

随着信息技术的发展,多媒体数据的大小呈现指数级增长,视频数据的传输如今已经占据了超过80%的网络带宽。在基于深度学习的图像压缩方法展现出优越的率失真性能的同时,开发基于深度学习的视频压缩方法也成为研究者不断探索的方向。
但是不同于图像压缩,基于深度学习的视频压缩方法仍然遇到了很多困难。传统视频编解码器经过数十年的发展,变得越来越复杂,而其中对于性能很重要的一环就是帧间预测,目前的深度视频压缩方法尽管有朝着多种实用场景做出各种改进,但是仍然在最基础的应用场景(low-delay-P)下很难取得与传统编码器在PSNR相媲美的性能。本文就是从帧间预测的角度出发,研究如何使得视频编码器在只利用上一个重建帧的情况下,压缩下一帧(即P帧)性能得到全面提升。该论文发表于IEEE Transaction on Image Processing.
【内容提供】郭宗昱
【单位】中国科学技术大学智能媒体计算实验室
【论文链接】https://arxiv.org/abs/2112.13309v2
方法描述
1.方法总览
我们采用了混合编码架构(hybrid coding framework)来进行视频压缩,即先通过编码运动信息,然后编码残差信息来将P帧编码为两部分码流。在之前采用混合编码架构的方法中,最早的DVC [1] 直接采用预训练的光流网络来联调实现P帧压缩,之后的方法比如SSF [2] 采用gaussian blur的方式来对图像进行多尺度特征提取作为预测源,实现了自适应根据不同特征来预测P帧,再之后的工作FVC [3] 采用特征层面预测的方式,借鉴了deformable convolution的思想,将运动信息又卷积的offset来表示,进一步提升了性能。在DVC之后的这些方法都是对预测部分进行了改进,我们的方法也采用类似的架构,对帧间预测做到了尽可能好,如下图所示:
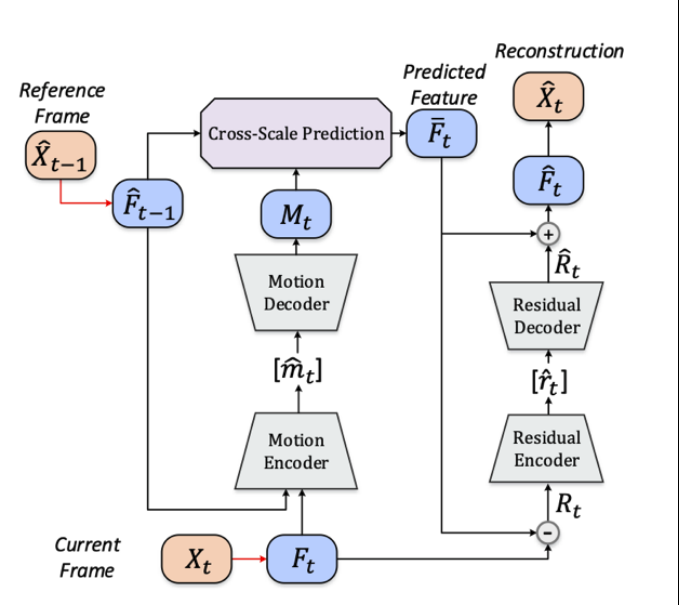
同时传统视频编码方法的发展历史也启发我们,视频的帧间预测对于编码性能及其重要,所以我们在本文着重提出了Cross-scale prediction的模块(上图的紫色模块),以一种加权预测的方式,在率失真准则下对运动信息进行了非常有效的建模。
2. 跨尺度加权帧间预测
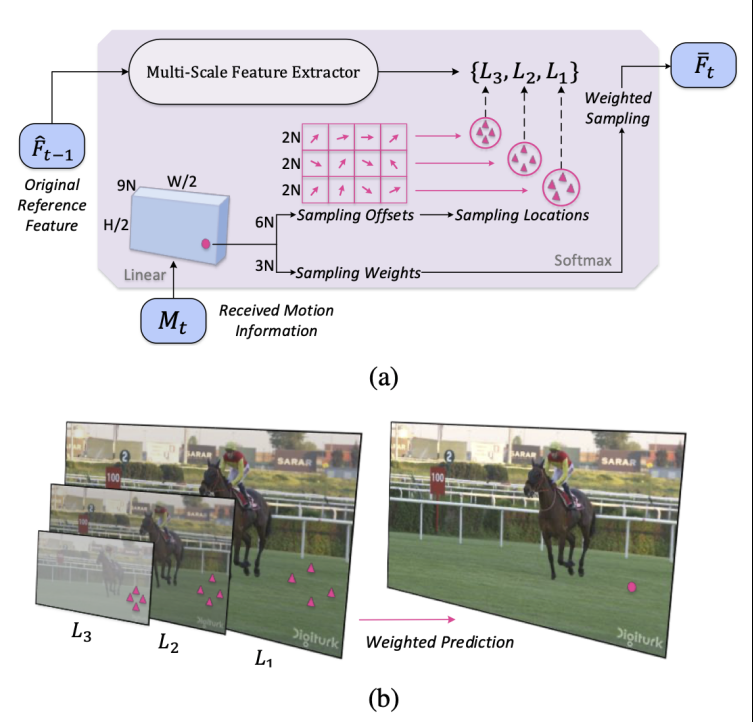
我们提出了跨尺度加权帧家预测的方法,首先利用多尺度特征学习得到的参考帧信息作为预测源,然后来用weight map不同尺度参考特征到下一帧的重要程度,比如对于运动剧烈的部分,那么低分辨率的更加偏语义层面的特征就更具有参考意义,对于运动平缓的区域,那么高分辨率的具有更加细粒度纹理的特征就更具有参考意义。
对于编码任务而言,最重要的是通过尽可能少的比特让解码端解码出更加高质量的图片/视频等信号,我们通过将这里的weight map隐式的传输到运动信息中,在解码端可以通过motion decoder解码出各个特征尺度上的importance map,尽管可能motion information可能会少量增加,整体的码率却由于残差部分的码率显著减小而得到了减少。在解码器端解码出importance map和各个尺度offset的module如下图(a)所示,当前编码帧如何利用参考帧的各级参考特征来加权预测的示意图如下图(b)所示:
3.用于视频编码的先软后硬量化
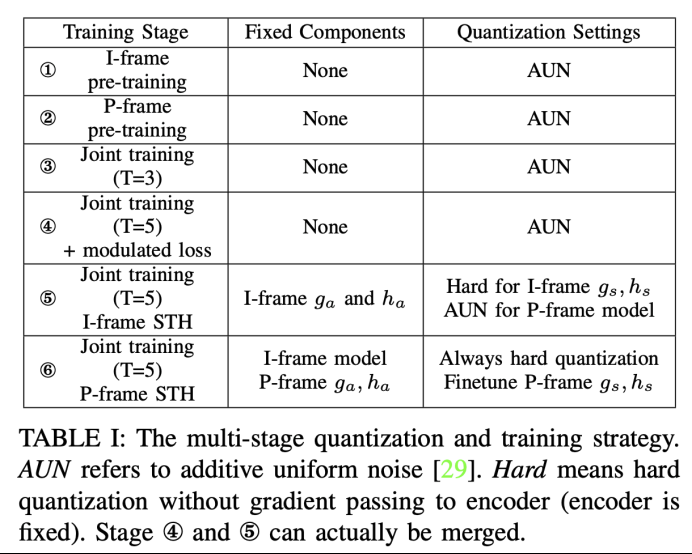
在我们提出的跨尺度加权模块之外,我们还提出了video版本的soft then hard量化策略,来减小训练和测试时learned based codec在量化部分遇到的不一致的问题。由于基于深度学习的视频编码通常在最后需要联调I-frame codec和P-frame code,所以很难直接利用image版本的soft then hard [4]。所以我们在不同训练阶段采用了不同的量化方法,提升了最终编码性能。
4.精细训练
结合上面所提到的量化策略,我们同时还采用了modulated loss来减小视频编码的误差传播问题,采用的多步训练方法对于提升编码性能和维持训练稳定性非常重要。完整的训练策略如下表所示。
实验和分析
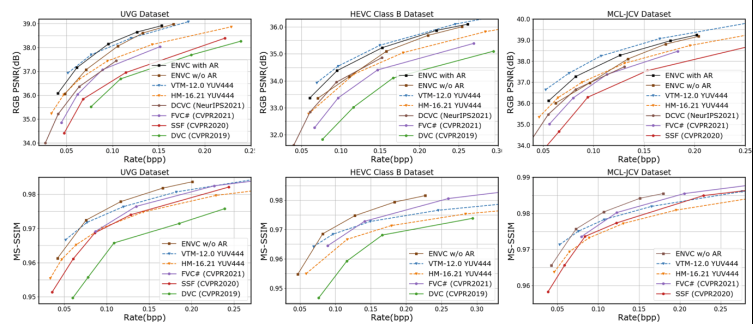
我们在本文做了非常细致的实验和分析来验证我们方法的有效性。首先在测试集分别为UVG、HEVC Class B 和MCL-JCV数据集上,如下图所示我们的方法(称为ENVC, Efficient Neural Video Codec)在无论是PSNR优化下还是MS-SSIM优化下都达到了SOTA的性能,并且比之前的方法DVC [1]、SSF [2]、FVC [3]等好了很多。
同时我们通过在解码端对importance map解码结果的可视化,验证了我们设计跨尺度加权预测的动机,如下图所示,可以看到在运动剧烈的区域(比如中间手的部分),最低分辨率的参考特征的importance map响应非常大(total weight map at scale-3 在手的部分weight接近1为白色),而在运动比较平缓或者规律的区域(比如背景部分),total weight map at scale-1响应会更大一些。

我们还在本文进行了详细的ablation study,比如在充分公平的比较条件下,与之前帧间预测的方法的比较,这里我们将之前的方法用尽可能好的方式进行了增强,称为DVC++, SSF++, FVC++,但是可以看到我们提出的ENVC仍然对性能有着显著的提高。
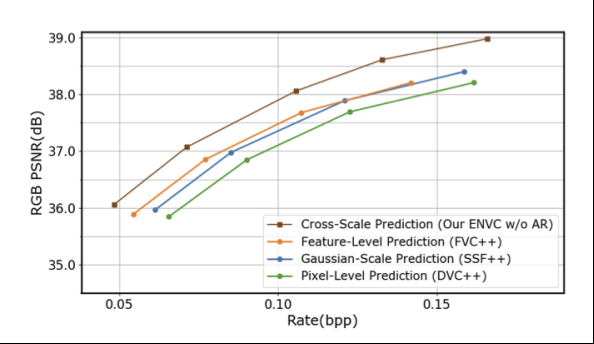
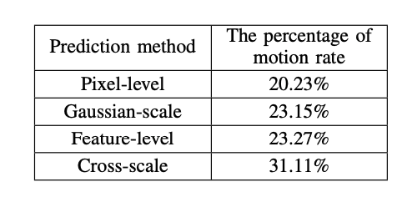
还有一组非常有趣的分析性的实验说明,我们提出的跨尺度加权预测的方法通过在帧间预测阶段,引入灵活高效的加权机制并将其作为运动信息的一部分,可以提高motion information在整体码流中的占比,也就是说残差部分的码流大大降低。这也印证了我们提出的方法能够更加智能的将参考帧和当前帧之间的相关性提取出来。
文章总结
我们在本文提出了跨尺度加权帧间预测的方法,并配合video-version soft-then-hard和惊喜的训练策略,可以在UVG dataset上达到超过H.266 low delay P的PSNR性能,在当时论文初稿完成的2021年末,该性能可以说是超过了之前的所有方法,实现了性能的飞跃。我们提出的跨尺度帧间预测的方法可以拓展到其他编码场景,比如双向视频编码,或者单向多参考帧编码,我们将代码已经开源(https://github.com/USTC-IMCL/ENVC), 欢迎大家提出宝贵的建议!
References:
[1] DVC: An End-to-end Deep Video Compression Framework. Lu et al., CVPR 2019.
[2] Scale-space flow for end-to-end optimized video compression. Agustsson et al., CVPR 2020.
[3] FVC: A New Framework towards Deep Video Compression in Feature Space. Hu et al., CVPR 2021.
[4] Soft the Hard: Rethinking the Quantization in Neural Image Compression. Guo et al., ICML 2021.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
