
目前,能够分析视觉数据而不仅仅是存储数据的最先进的识别模型无一例外地基于深度学习。尽管在降低推理成本方面做出了巨大的努力,但它们对内存和计算的要求很高。而图像压缩对于促进在设备上存储捕获的数据以及减少远程存储所需的通道带宽和延迟至关重要。因此,在低延迟应用程序中使用最先进的视觉模型需要以压缩格式将数据传输到计算服务器,并且识别模型应该对可能通过压缩引入的伪影具有鲁棒性。
实验配置
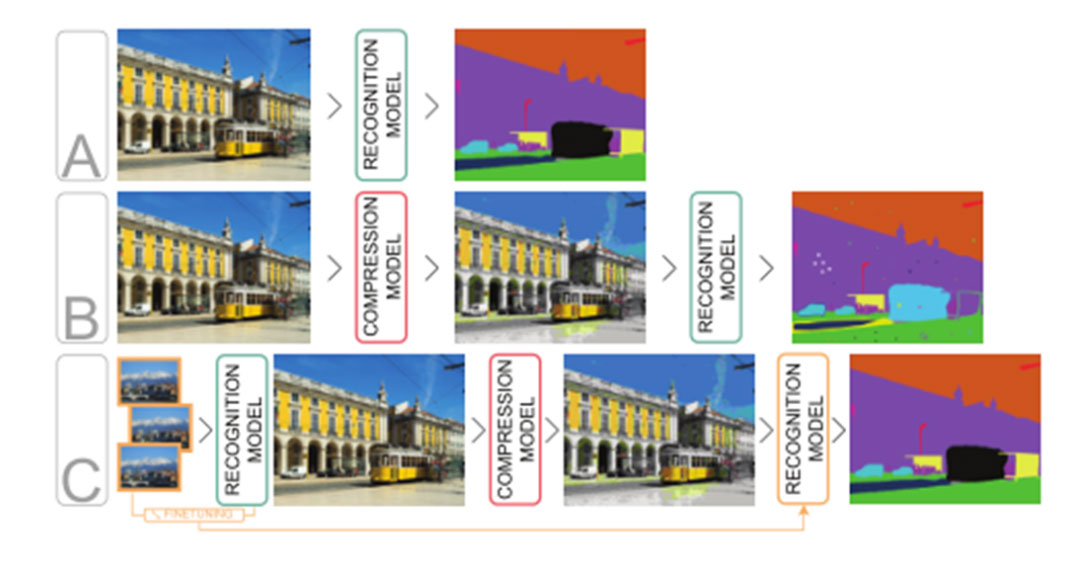
本文评估了通过最先进的传统以及神经网络编解码器进行图像压缩,对图像分类,目标检测和语义分割精度的影响。并探究了该影响在多大程度上是由于压缩图像中相关信息的丢失,或者是由于视觉识别模型对带有压缩伪像的图像缺乏泛化。
本文考虑了三个场景。在 A 中,识别模型在原始数据集图像上进行训练和评估,这是本文的参考基线。在 B 中,使用了 A 中的模型,但是评估了它在压缩图像上的性能。在 C 中,识别模型对压缩图像进行微调,然后以与选项 B 相同的方式进行测试。
具体配置如下:
- 图像分类模型为 Swin-T 主干+ MLP 头部,数据集为 ImageNet。
- 语义分割模型为 Swin-T 主干+ UPerNet 头部,数据集为 COCO。
- 目标检测模型为 ResNet-50 主干+ DDOD 头部,数据集为 ADE20K。
- 压缩编解码器选取了传统的 BPG,WebP,以及基于神经网络的均值和尺度(M&S)超先验模型,高斯混合模型(GMM)。
本文使用压缩版本的训练图像来微调模型,使模型适应压缩伪影,并消除输入数据中的原始域移位。模型微调使用与最初相同数量的微调迭代,以使预训练的骨干适应不同的任务。对于分类,模型微调了 30 次迭代,对于检测,模型微调了 12 次迭代,对于分割,模型微调了 160k 次迭代。本文针对每个压缩级别分别对模型进行微调。
为了排除额外训练的影响,对原始数据集上的基线模型也进行了微调,以获得相同数量的额外 epoch 。本文选择最好的评分模型(原始的或微调的)作为基线。对于分类和分割,对原始模型进行微调并没有提高准确率,而对于检测,对原始模型进行微调确实提高了准确率。
实验结果
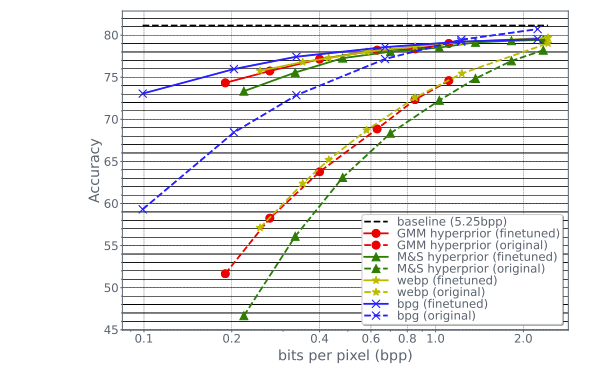
图像分类结果:当使用在原始图像上训练的基线模型(黑色虚线)进行分类时,使用 BPG 压缩图像对识别精度的影响最小,其次是 WebP 和 GMM 超先验,两者的影响相当。
在压缩图像(实体曲线)上对模型进行微调可以显著改善结果。例如,以 0.1 bpp 的码率将 BPG 压缩的准确率从 59.5% 提高到 73%,而原始图像的基线准确率为 81% (5.2 bpp)。这表明,在很大程度上,在压缩图像上进行测试时观察到的精度下降是由于原始模型对具有压缩伪影的图像缺乏泛化。经过微调后,在 1 bpp 时,所有压缩方法的精度都在 79% 左右;相对基线模型的损失为 3%,同时比特率降低了五分之一。
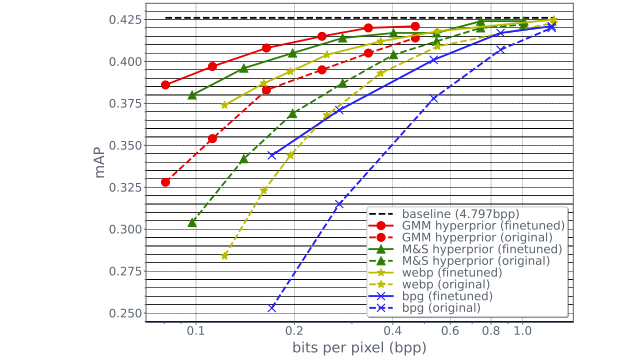
目标检测结果:COCO 数据集上的目标检测结果顺序有所不同。在这里,传统的编解码器 BPG 和 WebP 比神经压缩模型导致更大的精度下降。即使在压缩图像上进行微调,BPG (实蓝色)的结果也比在使用神经编解码器压缩的图像上使用原始模型(虚线绿色和红色)的结果更差。
与分类实验类似,通过在压缩图像上对模型进行微调,可以在很大程度上恢复目标检测精度的下降。例如,对于 0.1 bpp 的神经编解码器,mAP 中最初的 10 点或更多的下降减少到 5 点以下。在对 GMM 超先验模型进行微调后,在 0.4 bpp时,它能够将比特率降低 10 倍以上,而 mAP 仅比原始图像上的基线模型降低 0.5(从 42.5 到 42.0)。
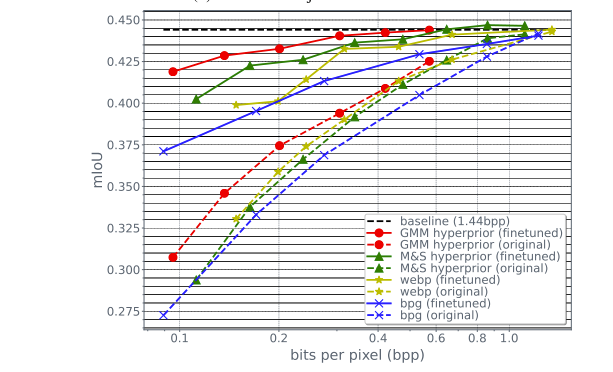
语义分割结果:与目标检测相似,BPG 压缩对准确性的影响最大,而 GMM 超先验压缩的影响最小。
当使用 GMM 超先验编解码器将图像压缩到 0.1 bpp 时,使用基线模型的 mIoU 为 31%,而微调模型的 mIoU 为 42%。相比之下,原始图像上的基线模型(1.44 bpp)获得 44.5%。在0.6 bpp 的情况下,优化模型在 GMM 超先验压缩图像上的 mIoU 与基线模型在原始图像上的性能相匹配。
这些结果表明:
- 强压缩对图像分类、目标检测和语义分割的准确性有很大的负面影响。
- 该影响在很大程度上是由于这些模型缺乏对具有压缩伪影的图像的泛化。
- 通过对识别模型的微调,压缩图像上的大部分准确率损失可以恢复。
意义
本文的发现有助于在资源和带宽有限的情况下为用户部署视觉识别。在未来的工作中,希望探索在互联网规模的数据集上训练视觉识别模型时,本文的发现可以用于减少 I/O 绑定延迟。特别是,探索直接在潜在压缩图像表示上训练识别模型,而不是通过通常的 RGB 表示。
来源:arxiv
论文链接:http://arxiv.org/abs/2304.04518
作者:Jo˜ao Maria Janeiro,Stanislav Frolov,Alaaeldin El-Nouby,Jakob Verbeek
内容整理:王妍
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
