
视频质量评价在过去十年中受到了很多关注。它在控制视频通信的质量方面发挥着非常重要的作用。视频质量评价有两个应用场景:专门的视频流(professional video streaming)和用户生成的内容( user generate content)。专门的视频流有高质量的视频流作为参考,可以衡量压缩后的视频质量。用户产生的内容(如社交媒体,对话视频)通常没有高质量视频作为参考,我们必须再没有任何参考的情况下进行质量评价,也就是所谓的盲质量评价。对于专门视频,作者在南加州的团队和 Netflix 在 2014-1015 年进行合作,开发了视频多方法评估融合技术(Video Multi-Method Assessment Fusion),并获得了 2020 年的技术工程艾美奖。因此作者受 Meta 工程师邀请,从事用户生成内容质量评价的研究。
主讲人:DR. C.-C. JAY KUO
来源:RTC @Scale 2023
演讲题目:Green Blind Visual Quality Assessment for Real-Time Communications
内容整理:李江龙
视频地址:https://atscaleconference.com/videos/blind-quality-assessment-for-real-time-visual-communications/
对于用户生成的视频和视频通话进行盲质量评价,主要有三个挑战:
- 没有可用的参考
- 用户端为移动设备,计算资源有限。
- 视频通话场景对延迟要求很严格。
为了克服这些挑战,我们需要一个轻量级的机器学习模型来做质量评价。
盲图像质量评价
首先我们需要数据集,我们不仅需要获得广泛的具有不同质量的图像,还需要获得用户标签,以便用户打分。
提出 Green learnin method
现有实现盲图像质量评价的机器学习方法有两种。第一种是传统方法,从图像中提取特征,然后对之做机器学习,这种方法需要手工标注特征,并且缺少用户生成视频的表示方法。第二种方法是深度学习,这需要在海量数据上预训练的模型,并且模型复杂度太高,延迟不可接受。就性能而言,深度学习方法比传统方案能提供更好的预测结果。一方面,我们希望有比深度学习方法轻量很多的算法,另一方面,我们希望能得到较好的性能,因此,我们现在在传统方法和深度学习方法中间的位置,这是一个很有挑战性的工作。作者提出了 Green learning method,具有以下优势:
- 没有反向传播的轻量模型
- 低延迟
- 对计算资源要求小
- 可接受的性能
模型实现
作者提出的模型流水线包括两个阶段。第一阶段是无监督,不需要用户标签。我们只是试图从图像中自动获得特征,所以我们不使用手工制作的特征,我们使用某种非常强大的工具来寻找这些特征,然后我们可以选择一个特征子集,一个更有鉴别力的子集,与回归目标更相关。然后第二部分,我们做特征选择,使用监督,同时我们使用通道回归器来预测分数。
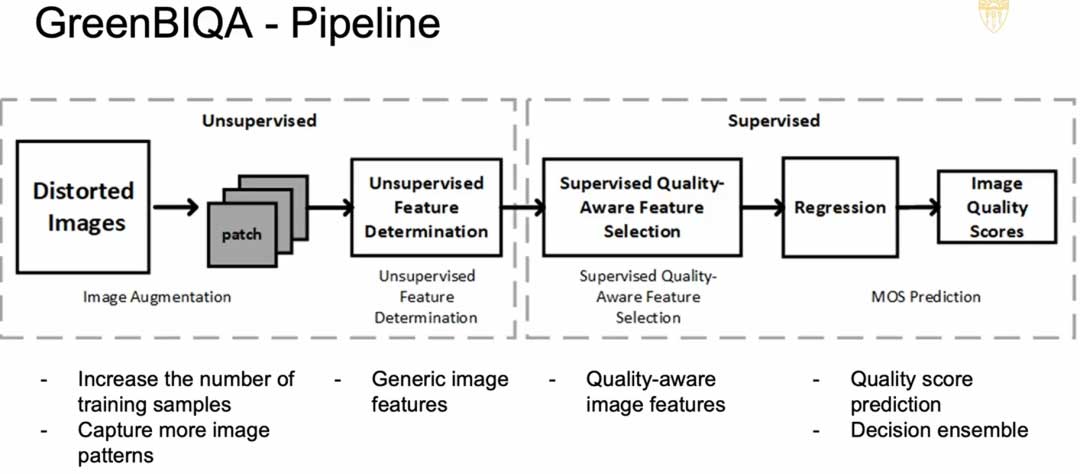
对于特征选择,我们考虑两个阶段。第一阶段是广泛用于压缩的离散余弦变换。因此,对于每个局部图像块我们都有一个DC 和 AC 系数,这给你一些小窗口的纹理的感觉。然后,我们把 DC 系数放在一起,然后进入第二级 DCT 变换,这给你对整个图像的整体感觉。然后我们还有第二个阶段。我们有 DC 和 AC 系数。所以这些都是作为候选的特征。
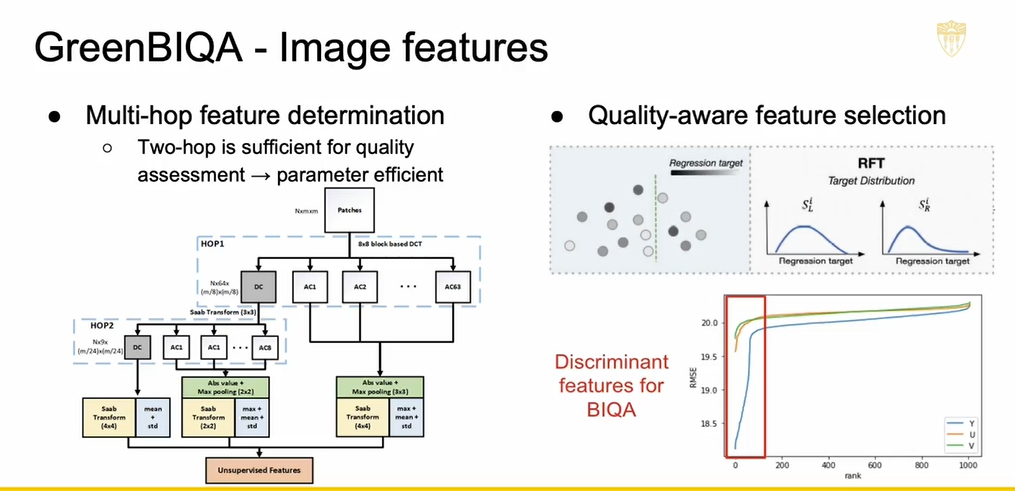
在图 2 的右边,我们可以检查每个特征的判别能力,所以我们有了从最小到最大的特征。然后我们,我们尝试在最小和最大之间的不同位置进行分区。然后每个分区,我们可以找到左右两个流行平面。我们使用左边的平均值,右边的平均值,作为预测值。我们可以计算出均方误差,然后把它们加在一起。我们希望均方误差是尽可能地小。因此,对于每个特征维度,我们选择一个具有最小均方误差的分区,这将是该特征的损失函数。我们有很多特征,如图 2 右下方所示。我们把所有的名字从最小的均方误差从低到高排序。然后我们选择那些具有较低均方误差的特征。这些被称为判别性特征。所以我们选择这些特征并进行回归。
预测结果
这里展示了四张图片,我们要求用户给每张图片贴上 1 到 5 的标签,从最差到最好。然后我们对这些分数进行平均,多个用户得分的平均值被称为每个图像的平均意见得分。在这里我用四张图片来显示平均意见得分。左边两张是较好的图像。第三张是鹿,得分很高,右边一张是灯塔的图像,可以看出质量很差,它的平均意见得分很低。

对于左边的两幅图像,我们有非常好的预测结果。它非常接近用户的主要意见得分,右边两张是更具挑战性的情况。第三张是鹿的图片,预测结果比用户的评价偏低。因为算法在图片背景中看到了很多东西,并且很模糊,所以模型觉得这些图片质量可能不高。但实际上在这种情况下,用户真正关注的是鹿,而不是背景,所以用户觉得这张图片质量很高。最右边那张图片,模型预测的分数很低,但没有用户的平均意见分数那么低。这些都是很特殊的情况,我们仍然需要解决它。
性能基准
用于比较的测试的数据集是LIVE-Challenge 和 KonIQ-10k。衡量标准是 SROCC 和 PLCC,这两个指标用来说明预测结果和人类打分的相关性的。这两个指标,通常是小于 1 的值,越大越好,为 1 时表示完全匹配。
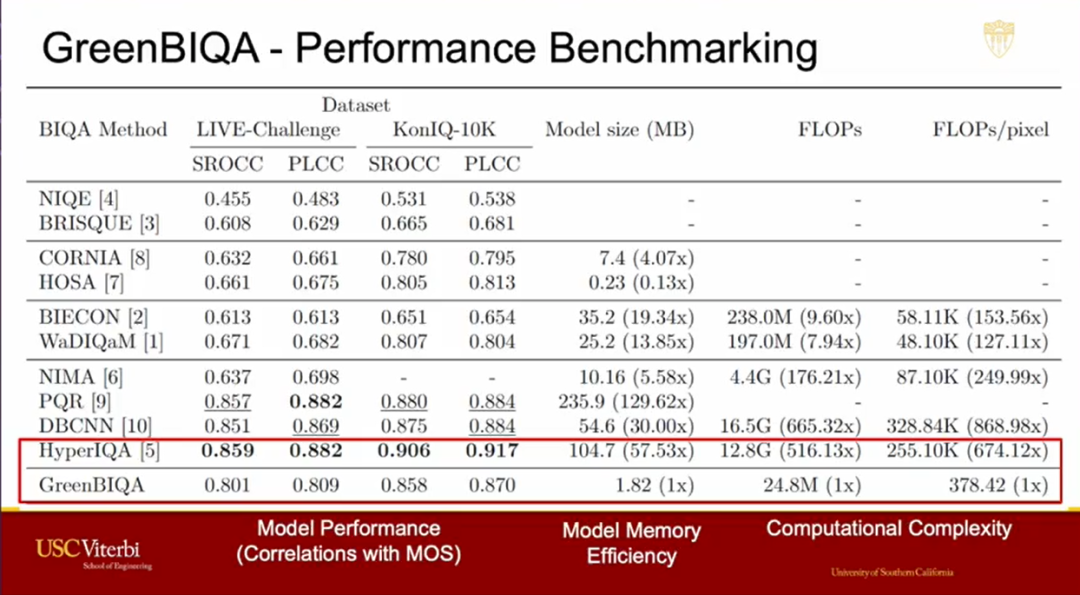
我们可以看到 HyperIQA 在两个数据集上的表现都是最好的,将我们提出的 GreenBIQA 与之进行对比可以看到,各个性能指标都减少了0.05左右。但是模型轻量化了 57 倍,浮点数计算量缩小了 516 倍,单像素的浮点数计算量缩小了 674 倍。这表明,我们提出的模型牺牲了一部分性能,但能应用于实时通信 RTC 中。
盲视频质量评价
模型框架
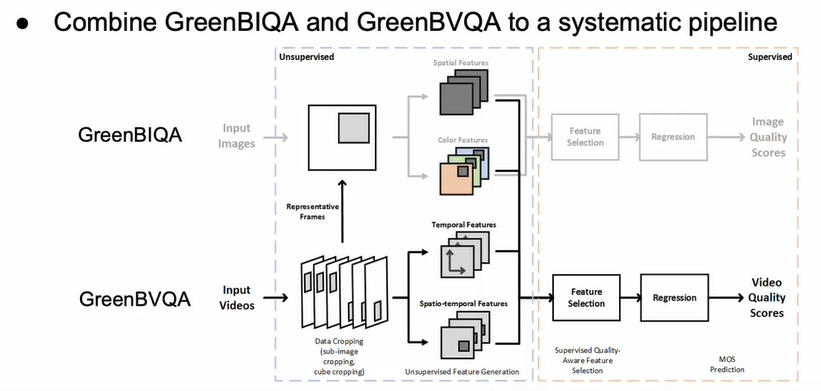
接下来我们在盲图像质量评估的基础上做了盲视频质量评价,但我们也想纳入时间信息,所以我们裁剪出一些小立方体。所以包括空间和时间的三维立方体,然后从这个三维立方体中提取特征,这样我们就能得到一组丰富的特征。然后我们用我前面介绍的技术选择最相关的一个,然后把它们拟合到回归器中。
预测结果
这里有四个视频序列。上面的两个视频质量是在中间范围。左下方的视频有非常高的分数4.0,这是一个在某种背景前的猫的图像。而背景是模糊的。右下角是一个音乐会,分辨率和视频的质量都不好。

从图 6 可以看到前两个视频的预测得分和人类平均意见得分非常接近,这是一个很好的案例。而左下方的视频,我们低估了分数,因为它的背景是模糊的,所以背景的质量并不好。但在这种情况下,人类更关注猫的视频质量,而不关心背景,所以人类的分数和机器的分数之间存在差距。对于第四个视频序列,人类打分更低,即使我们预测了低分,但没有人类标签那么低。所以这是一个高估的情况。这是因为第四种视频内容比较少,机器学习不能对这种视频进行高准确度的质量预测。
性能基准
测试使用的数据集为 LIVE-VQC 和 KoNViD-1k,性能指标为 SROCC和 PLCC。我们给出了两个版本的 GreenBVQA 模型,分别是 Normal 和 Fast。Normal 模型使用了所有特征和基于聚类的方法,Fast 模型只使用了时空特征。
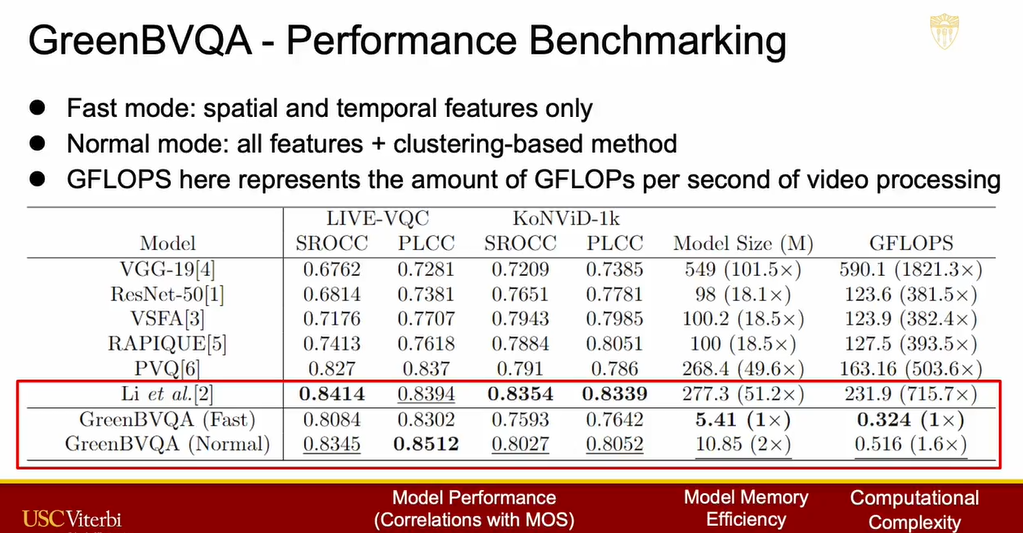
现有方法中表现最好的是 Li 等人提出的方法,从图 7 可以看出我们的方法中 Fast 版本比 SOAT 方法模型轻量了 51 倍,计算复杂度降低了715倍,并且性能指标是可接受的。Normal 版本模型轻量化了 25 倍,计算复杂度降低了 400 倍,并且性能只是略有下降。
结论
我们的工作是对用户产生的内容以及多方对话视频进行视频质量评估,在这里,我们展示了一个可应用于实时通信的真正可行的解决方案。这项工作的挑战在于没有参考,所以只能依靠机器学习技术。你需要一个非常有效的特征提取,以及有效的回归器。我们提出了 GreenBIQA、GreenBVQA,它们在与人类经验的相关性方面可以达到第一梯队的表现。和深度学习相比,它的模型大小要小得多。深度学习方法的模型大小是我们的 50倍,计算复杂度是我们的 500倍甚至更多。在未来,我们还有更多的工作要做。我认为一个具有挑战性的问题是:根据少量的标签数据预测广泛的视觉内容。因此,我们期待推动这项技术继续发展。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
