
当前领先的视频目标分割(VOS)方法通常遵循一种基于匹配的机制:对于每一帧查询帧,根据它与之前处理过的和第一帧标注过的帧(即参考帧)的对应关系,推断出分割掩码。它们只是利用来自真值掩码的监督信号来学习掩码预测,而没有对时空对应匹配施加任何约束,然而,这却是这种机制的基本构件。为了缓解这个关键而常被忽视的问题,我们设计了一种对应感知的训练框架,它通过在网络学习过程中显式地鼓励稳健的对应匹配,来提升基于匹配的VOS方法的性能。通过全面地探索视频中像素和对象层面的内在一致性,我们的算法将无标签、对比式的对应学习与标准的、完全监督的掩码分割训练相结合。在不需要额外的标注成本、不影响部署速度、不引入架构修改的情况下,我们的算法在四个广泛使用的基准数据集上,即DAVIS2016&2017和YouTube-VOS2018&2019,基于著名的基于匹配的VOS方法,提供了可观的性能提升。本项工作由上海交通大学图像通信研究所和浙江大学王文冠老师团队合作完成。
论文题目:Boosting Video Object Segmentation via Space-time Correspondence Learning
来源:CVPR 2023
作者:Yurong Zhang, Liulei Li, Wenguan Wang, Rong Xie, Li Song, Wenjun Zhang
论文地址:https://arxiv.org/abs/2304.06211.pdf
内容整理:张育荣
介绍
在这项工作中,我们解决了视频对象分割(VOS)的任务。给定一个输入视频,其中第一帧有真值目标掩码,VOS的目标是准确地分割后续帧中的注释对象。作为计算机视觉中最具挑战性的任务之一,VOS 有利于广泛的应用,包括增强现实和交互式视频编辑。
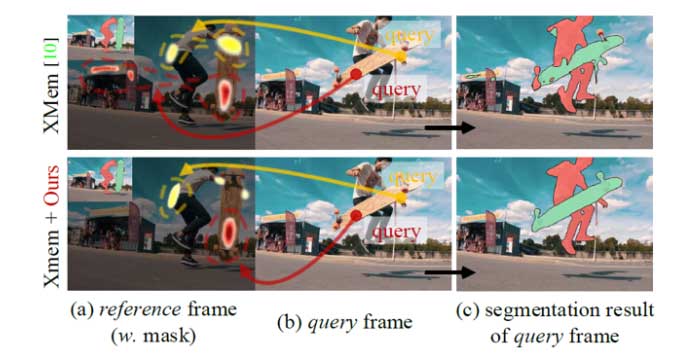
现代VOS解决方案是建立在完全监督的深度学习技术之上的,而最优秀的解决方案大多遵循一种基于匹配的范式,即根据查询帧和先前分割以及首次标注的帧(即参考帧)之间的相关性,生成新到来帧(即查询帧)的对象掩码,这些参考帧存储在外部内存中。因此,很明显,用于跨帧匹配(即时空对应建模)的模块在这些先进的VOS系统中起着核心作用。然而,这些基于匹配的解决方案只是在真实分割掩码的直接监督下进行训练。换句话说,在训练过程中,整个VOS系统纯粹是针对准确的分割掩码预测进行优化,而没有考虑到中心组件——时空对应匹配的任何显式约束/正则化。这就引发了一个关于次优性能的合理担忧,因为在网络学习过程中没有任何可靠的保证真正建立可靠的跨帧对应关系。上图(a)为这一观点提供了一个视觉证据。XMem,最新的基于匹配的VOS解决方案,往往在发现有效的时空对应关系方面存在困难;事实上,一些背景像素/块被错误地认为与查询前景高度相关。
上述讨论激发我们提出了一个新的,时空对应感知的训练框架,它以一种优雅和有针对性的方式解决了现有基于匹配的VOS解决方案的弱点。核心思想是通过从训练视频序列的固有时空连续性中挖掘互补而免费的监督信号,使基于匹配的解决方案具有更强的对应匹配的鲁棒性。更详细地说,我们全面研究了视频在像素和对象层面上的一致性特性:i) 像素级一致性:时空上接近的像素/块往往是一致的;ii) 对象级一致性:不同时间步下相同对象实例的视觉语义往往保持不变。通过将这两个属性适应于一个无监督学习方案,我们给对应匹配过程提供了更明确的指导,从而促进VOS模型学习密集的、有区别性的和对象一致的视觉表示,以实现鲁棒的、基于匹配的掩码跟踪。
值得一提的是,除了提高分割性能,我们的时空对应感知训练框架还具有几个引人注目的方面。首先,我们的算法用时空对应的自我训练来补充基于匹配的VOS的标准、完全监督的训练范式。因此,它不会造成任何额外的标注负担。其次,我们的算法与当前流行的基于匹配的VOS解决方案完全兼容,无需对分割网络架构进行特别的适应。这是因为对应匹配的学习只发生在视觉嵌入空间中。第三,作为一个训练框架,我们的算法在部署阶段不会给应用的VOS模型带来额外的计算预算。
这篇文章的主要贡献有:
- 我们揭示了当前基于匹配的VOS方法在时空对应学习方面的局限性。作为回应,我们提倡一个新的训练框架,它用相关性关联的自我训练来补充基于匹配的掩码跟踪的监督学习。
- 我们在一个对比对应学习方案中,探索了视频序列在像素和对象层面上的内在连续性,这可以轻松地融入到先进的、基于匹配的VOS解决方案中。
- 当应用到现有的基于匹配的VOS方法时,我们的算法既不增加额外的标签成本,也不造成速度延迟,也不需要修改架构,而是提供稳定和丰富的性能提升,实现了对应学习在VOS中的补充作用。
方法
问题设定
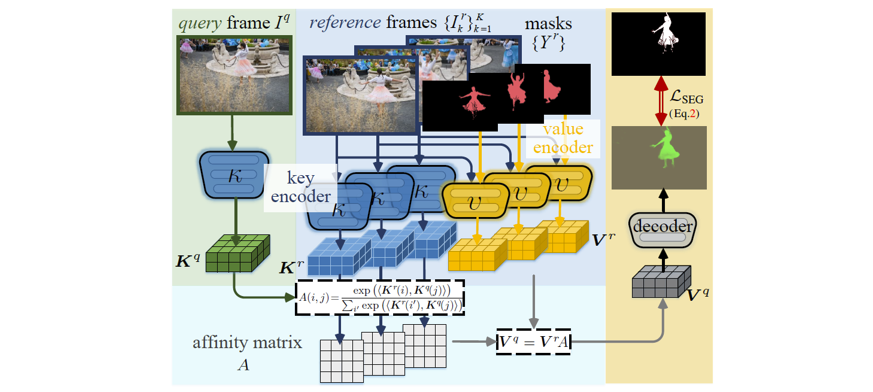
以 NeurIPS2021 文章 STCN 为例讲基于匹配的视频目标分割方法。给定一段视频序列和第一帧的掩码,按照帧序处理视频并且维护特征记忆存储。当前帧为查询帧,通过键编码器得到其键特征 KQ,将它与记忆存储中的多个键 KM 进行比较,然后用键亲和力矩阵从记忆中检索回对应的值特征 vM(同样有多个,这里的多个既包含了多个键对应的 值也包含一个键对应的多个值)。STCN 有两种编码器: 键编码器和值编码器,前者以当前时刻的 RGB 图像作为输入,后者在字面上也是以前一时刻的RGB图像和各个物体对应的掩码作为输入,但是有很大差别,值编码器所使用的前一时刻的 RGB 图像的键特征,然后再接收各个物体的掩码,产生每个掩码对应的值,也就是说每个图像对应于其中的任何一个物体掩码,它的键特征 都是同一个,这一帧里有多少个物体,就会有多少个 值,但是只有一个键特征,而且这个键特征是上一时刻里键编码器 已经编码得到的,不用再次编码,所以对每个图像只用计算一次 key 特征,键特征的计算并不依赖于掩码。值编码器会先对掩码进行特征抽取,然后将键特征和掩码特征进行简单的融合,将 融合的结果通过两个残差块和一个 CBAM 块,才会产生最终的值特征。从上面这个过程也可以很明显的看出来键特征的计算不依赖于掩码。这样的原因在于相关性应该是直接在帧与帧之间产生的,而不应该引入掩码作为干扰。从另一个角度来说,这样的设计其实是使用了 Siamese 结构,而这个被广泛用于在 few-shot learning 中计算键特征。
对于给定的 T 帧记忆帧和当前帧查询帧,在特征提取阶段会生成如下内容:KQ、KM 和 vM。首先计算关联矩阵,而后进行 softmax 操作得到亲和力矩阵 。通过
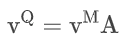
得到查询帧的读出特征,经解码器解码之后得到对应帧的掩码。
时空对应感知训练
亲和力矩阵 A 给出了查询帧 Iq 和存储的参考帧 Ir 之间所有像素对之间的相关性强度。因此,本质上是在查询和内存之间进行对应匹配(尽管在所有参考帧上进行了归一化),并且计算出的亲和力 A 作为最终掩码解码的基础。然而,大多数现有的基于匹配的 VOS 模型只是通过最小化标准的、监督的分割损失 LSEG来进行训练。因此,在训练过程中,对应匹配组件只能访问隐含的、分割导向的监督信号,而缺乏对跨帧相关性估计——A的显式约束/正则化。这可能会增加过拟合和次优性能的风险。注意到时空对应在基于匹配的 VOS 中的关键作用以及标准训练策略在这一背景下的不足,我们因此寻求用某种对应感知的训练目标来补充分割指定的学习目标 LSEG。然而,由于遮挡和自由形式的对象变形,获取真实视频的时空对应注释几乎是不可能的。这进一步激发了我们探索视频内在一致性作为对应匹配的免费监督来源。所产生的结果是一个强大的训练框架,它通过无标注的对应学习来增强基于匹配的VOS模型。基本上说,我们在一个对比对应学习方案中,全面地探索了视频序列在像素和对象粒度上的一致性特性。我们的框架如下图所示。该框架由两个组成部分构成:像素级对应学习和对象级对应学习。

基于像素级别连续性的对应学习

基于目标级别连续性的对应学习
通过在我们的框架中实现像素级一致性特性,我们激发基于匹配的 VOS模型学习局部有区别性的特征,从而构建视频帧之间可靠的、密集的对应关系。为了实现全面的鲁棒匹配,我们进一步在对象级上研究视频的内容连续性——同一个对象实例的表示应该在帧之间保持稳定。通过强制关键编码器 k 学习对象级紧凑和有区别性的表示,我们能够提高对应匹配对变形和遮挡造成的局部干扰的鲁棒性,并更好地解决 VOS 任务的对象感知特性。简单地说,我们在自动发现和预标注的视频对象上应用对比对应学习;对象级的时空对应是通过最大化不同时间步下同一对象实例的表示之间的相似度来学习的。
通过强制关键编码器学习对象级紧凑和有区别性的表示,我们可以更好地解决 VOS 任务的对象感知特性。简单地说,我们在自动发现和预标注的视频对象上应用对比对应学习;对象级的时空对应是通过最大化不同时间步下同一对象实例的表示之间的相似度来学习的。通过将正对象对与负对象对进行对比,不同视频帧中相同对象实例的特征被迫对齐。相应的目标级别对比损失为:
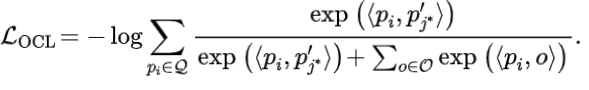
实验结果
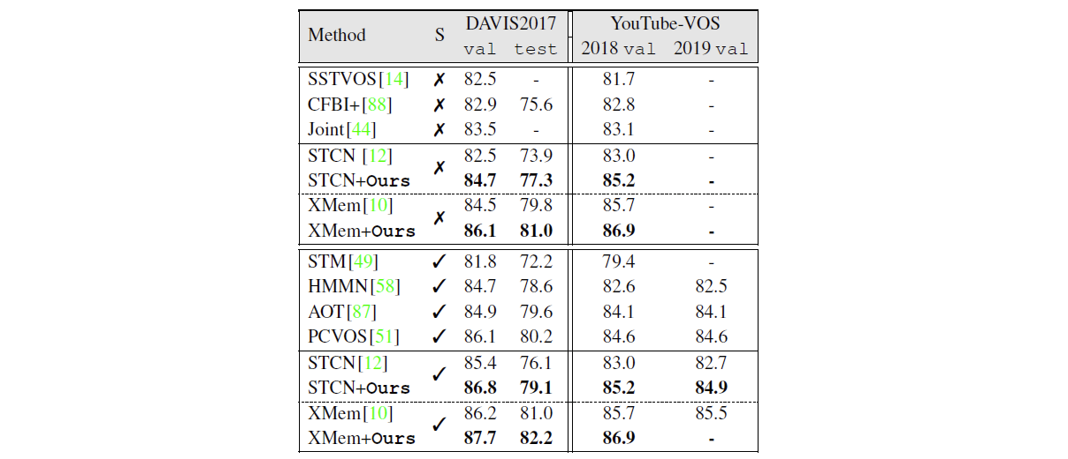
以基于匹配的视频目标分割算法 STCN 和 XMem 作为基线方法,我们的方法相比于基线取得了显著的提升,并且基于 XMem 的方法在 VOS 任务的多个数据集上达到了 SOTA。
同时,如下图所示,对应关系的可视化表明,我们的方法减少了错误的匹配。

我们方法的视觉效果如下图所示。可以看出,我们的策略显著提高了视频目标分割的准确的,并且在一些较难的场景中也具备稳定的分割效果。

总结
我们提出了一种对应感知的训练框架,它通过在网络学习过程中显式地鼓励稳健的时空对应匹配,来提升基于匹配的VOS方法的性能。我们的算法通过全面地探索视频中像素和对象层面的内在一致性,将无标签、对比式的对应学习与标准的、完全监督的掩码分割训练相结合。我们的算法在不需要额外的标注成本、不影响部署速度、不引入架构修改的情况下,在四个广泛使用的基准数据集上,基于著名的基于匹配的VOS方法,提供了可观的性能提升。未来,我们计划将我们的对应感知训练框架扩展到其他基于匹配或跟踪的视频分析任务中。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
