
体视频以3D形式捕捉动态场景,用户可以从任意角度观看,并获得丰富的体验。它是下一代媒体的基石,具有许多重要应用。与2D视频一样,体积视频应该能够进行高质量的实时渲染,并进行压缩以实现高效的存储和传输。因此,为体视频设计一个合适的表征方式来满足这些要求仍然是一个悬而未决的问题。目前许多已有的针对动态视频的重建方法的渲染速度太慢。基于提速的方法可以加速静态场景的渲染,但是对体视频而言所需要的空间太大。在本文中,作者提出了一个新颖的体视频的表征方式,名为Dynamic MLP Maps,以有效地对动态场景的进行视角合成。
具体来说,本文的主要贡献有:
- 一种新的volumetric video的表示方法,称为dynamic MLP maps,实现了紧凑的场景表示和快速推理
- 一种新的基于dynamic MLP maps的动态场景实时渲染 pipeline
- 在NHR和ZJU-MoCap数据集的渲染质量,速度和存储方面达到SOTA
方法
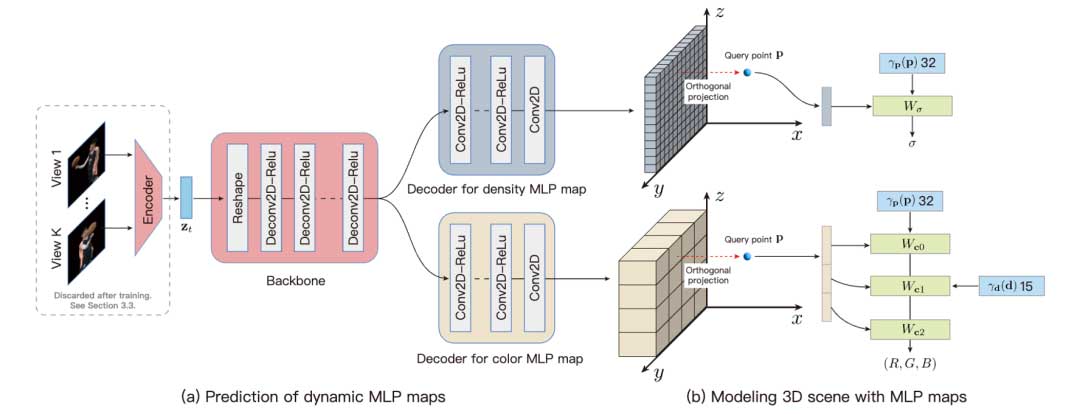
给定由同步和校准的摄像机拍摄的多视图视频,作者的目标是制作一个占用低磁盘存储并支持快速渲染的体视频。在本文中,作者为体积视频提出了一种称为dynamic MLP maps的新表征方式,并开发了一个用于动态场景实时视图合成的 pipeline。
使用 MLP maps 对 3D场景进行建模
一个 MLP maps 是一个 2D 网格图,其中每个像素存储一个 MLP 网络的参数。为了使用 MLP maps 表示 3D 场景,作者将任意 3D 点 p 投影到由 MLP maps 定义的 2D 平面上,以查询相应的 MLP 参数。实际上,作者将 MLP maps 与坐标系统的轴对齐,并且将点 p 正交投影到规范平面上,如图 1 所示。查询点投影后对应的参数将被作为参数动态加载到 MLP 网络中。其中,作者采用一个小的 NeRF 网络来预测查询点 p 的密度和颜色,该网络由单层密度头和三层颜色头组成。由 2D maps 编码的所有网络代表整个场景。由于每个 NeRF 仅描述目标场景的一部分,因此本文所提出的模型可以利用小的 MLP 达到高质量的渲染。与先前方法中使用的网络集相比,本文所提出的 MLP maps 基于 2D 平面的形式,能够使用 2D 卷积网络有效地生成 MLP 参数。
在预测点 p 的密度和颜色时,作者将输入坐标嵌入到高维特征向量中,以获得更好的性能,而不是直接将空间坐标传递到网络中。具体来说,定义了三个多级哈希表:hxy,hxz,hyz。每个哈希表的分辨率为 L x T x F,其中 L 是哈希表的级数,T 是表的大小,F 是特征维度。为了嵌入输入点 p,作者将其投影到三个轴对齐的正交平面上,使用三个多级哈希表将投影点转换为特征向量,并通过求和聚合三个特征向量。嵌入过程公式化为:

正交的 MLP maps
实验表明,在一个规范平面上定义 MLP maps 的场景建模难以提供良好的渲染质量。原因之一是场景内容沿某个轴可能是高频信号函数,这使得 MLP maps 难以拟合场景内容。在这种情况下,场景内容可能沿着另一个轴具有较低的频率。本文在三个轴对齐的正交平面上定义了三个 MLP maps。对于每个查询点,首先使用 MLP maps 来预测密度和颜色 (σi,ci)|i = 1,2,3,然后通过求和来聚合它们。
基于动态 MLP maps 的体视频
基于MLP map,作者使用一个 2D CNN 来表示体积视频。给定多视图视频,利用一个 2D CNN 来动态回归2D maps,其中包含每个视频帧的一组 MLP 参数,这些参数对对应时间下的 3D 场景的几何结构和外观进行建模。如图 1 所示,作者设定网络的架构为编解码器,其中编码器从相机视图回归潜在码,解码器基于潜在码生成 MLP maps。
具体来说,对于特定的视频帧,作者选择相机视角的一个子集,并利用 2D CNN 编码器将其转换为一个潜在码。潜在码被设计为对当前视频帧处的场景状态进行编码,并用于MLP图的预测。获得潜在代码的另一种方法是为每个视频帧预先定义可学习的特征向量。与之相比,使用编码器网络进行学习的优势在于,它隐式地在视频帧之间共享信息,从而实现视频序列的联合重建,而不仅仅是逐帧的学习。
给定一个潜在码,作者采用一个 2D CNN 解码器来预测 MLP maps。图 1 展示了 2D CNN 解码器的示意架构。将潜在码记为 z ∈ RD,作者首先使用全连接网络将 映射到 4096 维特征向量,并将得到的向量重塑为具有 256 个通道的 4 x 4 特征图。然后,具有一系列逆卷积层的网络将其上采样为更高分辨率 D x D 的特征图。基于特征图,随后的两个卷积网络分别用于预测密度和颜色 MLP maps。卷积网络由几个卷积层组成。通过控制卷积层的数量和步长,可以控制预测的 MLP maps 的分辨率。由于密度 MLP 比彩色 MLP 具有更少的参数,因此可以预测更高分辨率的密度 MLP maps,从而带来更好的性能。
加速渲染
本文的方法用一组小型 MLP 网络表示 3D 场景。由于这些 MLP 网络比 DyNeRF 的网络小得多,因此本文模型的网络推理所需的时间更少,使本文的方法比 DyNeRF 快得多。为了进一步提高渲染速度,作者引入了两种额外的策略。
首先,编码器网络可以在训练后丢弃。本文使用训练后的编码器来计算每个视频帧的潜在码,并存储产生的潜在码而不是每次都经过编码器网络得到,这节省了编码器的推理时间。
其次,本文通过跳过空白空间来减少网络查询的次数。为此,作者计算每个视频帧的低分辨率 3D 占用体,其中每个体素存储指示体素是否被占用的二进制值。占用体是从学习的场景表示中提取的。当评估的密度高于阈值时,我们将体素标记为已占用。由于占用量具有低分辨率并且以二进制格式存储,因此 300 帧视频的占用量仅占用大约 8MB 的存储空间。在推理过程中,网络推理仅在由占用量表示的占用区域上进行。实际上,我们将在颜色推理之前进行密度推理,以进一步减少颜色推理的次数。具体而言,首先推理占用体素内采样点的密度,用于计算体渲染中定义的合成权重。如果一个点的权重高于阈值,我们将预测其颜色值,否则我们将在体积渲染过程中跳过该点。
实验
本文的算法在 ZJU-MoCap 和 NHR 数据集上进行实验。
对比实验
与 Neural Volumes, C-NeRF, D-NeRF, DyNeRF 四种算法进行比较,在NHR数据集上的客观指标结果和渲染结果对比图分别如图 2 和图 3 所示;在ZJU-MoCap上的客观指标结果和渲染结果对比图分别如图 4 和图 5 所示。
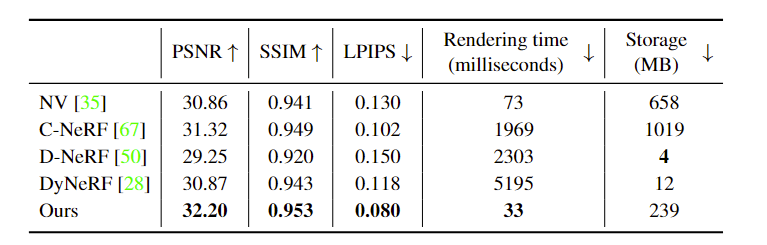

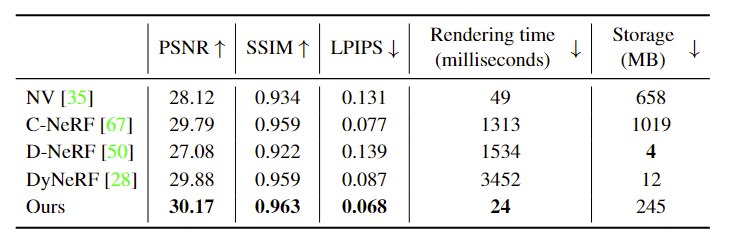

从渲染的结果可以看出本文所提出的方法对比其他方法具有最好的渲染质量以及最短的渲染时间,除此外,所需要的空间成本也相比于其他方法来说相对较小。
消融实验
本文对 MLP maps 的分辨率、MLP 的动态性、MLP maps的正交性以及跳过空白的渲染策略进行了分析。得到的结果如图 6 中的表格所示。
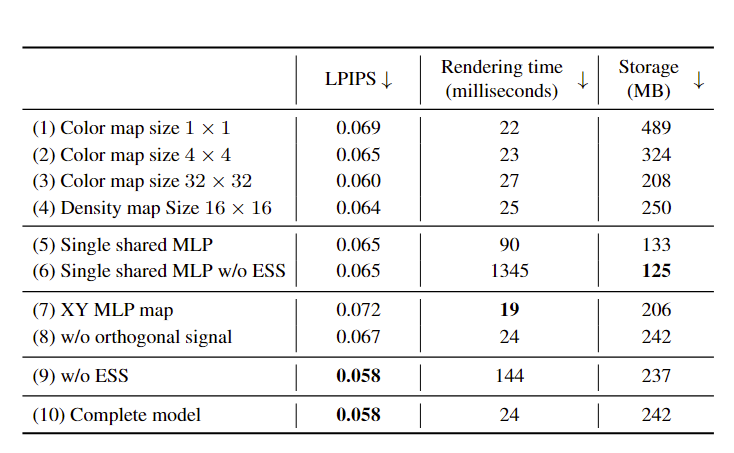
在 MLP maps 的分辨率方面可以看出:分辨率的降低会影响渲染性能,而增加分辨率并不一定能提高渲染质量。一个合理的解释是,由于分辨率的提高使模型更难训练。首先,MLP maps的分辨率越高,意味着需要优化的参数越多。其次,由于内存限制,增加分辨率需要减少在每次训练迭代期间输入到每种颜色 MLP 的查询点的数量,从而减少 batch 大小。此外,MLP maps的分辨率对渲染速度的影响不大。
在 MLP 的动态性方面,作者将动态MLP映射替换为用于所有视频帧的共享 MLP。除了输入是高维特征向量外,这一 MLP 网络实际上被实现为原始 NeRF 网络。可以看出本文的完整模型比具有单个共享 MLP 网络的模型具有更好的渲染质量和更快的渲染速度。此外,基于空白区域的跳过,具有单个共享 MLP 网络的模型的渲染速度大大提高,但它仍然比本文的模型慢得多。
在 MLP maps的正交性方面,不使用正交平面而在某一单独平面上重建的质量会下降很多。除此外,可以看出使用空白区域记录并跳过的机制(ESS)可以显著的减少渲染时间。
作者:Sida Peng, Yunzhi Yan 等
来源:CVPR 2023
论文题目:Representing Volumetric Videos as Dynamic MLP Maps
项目链接:https://zju3dv.github.io/mlp_maps/
内容整理:王秋文
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
