
在本文中,研究者的目标是实现从一个真实或人工生成的单张图像中创建高保真度的3D内容。该方法可以为像Stable Diffusion这样的前沿2D生成模型创建的幻想图像带来3D效果。
来源:Arxiv
作者:Junshu Tang,Ran Yi
论文链接:https://arxiv.org/pdf/2303.14184.pdf
内容整理:桂文煊
Introduction
本文探讨了仅使用单张图像创建高保真度3D内容的问题。这本质上是一项具有挑战性的任务,需要估计潜在的3D几何结构,并同时产生未见过的纹理。为了解决这个问题,论文利用训练好的2D扩散模型的先验知识作为3D生成的监督。论文的方法名为:Make-It-3D,采用两阶段优化pipeline:第一阶段通过在前景视图中结合参考图像的约束和新视图中的扩散先验来优化神经辐射场;第二阶段将粗略模型转化为纹理点云,并利用参考图像的高质量纹理,结合扩散先验进一步提高逼真度。该方法可用于text-to-3D的创建和纹理编辑等各种应用。
Contribution
论文的主要贡献总结如下:
1、论文提出了Make-It-3D框架,使用2D扩散模型作为3D-aware先验,从单个图像中创建高保真度的3D物体。该框架不需要多视图图像进行训练,并可应用于任何输入图像,无论是真实的还是生成的。
2、通过两个阶段的创建方案,Make-It-3D是首个实现普适对象高保真3D创建的工作。生成的3D模型展现出精细的几何结构和逼真的纹理,与参考图像相符。
3、除了图像到3D创建之外,论文的方法还能实现高质量text-to-3D创建和纹理编辑等多种应用。
Methods
论文利用了文本-图像生成模型和文本-图像对比模型的先验知识,通过两阶段(粗糙阶段和优化阶段)的学习来还原高保真度的纹理和几何信息,所提出的两阶段三维学习框架如图1所示。
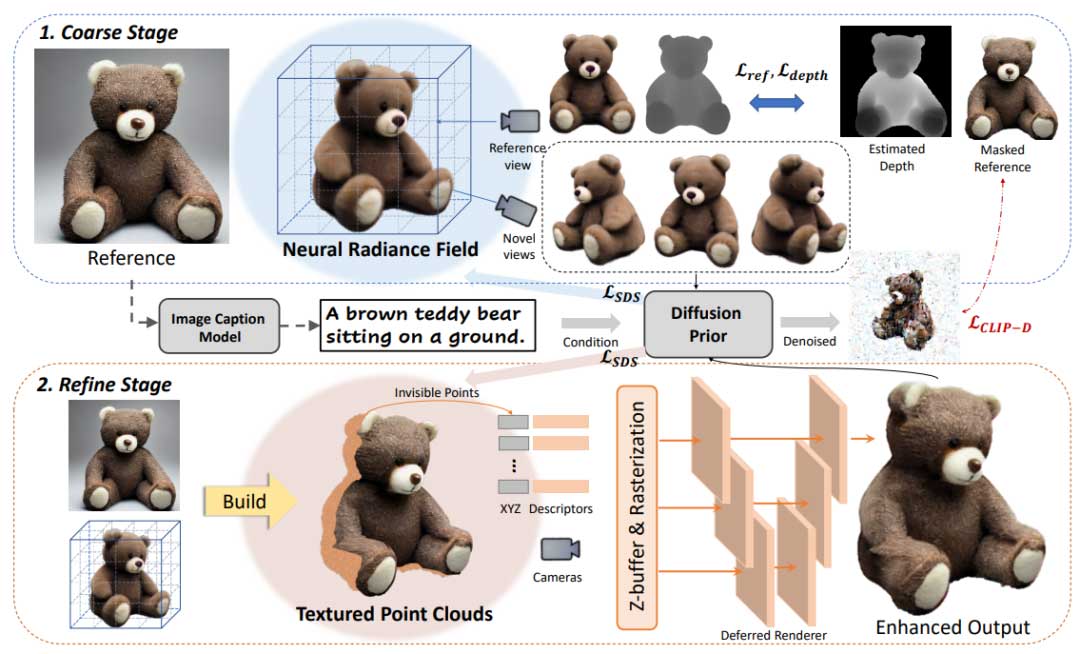
粗略阶段:单视图 3D 重建
作为第一阶段,论文从单一参考图像重建一个粗糙的NeRF,以扩散先验约束新的视角。优化的目标是同时满足以下要求:
1、优化后的三维表示应该与输入观测x在参考视图上的渲染结果非常相似
2、新视图渲染应该显示与输入一致的语义,并尽可能可信
3、生成的3D模型应该表现出引人注目的几何形状
所以论文对相机姿态进行随机采样,并且采取以下loss进行模型的训练:
1、Reference view per-pixel loss
优化后的三维表示应该与输入观测x在参考视图上的渲染结果非常相似,因此惩罚NeRF渲染图像和输入图像之间的像素级差异。其中使用前景matting mask来分割前景。
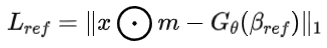
2、Diffusion prior
新视图渲染应该显示与输入一致的语义,为了解决这个问题,论文使用一个图像字幕模型,为参考图像生成详细的文本描述。有了文本提示,可以在Stable Diffusion的潜空间上执行式中loss,度量图像和给定文本提示符之间的相似性。
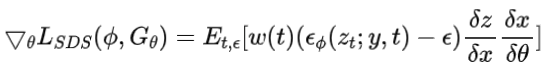
虽然上述loss可以生成忠实于文本提示的3D模型,但它们并不能与参考图像完全对齐,因为文本提示不能捕获所有的对象细节。因此,论文额外添加一个扩散CLIP损失,它进一步强制生成的模型来匹配参考图像。
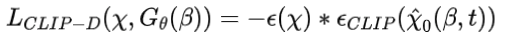
3、Depth prior
此外,模型仍然存在形状模糊,从而导致诸如凹陷面、过平面几何或深度模糊等问题。为了解决这个问题,论文使用一个现有的单目深度估计模型来估计输入图像的深度 。为解释不准确性和尺度不匹配,论文正则化了NeRF在参考视点上的估计深度和单目深度之间的negative Pearson correlation。
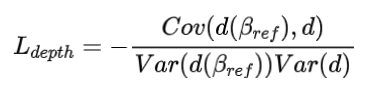

优化阶段:神经纹理增强
在粗略阶段,我们获得了一个具有合理几何形状的3D模型,但通常显示出粗糙的纹理,可能会影响整体质量。因此,需要进一步细化以获得高保真度的3D模型。
论文的主要思路是在保留粗糙模型几何形状的同时,优先进行纹理增强。我们利用新视角和参考视角中可观察到的重叠区域来将参考图像的高质量纹理映射到3D表示中。然后,论文着重于增强参考视角中被遮挡区域的纹理。为了更好地实现这一过程,论文将神经辐射场导出到显式表示形式——点云。与Marching Cube导出的噪声网格相比,点云提供了更清晰和更直接的投影。
直接从NeRF渲染多视图RGBD图像并将其提升到三维空间中的纹理点的朴素尝试会产生噪声的点云,因为不同视角下的NeRF渲染可能会给同一3D点赋予不同的RGB颜色。为了解决这个问题,论文提出了一种迭代策略来从多视图观测中构建干净的点云。论文首先根据NeRF的渲染深度和alpha掩模从参考视图中构建点云,如图3所示。
对于其余视图的投影,必须避免引入与现有点重叠但颜色冲突的点。为此,论文将现有的点投影到新的视图中,以产生一个指示现有点存在位置的掩模。以这个掩模作为指导,论文只给现有的点云补充那些尚未观察到的点,如图3所示。然后用粗糙NeRF渲染的粗糙纹理初始化这些看不见的点,并集成到现有的密集点云中。
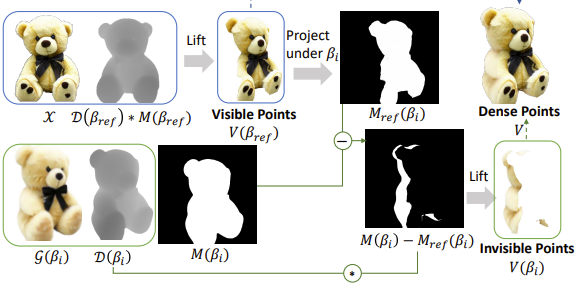
按照前文方法,虽然密集点云中的已经有了从参考图像投影出来的高保真纹理,但在参考视图中被遮挡的其他点仍然遭受了来自粗糙NeRF的平滑纹理,如图4所示。为了增强其他点的纹理以增强模型的视觉效果,论文优化了纹理,并使用扩散先验约束了新视图渲染。具体地,对于每个点,优化一个19维的描述符,其中前三个维度初始化为初始RGB颜色,并采用多尺度延迟渲染方案,使用一个U-Net渲染器联合优化来渲染特征图并得到最终图像。
实验及结果
论文与其他五种代表性baseline进行比较。分别为DietNeRF、SinNeRF、DreamFusion、Point-E、3D-Photo。


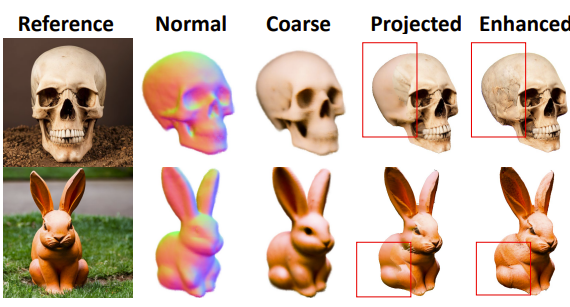
与三维生成baseline DreamFusion和DreamFusion+进行比较,如图5所示,它们生成的模型未能与参考图像完全对齐,同时具有平滑的纹理。相比之下,论文的方法产生了具有精细几何和逼真纹理的高保真度三维模型。
图6展示了关于新视角合成的额外比较。论文的方法在新视角下实现了非常准确的几何形状和观感不错的纹理。
总结
本论文介绍了Make-It-3D,这是一种新的两阶段方法,用于从一张图像创建高保真度的3D内容。利用扩散先验作为3D感知监督,生成的3D模型表现出忠实的几何形状和真实的纹理,并具有扩散CLIP损失和纹理点云增强。Make-It-3D适用于一般物体,可用于多种应用。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
