
随着抖音、快手、B站等视频平台的崛起,视频内容正占据着用户越来越多的时间。对于各个平台来说,内容视频化趋势明显。对于之家来说,也需要尽快完成在该赛道的技术工作。对于AIGC视频生成来说,对于视频的理解、分类是其中最为重要的算法环节,文本主要介绍多模态算法在AIGC-视频生成中的应用。
相关工作
在视频分类任务中,NeXtVLAD被证明是一种高效、快速的视频分类方法。受ResNeXt方法的启发,作者成功地将高维的视频特征向量分解为一组低维向量。该网络显着降低了之前 NetVLAD 网络的参数,但在特征聚合和大规模视频分类方面仍然取得了显着的性能。
RNN已被证明在对序列数据进行建模时表现出色。研究人员通常使用 RNN 对 CNN 网络难以捕获的视频中的时间信息进行建模。GRU是 RNN 架构的重要组成部分,可以避免梯度消失的问题。Attention-GRU指的是具有注意机制,有助于区分不同特征对当前预测的影响。
为了结合视频任务的空间特征和时间特征,后来又提出了双流CNN网络、3D-CNN网络、以及slowfast等。虽然这些模型在视频理解任务上也取得良好的表现,但还有提升的空间。比如,很多方法只正对单个模态,或者只对整个视频进行处理,没有输出细粒度的标签。
技术方案
1 整体网络结构
本技术方案是旨在充分学习视频多模态(文本、音频、图像)的语义特征,同时克服 youtube-8m数据集样本极不均衡和半监督的问题。如Figure 1所示,整个网络主要由前面混合多模态网络(mix-Multmodal Network)和后面的图卷积网络(GCN)组成。mix-Multmodal Network 由三个差异化的多模态分类网络构成,具体差异化参数在Table1中。
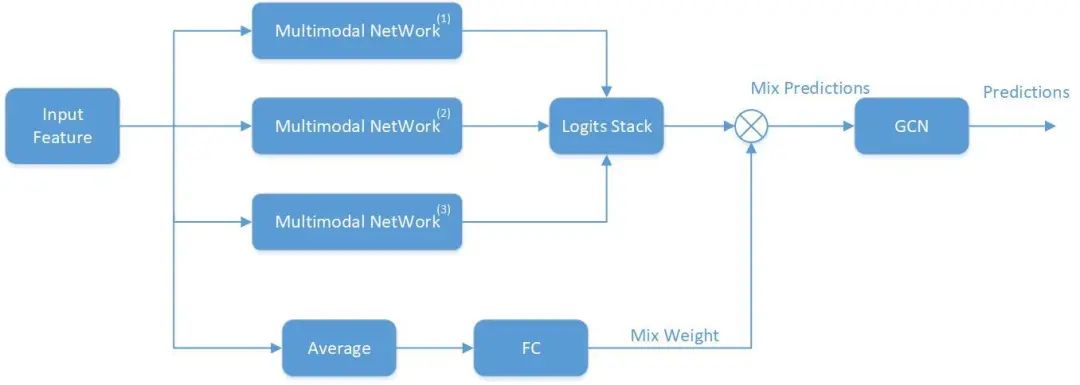
| Bert | NeXtVLAD | NeXtVLAD | |
|---|---|---|---|
| Layers | Cluster Size | Reduction | |
| Multimodal Net(1) | 12 | 136 | 16 |
| Multimodal Net(3) | 12 | 112 | 16 |
| Multimodal Net(3) | 6 | 112 | 8 |
2 多模态网
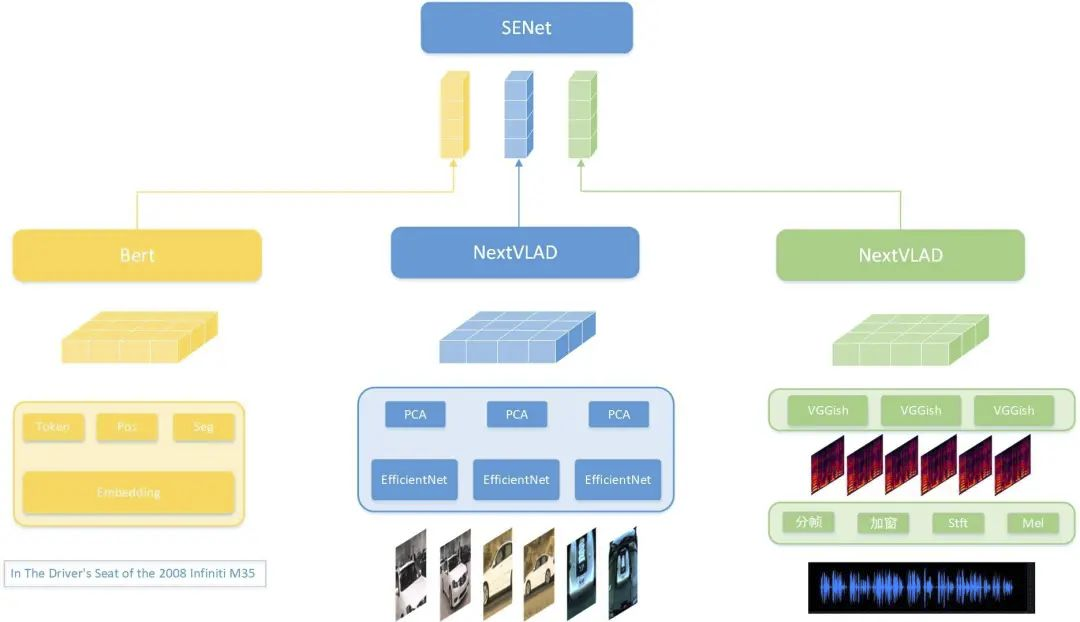
如图Figure 2所示,多模态网络主要理解三个模态(文本、视频、音频),每个模态都包含三个过程:基础语义理解、时序特征理解、模态融合。其中,视频和音频的时序特征理解模型是NextVLAD,而文本的时序特征理解模型为Bert。
多模态特征融合,我们采用的是SENet。SENet网络的前处理需要将各个模态的特征长度强行压缩对齐,这样会导致信息丢失。为了克服这个问题,我们采用了多Group的SENet的网络结构。实验表明,多个group的SENet网络相较于单个SENet 学习能力更强。
3 图卷积
由于youtube-8m粗粒度标签全部标注,细粒度标签只标注了部分数据。因此,引入 GCN来进行半监督分类任务。基本思想是通过在节点之间传播信息来更新节点表示。对于多标签视频分类任务,标签依赖关系是一个重要信息。我们使用标签之间的条件概率将标签相关信息引入我们的建模。基于Youtube-8M 数据集粗粒度标签,我们首先统计每个标签的出现次数,得到一个矩阵 N ∈ Rc。c是所有类别的数量。然后我们统计所有标签对的并发次数,这样就可以得到并发矩阵 M ∈ Rcxc。最终得到条件概率矩阵 P ∈ Rcxc :
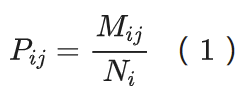
Pij表示标签 i 出现时标签 j 的出现概率。但是,来自训练和测试数据集的共现矩阵可能并不完全一致,数据集标签也不是 100% 正确。另一方面,一些罕见的共现对我们来说可能不是真正的关系,可能只是噪音。因此,我们可以使用阈值 γ 将 Pij 过滤到 P’ij:
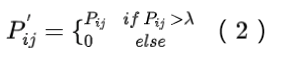
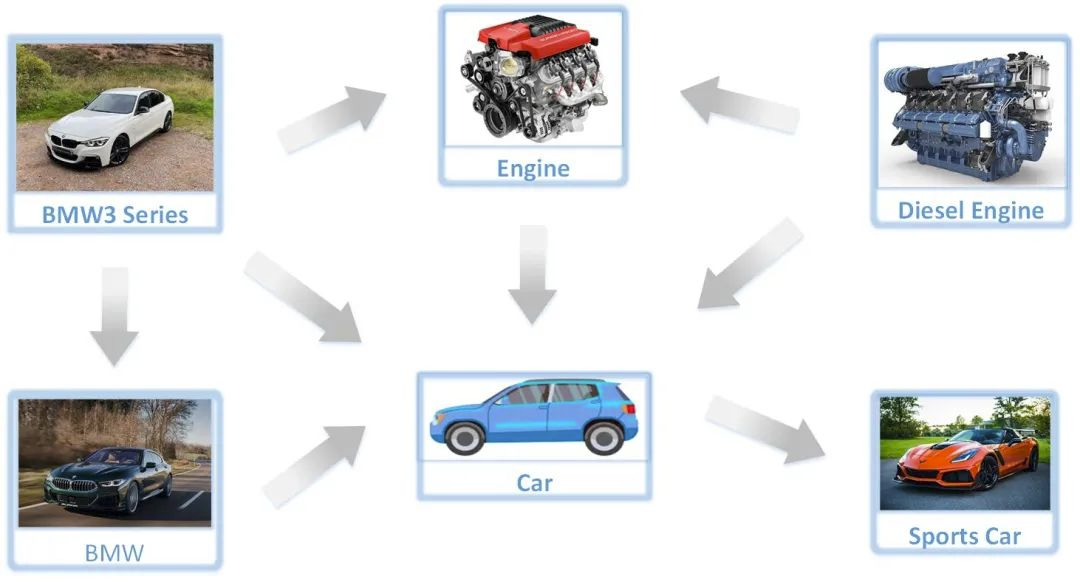
在我们的任务中,每个标签将是图(graph)的一个节点(node),两个节点之间的线表示它们的关系。所以我们可以训练一个矩阵来表示所有节点的关系。以从我们的数据集中提取的一个简化的标签相关图 Figure 3为例,Label BMW –> Label Car,表示当 BMW 标签出现时,Label Car 很可能发生,但反之则不一定。标签 Car 与所有其他标签具有高度相关性,没有箭头的标签表示这两个标签彼此没有关系。
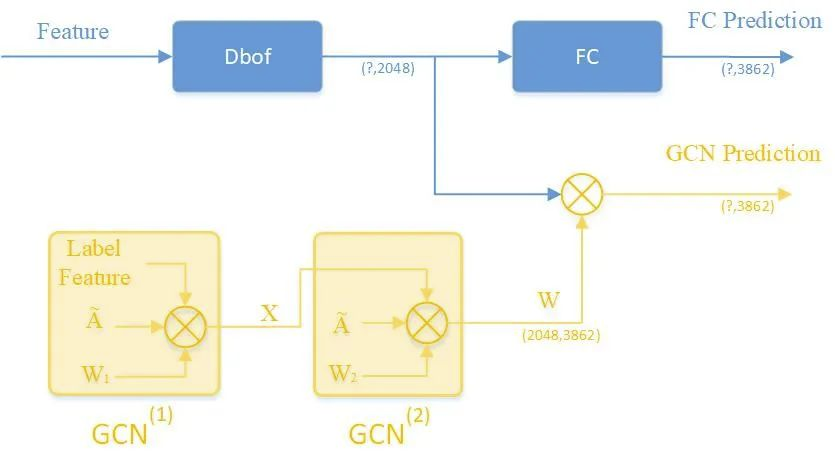
GCN网络实现如Figure 4所示。GCN模块由两层堆叠的GCN(GCN(1) 和 GCN(2))组成,它们有助于学习标签相关图,以将这些标签表示映射到一组相互依赖的分类器中。A 是输入相关矩阵,由矩阵 P‘ 的值初始化。W1 是将在网络中训练的矩阵。W2是GCN学习到的分类器权重。
4 标签重加权
Youtube-8M 视频分类任务是一个多标签分类任务,然而,注释数据仅选择多标签中的一个进行标注为1,其余标签均问0。也就是说,某一个视频片段除了可能是标注的还可能是其他置为0的标签。这个问题也是个弱监督问题。针对此情况,我们提出了一种解决方法。在计算损失时给带注释的类赋予较大的权重,并为未注释的类赋予较小的权重。这种加权交叉熵方法将帮助模型更好地从不完整的数据集中学习。原始二元交叉熵损失函数为:

n 是添加到未注释类的小权重, m 是已注释类的大值权重。
5 特征增强
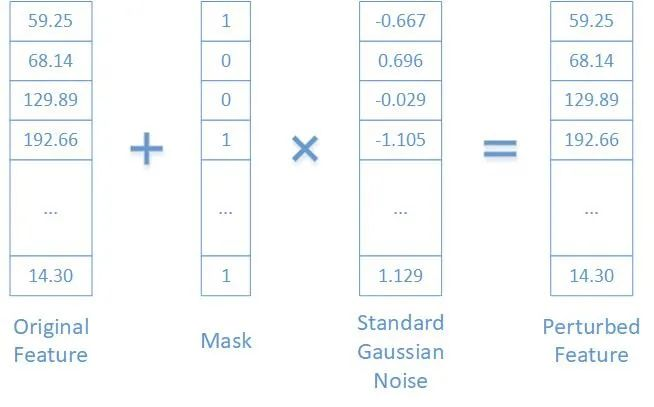
为了避免在训练模型时过拟合,我们添加了随机生成的高斯噪声并随机注入到输入特征向量的每个元素中。如图 5 所示,噪声将被添加到输入特征向量中,掩码向量随机选择 50% 的维度并将值设置为 1。这里的高斯噪声是独立的,但对于不同的输入向量具有相同的分布。
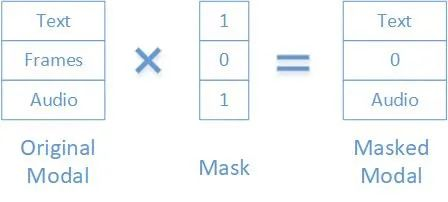
同时,为了避免多模态模型只学习某一个模态的特征,也就是在模态上过拟合。我们将模态特征也mask,保证输入中至少有某一个模态。这样就可以充分学习各个模态。
应用
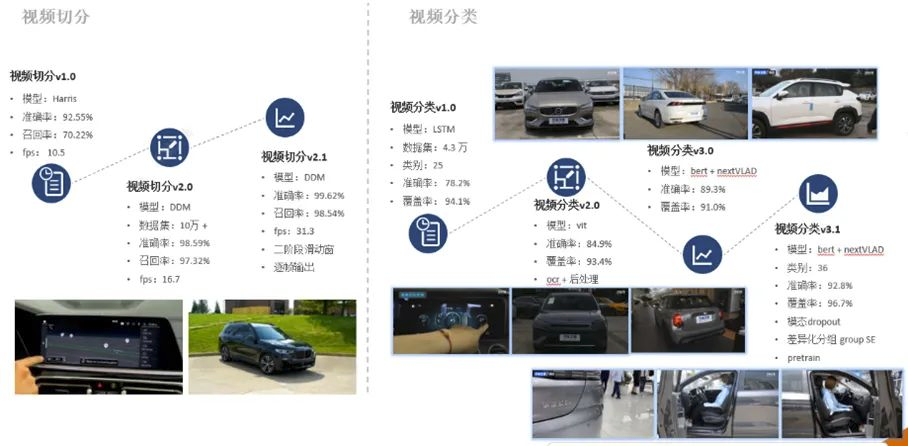
1 之家视频理解算法效果一览
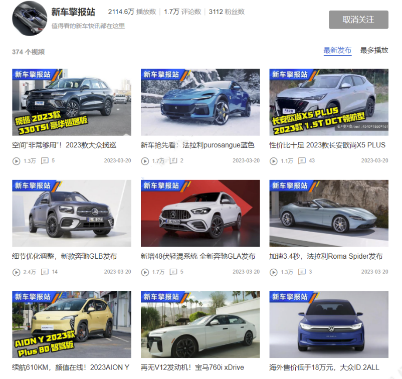
2 之家AIGC辅助视频生成应用效果
AIGC辅助视频生成当前共覆盖强车、弱车、数据类多个场景,具体类别如下:
- 强车类:新车擎报站、新车快报员
- 数据类:汽车排行榜
- 弱车类:玩的就是越野、交通事故集锦

作者简介
王磊
■ 智能推荐部-智能交互团队-视觉计算组
■ 汽车之家算法工程师;主要从事计算机视觉方向人工智能算法研究以及在之家落地应用
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
