一个到达的峰值的方向视为声音的到达方向,即使随后不久几乎同时到达的峰值来自不同方向。
在给定的场景中,这个初始声音可以采取最短的路径通过空气从声源到听者。在最初的声音之后,会收到随后的相干反射(回声),而这种反射通常需要更长的路径,从场景中的各种表面反射出来,并随着时间的推移而变得衰减。另外,人类可以感知到混响噪声与初始声音和随后回声的共在一起。
一般来说,最初的声音往往能使听者感知到声音来自何处。随后的回声和/或混响往往为听者提供关于场景的额外信息,因为它们传达了方向性脉冲响应如何在场景内沿着许多不同的路径传播。
根据场景的属性,用户对回声的感知不同。作为一个例子,当声源和听者在附近时(例如,在脚步范围内),初始声音的到达和相应的第一个回声之间的延迟可以变得可听。初始声音和回声之间的延迟可以加强对墙壁距离的感知。
初始声音和随后的回声可以由具有相同频率和特定相位关系的相干声波产生,例如,相互之间的同相。另一方面,混响可以由具有许多不同频率和相位的不连贯声波产生。
微软的发明可以将声音信号分成相干和非相干部分,并为相干和非相干部分编码单独的参数集。这种单独的参数为后续渲染从不同声源位置到场景内不同听者位置的相干声音和非相干声音提供了基础。
一个减少渲染声音的计算负担的高级方法是预先计算声学参数,描述声音如何从不同的声源位置传播到给定的虚拟场景中的不同听者位置。一旦声学参数预先计算出来,只要场景不改变,它们就不变。
在给定场景中对声音进行参数化的一个简化假设是,为初始声音、反射和混响指定不同的非重叠时间段。初始声音可以在第一时间段模拟为相干声音,相干反射可以在第二时间段模拟为相干声音,而混响可以在第三时间段模拟为衰减噪声。
这种方法可以为特定应用提供足够的保真度,同时提供紧凑的编码,因为初始声音和相干反射倾向于主导对早期到达听者的声音的感知,而混响倾向于主导对后来到达的声音的感知。
但如前所述,人类可以同时感知相干的和不相干的声波。换句话说,人类可以感知混响噪声与初始声音和相干反射一起。特定应用可能会受益于更精确的声音建模,在同一时间段内一起再现相干和不相干的声音。
请注意,相干声音信号和非相干声音信号可以有非常不同的特性,随着声源和听者在场景中的位置而变化。从全脉冲响应压力信号中提取参数的方法可能无法准确表示相干和非相干声音信号的不同特征。
微软表示,通过将脉冲响应压力信号分割成独立的相干和非相干成分,他们的解决方案可以解决所述问题,并为各种应用产生令人信服的声音。可以为相干和非相干成分推导出单独的参数集,从而使相干和非相干声音成分的保真度更高,可以同时呈现相干和非相干声音成分。
通过在参数提取之前将声音信号分离成相干和非相干成分,用于表示相干声音的第一参数可以从相干声音信号成分中导出,其中非相干声波的声能相对较少,而用于表示非相干声音的第二参数可以从非相干声音信号成分中导出,其中非相干声波的声能相对较少。
因此,所述方案为准确建模和渲染声学效果提供了计算效率高的机制。一般来说,可以使用代表声音在场景内不同声源和听者位置的感知参数对给定场景进行建模。一旦获得特定场景的感知参数,感知参数可用于渲染从场景中任意声源和听者位置传播的声音。
如前所述,可以预先计算场景的声学参数,然后在运行时使用预先计算的信息来渲染声音。一般来说,预计算的声学参数可以认为是 “感知 “参数,因为它们描述了声音是如何被场景中的听者感知,这取决于声源和听者的位置。
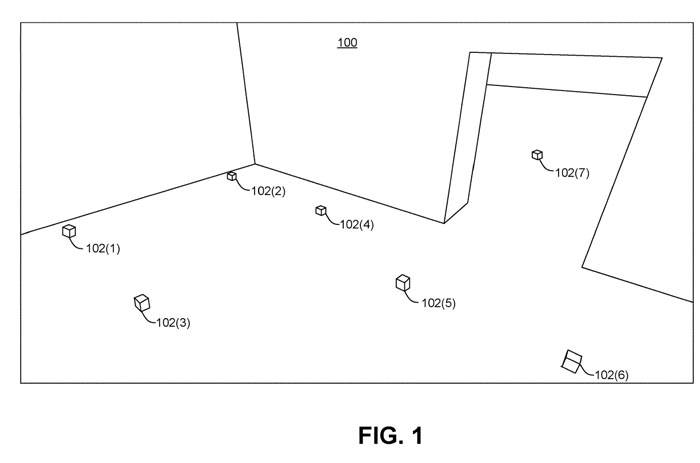
为了确定一个给定的虚拟场景的感知参数,可以在不同的位置部署声学probing。图1显示了probing场景100的一个例子。单个probe 102(1)-102(7)部署在整个场景的各个位置。
可以采用模拟方法来模拟声音在给定场景中选定位置之间的传播。例如,声源可以部署在给定的声源位置,每个probe可以作为相应probe位置的听者。在一个实施例中,声源可以部署在大约一立方米的方形体素的三维网格中,每个体素有一个声源。
可以对场景中的每个声源和听者probe的组合进行模拟。例如,可以采用波模拟来模拟场景中的声学衍射。波浪模拟可用于确定听者在场景中不同位置对声音的感知,这取决于声源的位置。
然后,可以存储代表这一信息的感知声学参数。例如,感知声学参数可以包括代表从声源位置到听者位置的相干信号特征的第一感知参数,以及代表从声源位置到听者位置的非相干信号特征的第二感知参数。
如前所述,每个probe都可以用来预先计算与相干和不相干声音在被探测位置被听者感知的不同特征有关的声学参数。
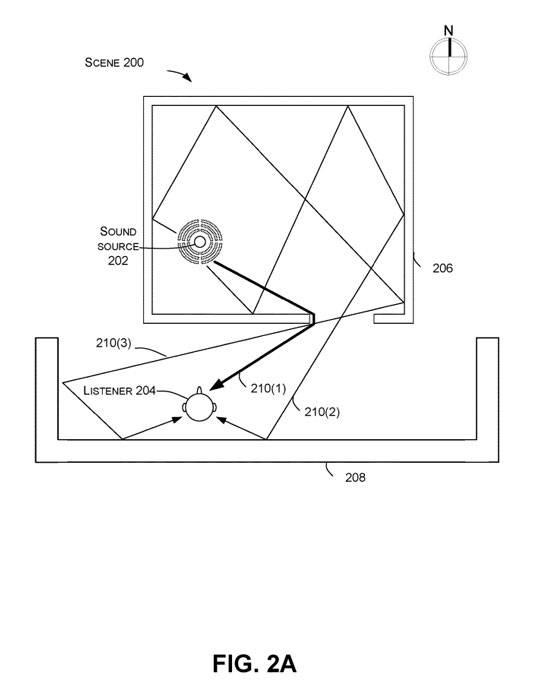
图2A说传达了与声音在场景200中的传播有关的概念。在本例中,声音由声源202发出,并由听者204根据场景200的声学特性进行感知。例如,场景200可以有基于场景内结构的几何形状以及结构的材料的声学特性。
一般来说,声源202可以产生声音脉冲,产生相应的方向性脉冲响应。方向脉冲响应取决于场景200的属性,以及声源和听者的位置。方向脉冲响应中第一个到达的峰值通常被听者204感知为初始声音,而方向脉冲响应中随后的峰值往往被感知为回声。
一个给定的声音脉冲可以产生许多不同的声音波面,从源头向各个方向传播。图2显示了三个相干的声音波阵210(1),210(2)和210(3)。
由于场景200的声学特性以及声源202和听者204各自的位置,听者认为初始声波阵210(1)是从东北方向传来的。例如,在基于场景200的虚拟现实世界中,一个人着右边有门洞的墙,很可能期望听到来自他们右边的声音,因为墙206衰减了沿声源和听者之间视线传播的声能。
听者204所感知的声音同时可以包括初始声音波阵之后的声音波阵210(2)和210(3)。这三个波面中的每一个都可以包括在不同时间和不同地点到达用户的相干声音。
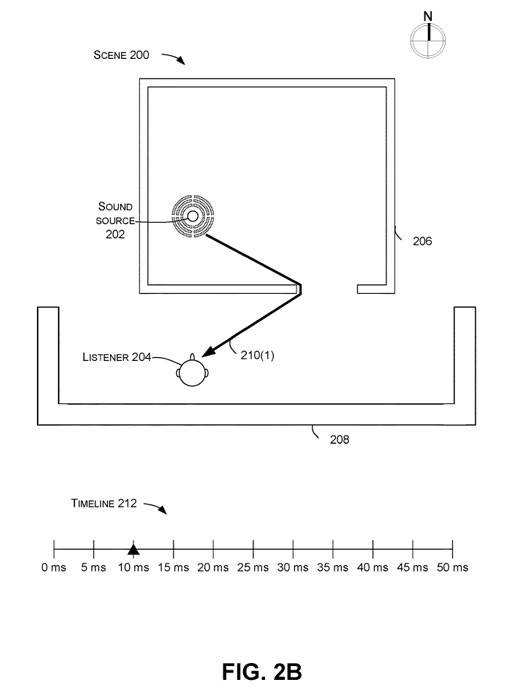
图2B、2C和2D分别说明了声音波面210(1)、210(2)和210(3),以显示它们如何在不同时间到达听者204。图2B显示了在声音由声源202发出后约10毫秒时,声音波面210(1)到达听者处,正如时间轴212所传达的那样。
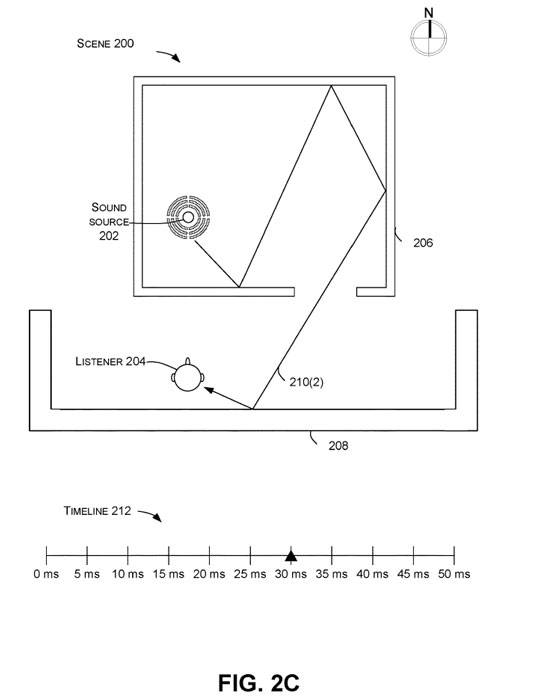
图2C显示了在声源202发出声音后约30毫秒到达听者处的声音波前210(2),如时间线212所传达的。图2C显示在声源202发出声音后约37.5毫秒时,声音波前210(3)到达听者处,如时间线212所传达的。
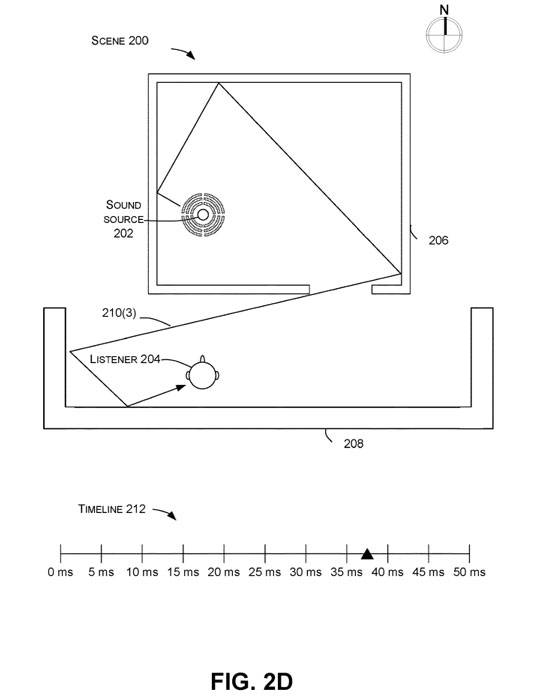
图3中说明了第一个示例系统300。系统300可以包括一个参数化声学组件302。参数化声学组件302可以在一个场景上运行,如虚拟现实空间304。
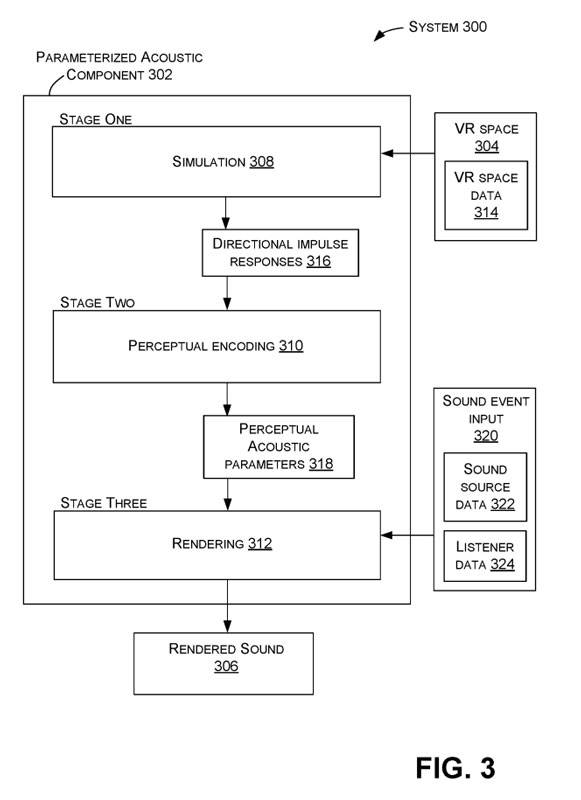
在系统300中,参数化声学组件302可用于为虚拟现实空间304产生逼真的渲染声音306。在图3所示的例子中,参数化声学组件302的功能可以组织成三个阶段。
例如,阶段一可以与模拟308有关,阶段二可以与感知编码310有关,阶段三可以与渲染312有关。阶段一和阶段二可以作为预计算步骤实施,而阶段三可以在运行时执行。
在图3中,虚拟现实空间304可以有相关的虚拟现实空间数据314。参数化声学组件302可以操作和/或产生方向性脉冲响应316、感知声学参数318和声音事件输入320,其中可以包括与虚拟现实空间304中的声音事件有关的声源数据322和/或听者数据324。在这个例子中,渲染的声音306可以包括相干和不相干的成分。
如图3中的例子所示,在模拟308(阶段一),参数化声学组件302可以接收虚拟现实空间数据314。虚拟现实空间数据314可以包括虚拟现实空间304中的几何图形(例如,结构、物体的材料、门户等)。
例如,虚拟现实空间数据314可以包括虚拟现实空间304的体素图,体素图映射几何图形,包括虚拟现实空间304的结构和/或其他方面。
模拟308可以包括虚拟现实空间304的声学模拟,以预先计算相干和非相干声学参数的场。更具体地说,模拟308可以包括使用虚拟现实空间数据314生成方向性脉冲响应316。方向脉冲响应316的压力和三维速度信号可以分成相干和非相干部分,感知声学参数可以从每个部分得出。
为虚拟现实空间304编码感知声学参数318的一种方法是为可能的源和听者位置的每一个组合,例如每一对体素,生成方向性脉冲响应316。在确保完整性的同时,以这种方式捕捉虚拟现实空间的复杂性可能会导致产生PB级的波场。
专利的技术为使用相对紧凑的表示法进行计算效率高的编码和渲染提供了解决方案。
如上所述,方向性脉冲响应316可以根据部署在虚拟现实空间304内特定听者位置的probe来生成。图1中显示了probe的例子。这比在每个潜在的听者位置取样涉及的数据存储要少得多。
probe可以在虚拟现实空间304内自动布置,并且/或者可以自适应采样。例如,probe可以在场景几何形状局部复杂的空间中更密集地定位,而在宽阔的空间(例如,户外场地或草地)更稀疏地定位。
如图3所示,在第二阶段,可以对第一阶段的方向脉冲响应316进行感知编码310。感知编码310可以与模拟308合作,并进行流式编码。
在这个例子中,知觉编码过程可以接收和压缩单个方向脉冲响应,因为它们是由模拟308产生。与方向性脉冲响应不同,感知参数往往相对平滑,这使得使用这种技术的压缩更加紧凑。总的来说,以这种方式对参数进行编码可以大大减少存储费用。
一般来说,感知编码310可以涉及从定向脉冲响应316中提取感知声学参数318。参数通常代表来自不同声源位置的声音在不同听者位置的感知。例如,一个给定的源/听者位置对的感知声学参数可以包括第一感知参数,代表从源位置到听者位置的相干信号的特征,以及代表从源位置到听者位置的不相干信号的特征的第二感知参数。
以这种方式对感知声学参数进行编码,可以产生一个可管理的感知声学参数的数据量,例如,在一个相对紧凑的数据文件中,以后可以同时用于相干和非相干声音的计算效率渲染。
如图3所示,在第三阶段,渲染312可以利用知觉声学参数318来渲染声音。如上所述,感知声学参数318可以提前获得并存储,例如以数据文件的形式。声音事件输入320可以被用来根据感知声学参数在场景中渲染声音
一般来说,图3所示的声音事件输入320可以与虚拟现实空间304中产生声音响应的任何事件有关。一个给定的声音事件的声源数据322可以包括一个运行时声源的输入声音信号和运行时声源的位置。同样地,听者数据324可以传达一个运行时听者的位置。
在一个实施例中,声音可以使用轻量级信号处理算法进行渲染。轻量级信号处理算法可以以一种在很大程度上对声源和/或声音事件的数量的计算成本不敏感的方式渲染声音。
输入事件的声源数据可以包括输入信号。输入信号可以有多个频率分量和相应的幅度和相位。输入信号可以在运行时听者位置使用相干和非相干分量的单独参数集进行渲染。
相关专利:Microsoft Patent | Parameterized modeling of coherent and incoherent sound
名为“Parameterized modeling of coherent and incoherent sound”的微软专利申请最初在2021年12月提交,并在日前由美国专利商标局公布。
原文链接:https://news.nweon.com/110377
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
