
本文提出了一个针对自由视点视频(FVV)的端到端无参考视频质量评估(NRVQA)模型,旨在通过不同的特征采样和提取方法,基于空域和时域特征共同预测视频质量得分。相较于以往的深度视频质量评估方法,该评估方法同时考虑了时空域失真,具备了更加全面的评估能力。实验结果显示,与现有的 SOTA 方法相比,该模型在 Youku-FVV 数据集上 的 PLCC 和 SRCC 分别提高了 25.0% 和 18.5%。此外,消融实验表明,空域特征和时域运动特征都对提高模型的评估能力起到了重要的作用。
论文标题:Quality of Experience Assessment for Free-viewpoint Video
发表会议:BMSB 2023
作者:Rongli Jia, Yuhong Zhang, Jun Xu, Li Song, Wenjun Zhang, Lin Li and Yanan Feng
本项工作为“上海交通大学电子系 Medialab 实验室 – 中国移动咪咕公司”的合作研究成果。
引言
背景
近年来,自由视点视频(FVV)的发展引起了视频行业的广泛关注。FVV是一种新型视频内容,允许观众自由选择观看位置和角度,提供更加沉浸式的观看体验。目前,FVV技术已成功应用于现场体育赛事和游戏广播等领域。为了提高系统生产效率和改善用户体验,需要针对用户端 FVV 设计有效的视频质量评估模型,及时为系统提供反馈。
传统的 VQA 方法主要分为三类,即全参考(FR)、半参考(RR)和无参考(NR)质量评估方法。对于 FVV,由于没有无损源视频可供参考,因此只能使用无参考质量评估方法进行评估。与传统的 VQA 场景相比,FVV的质量评估面临更多挑战。
挑战
针对 FVV 视频做质量评价,面临的挑战主要包括以下三个方面。
首先,FVV 的失真类型多样。由于合成算法存在深度图不准确和图像 inpainting 不完美等问题,合成的 FVV 中可能包含物体扭曲、拉伸、空洞和模糊区域等失真情况 [1]。如图 1 所示。此外,在时域中,时间不一致性和闪烁也会降低FVV的质量 [2]。
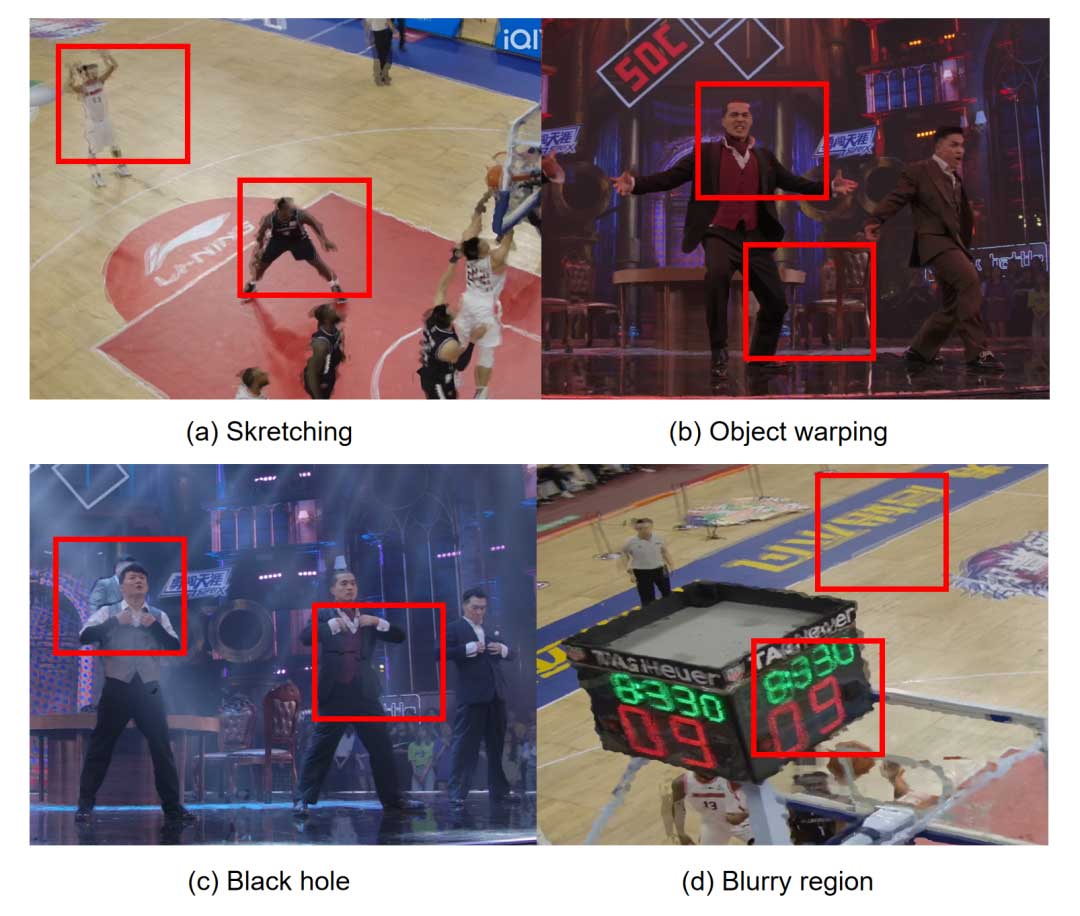
其次,现有的质量评估方法不适用于 FVV。传统的图像和视频质量评估方法主要关注图像/视频的全局失真,而基于 DIBR 生成的 FVV 视频的主要失真是局部失真,传统的 IQA/VQA 方法已经不再适用于评估 FVV 合成视图质量,例如 pixel-based 的 IQA 方法对深度图高频失真更为敏感,因此可能会对高频失真过度惩罚 [3]。
最后,FVV质量数据集的数量和规模都较小。目前已有的FVV质量数据集数量有限,因此利用有限的数据学习可靠的质量表示也是难点之一。
本文贡献
为了解决上述挑战,本文提出了一种端到端的、基于深度学习的无参考视频质量评估方法。主要贡献包括以下几点:
- 提出了一种综合考虑空域和时域失真的FVV质量评估方法。
- 通过使用预训练的图像分类模型和无监督学习方法解决了FVV质量数据集小的问题,学习到了可靠的质量感知特征表示。
- 在FVV质量评估数据集上取得了比其他方法更好的表现。
方法
图 2 展示了本文数据预处理和模型训练的pipeline。具体来说,数据预处理部分,针对空域特征和时域特征不同的特点,选择采用不同的采样方式来尽可能的保留质量感知特征;模型训练部分,选用了预训练的图像分类模型和无监督学习方法,在有限数据中学习可靠的质量感知表示;最后,通过分数融合模块,将空域和时域分数融合,得到最终结果。
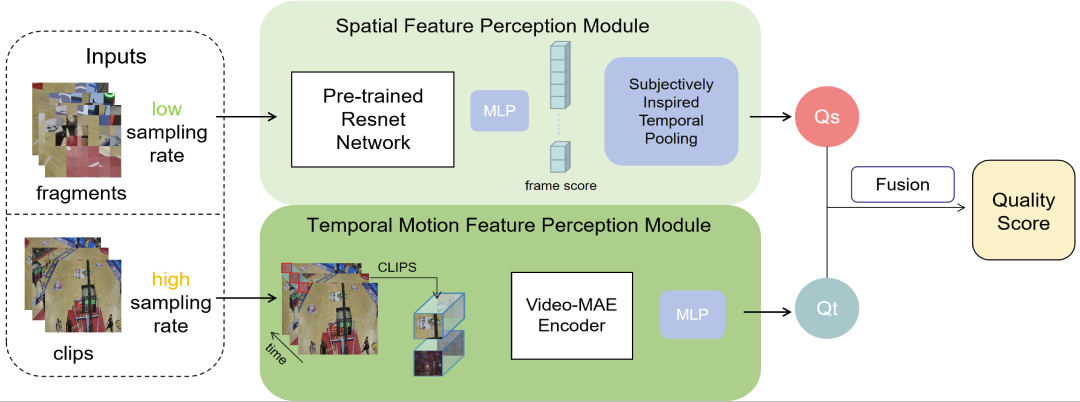
空域特征提取
空域特征对于帧采样率不敏感,因此可以采用一个较低的帧采样率进行采样,从而加速训练和推理的速度。帧图像处理部分,由于 resize 和 crop 都会对空域特征产生影响,因此对所有帧进行 fragments [4] 采样,与之不同的是,我们通过固定每一个 grid 中采样 mini-patch 的位置,省去了时域对齐和邻近位置编码的操作,简化了空域特征提取的流程。
之后,利用在 ImageNet 上预训练的 ResNet50 网络对每一个 fragments 进行特征提取,并利用 MLP 进行特征回归,每一帧得到一个帧级分数 qk 。
得到每一帧的帧级分数后,参考人类感知系统(HVS)对于画面质量的记忆特点,进行主观启发的时间池化:
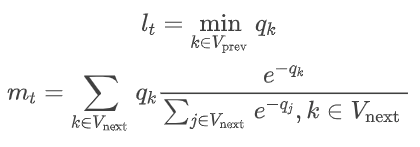
多个帧级分数整合结果为空域质量分数 Qs。
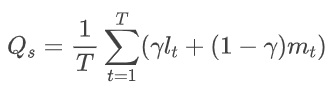
时域运动特征提取
时域特征对于帧采样率敏感,更关注帧内物体的运动状况,因此需要采用一个较高的帧采样率进行采样。为了保留完成的运动信息,我们采用对每一帧进行简单 resize 和 center-crop 的方式,保留帧内完整的运动情况。
考虑到时域运动特征的复杂性以及数据集规模的限制,我们采用了自监督学习方法 Video-MAE [5] 进行特征提取的训练,我们使用在Kinetics-400上预训练的 VideoMAE 编码器部分提取运动特征,以提高特征的表达能力和泛化能力。最后通过 MLP 将时域运动特征整合为一个时域运动分数。
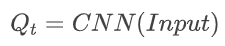
分数融合
最后,通过分数融合模块将 Qs 和 Qt 进行线性加权融合,以得到最终的 FVV 质量评分。
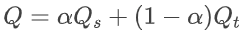
实验结果
实验设置
我们在 Youku-FVV 数据集上进行了实验,该数据集是目前可用于评估 FVV-QoE 的最大数据集之一,包括娱乐和体育两种真实场景。数据集采用了Tanimoto等人提出的视图合成方法 [6],并使用 H.264 和 H.265 压缩方法,对视频进行了六个不同的量化参数(QP)范围内的压缩,以保证数据集的多样性。此外,数据集还包括三种不同的导航扫描路径和三种不同的视角切换速度,以进一步增加数据集的多样性。Youku-FVV数据集共包含1944个视频。
具体的实验中,我们将 Youku-FVV 数据集 8:2 随机划分为训练集和测试集。对于空域特征感知模块,我们从每个 FVV 中以隔 15 帧间隔的采样率共采样16帧,然后通过 7×7 的 grid 在中心裁剪 32×32 pixel 的 mini-patches。这 49 个 mini-patches 被拼接在一起,形成 224×224 pixel 的 fragments。对于时域运动特征感知模块,我们从每个 FVV 中隔 8 帧采样共16帧,每帧通过 resize 和 crop 调整大小为224×224 piexl的图像。
训练时,初始学习率为0.0001,训练 batchsize 大小为4,共训练100个epoch。训练中采用均方误差(MSE)作为损失函数来计算训练损失。
结果对比
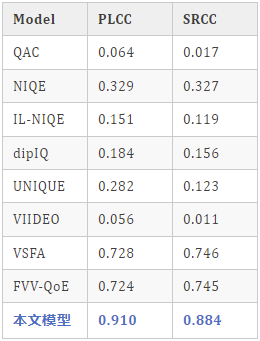
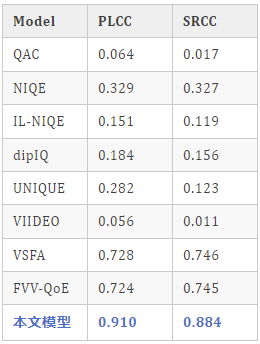
我们使用Pearson线性相关系数(PLCC)和Spearman秩相关系数(SRCC)这两个指标来评估VQA模型的性能。最终的性能通过10次实验并取其中位数来确定。可以看到我们提出的方法在预测性能上显著优于其他方法。
消融实验
在消融实验部分,我们研究了所提出模型中两个重要模块的影响:空间特征感知模块和时间运动特征感知模块。下表展示了我们仅基于空间和时域运动特征模块来评估FVV的质量的结果。从表中看出,这两个模块都对于整体的性能提升有着重要的作用。
总结
本文提出了一种端到端的模型,用于评估自由视点视频的质量。在空域特征感知模块中,我们通过低采样率和 GMS 处理输入的 FVV,然后使用在ImageNet 上预训练过的 Resnet-50 提取空间特征。在感知时域运动特征的模块中,我们使用高采样率和调整大小和裁剪操作处理输入的 FVV,然后使用在 Kinetics-400 上预训练的 VideoMAE 编码器部分提取运动特征。两个模块的特征使用两个 MLP 块进行回归,分别得到空域质量分数和时域运动质量分数。然后使用分数融合模块对两个分数进行线性融合,以生成与MOS高度一致的预测结果。根据实验结果,我们的模型优于其他无参考 IQA/VQA 方法。我们还进行了消融实验,验证了模型各组件的设计。实验结果表明本文提出的方法能够更准确地评估FVV的质量,具有更好的应用价值。
参考文献
- J. Yan, J. Li, Y. Fang, Z. Che, X. Xia, and Y. Liu, “Subjective and objective quality of experience of free viewpoint videos,” IEEE Transactions on Image Processing, 2022.
- H. G. Kim and Y. M. Ro, “Measurement of critical temporal incon- sistency for quality assessment of synthesized video,” in 2016 IEEE International Conference on Image Processing (ICIP). IEEE, 2016, pp. 1027–1031.
- S. Tian, L. Zhang, W. Zou, X. Li, T. Su, L. Morin, and O. Deforges, “Quality assessment of dibr-synthesized views: An overview,” Neuro- computing, vol. 423, pp. 158–178, 2021.
- H.Wu,C.Chen,J.Hou,L.Liao,A.Wang,W.Sun,Q.Yan,andW.Lin, “Fast-vqa: Efficient end-to-end video quality assessment with fragment sampling,” in European Conference on Computer Vision. Springer, 2022, pp. 538–55
- Z. Tong, Y. Song, J. Wang, and L. Wang, “Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training,” arXiv preprint arXiv:2203.12602, 2022.
- M. Tanimoto, T. Fujii, K. Suzuki, N. Fukushima, and Y. Mori, “Reference softwares for depth estimation and view synthesis,” ISO/IEC JTC1/SC29/WG11 MPEG, vol. 20081, no. 4, 2008.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
