
随着机器学习(ML)技术的最新改进,特别是生成算法和大型语言模型的改进,越来越多的会议应用正在将这些功能添加到其产品中。
这种ML技术可在两个不同层面应用于会议应用:基础设施层面,改进媒体处理和传输;应用层面,为用户提供新特性或功能。
在基础设施层面(编解码器、噪声抑制等),大多数高层次的想法已在另一篇文章中介绍过。最近一些有趣的进展是将 “ML编解码器 “应用于音频冗余,下一个前沿领域是将生成算法也应用于视频,以及逼真化身的一般应用。
这篇文章重点介绍第二层(应用程序部分)以及如何实现典型功能,例如摘要、图像生成或审核。这里的想法是提出一个可用于实现这些服务的参考架构。
下面介绍的架构基于两个核心思想:
1. 该系统分为三个不同的子系统,它们具有不同的执行模式:
- 一种按需子系统,应用程序可以在需要时使用它来请求特定功能。
- 一种离线子系统,可在后台处理文件、事件和录音,以增强、过滤或提取相关信息。该系统有一个传统的存储桶作为后端(例如AWS S3)。
- 一种在线子系统,几乎实时处理所有通信事件(消息传递、信令、消息传递)以做出决策、提取信息或增强这些事件。该系统有一个流队列作为后端(fe Apache Kafka)。
2. 所有机器学习算法都暴露在 API/网关后面,以抽象实现细节以及与托管模型和外部提供商的接口。
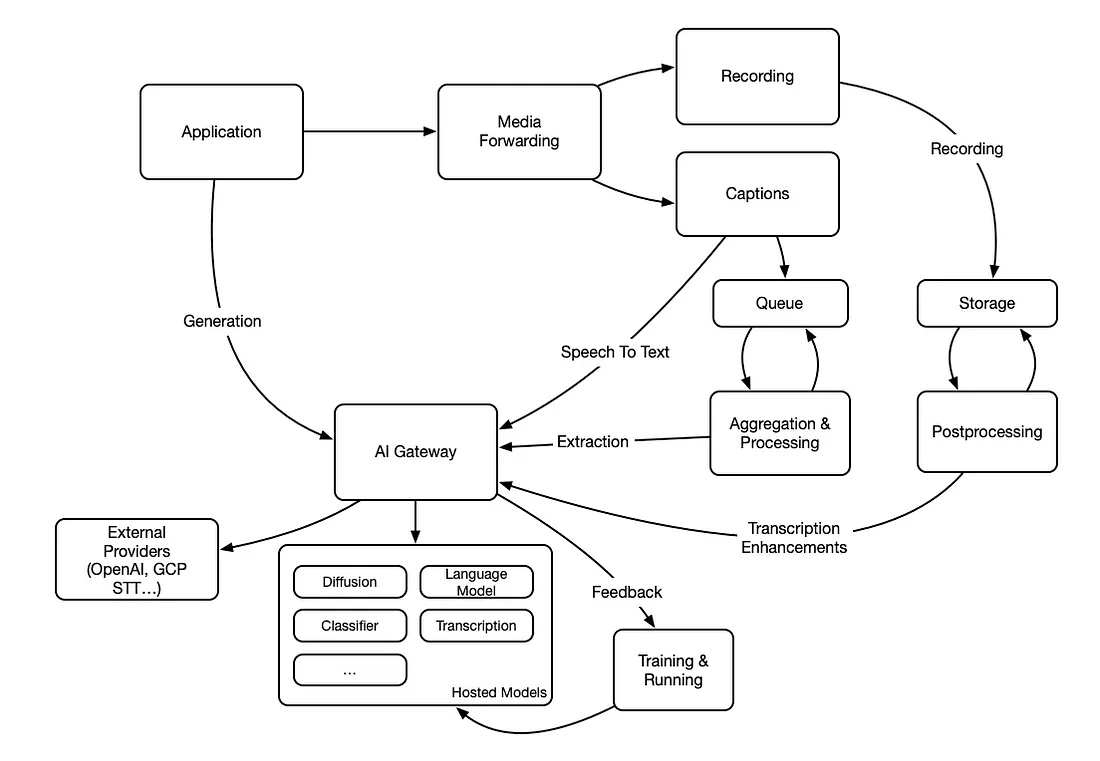
对于该架构,以下是一些典型功能以及如何实现它们:
- 媒体生成(图像、音乐、模因……)可以在用户请求时从应用程序请求,也可以在应用程序需要时自动生成。
- 增强的记录,例如使用典型的超分辨率算法,可以通过每次在存储桶中生成新记录时运行的后台后处理过程来生成。
- 从对话中实时提取相关字段(f.e Apache Kafka)可以通过从队列中读取字幕的过程来实现,按主题或发言人将它们分组,然后将这些块发送到 AI 网关。该信息可以反馈到队列,以便其他进程或应用程序可以使用它们。
这篇文章表达了我的个人观点,欢迎反馈。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/28844.html
